一个网站的首页包括什么wordpress发消息
CS5260测试版|CS5260demoboard|typec转VGA参考PCB原理图
CS5260是一款高度集成的TYPEC转VGA转换方案芯片。
CS5260输出端接口:外接高清VGA设备如:显示器投影机电视带高清的设备,广泛应用于 笔记本Macbook Air 12寸USB3.1输出端对外接高清VGA设备如:显示器投影机电视带高清VGA信号的外接设备。
CS5260芯片支持两个DisplayPort具有数据速率的主链路输入运行速度为1.62Gb/s、2.7Gb/s,可以接受RGB数字格式,18位6:6:6或24位8:8:8。VGA输出可以支持WUXGA(1920*1200@RB)@60赫兹。
CS5260主要应用于:

CS5260参数特性:
CS5260 Type-C输入特性:
USB Type-C TM 显示端口替代模式输入(接收器)
作为标准的USB Type-C显示端口Alt模式接收器,CS5260由双通道主链路差分对,一个AUX通道差分对组成。
主链接
双通道差分对,能够运行HBR2(5.4-Gbps),HBR (2.7-Gbps)数据速率,以实现高清无压缩视频传输。主链路完全符合 DisplayPort v1.4 规范。
辅助通道
差分半双工双向通道,用于 DisplayPort 源和接收器设备之间的边带通信。此链路的带宽高达 1 Mbps。
CS5260 CC通道特性
配置通道用于检测USB端口的连接,例如,源到接收器。
在两个连接的端口之间建立数据角色。
发现并配置可选的备用模式和附件模式。
CS5260 模拟VGA输出特性:
CS5260集成了三路8位-210MHz-DAC(数字到模拟转换器),每个DAC分别分配每种颜色,R(红色)G(绿色)和B(蓝色)。CS5260 的模拟 VGA 接口与 VESA VSIS v1r2 兼容。实时热插拔检测机制也集成到CS5260中。
CS5260支持的最流行的视频格式如下表4-1所示。
但是,CS5260支持的格式不限于此表 。
CS5260 也可以支持那些 (a) 数据传输带宽低于 2 通道 DisplayPort HBR2 主链路的最大带宽和 (b) 像素频率低于最大 DAC 速度 210-MHz 的格式。

表 4-1 支持的常用时序/分辨率
CS5260 设计TYPEC转VGA转换方案优势在于:
1.CS5260VGA 输出接口,DAC 速度高达 210-MHz,8 位
2.CS5260支持所有 USB Type-C通道配置 (CC)
3.CS5260 其中2LAN 2.7GMax.分辨率高达 1920x1200@60Hz(RB,减少消隐),24 位色深,1920X1440(RB,减少消隐),18 位色深,或 2048x1152@60Hz(RB,减少消隐)24 位色深,或2048x1536@60Hz(RB,减少消隐),18 位色深。
4.CS5260嵌入式振荡器或外部晶体可选
5.CS5260嵌入式线性压差稳压器 (LDO)
6.CS5260嵌入式单片机
7.CS5260嵌入式EDID(如果终端设备没有EDID,CS5260将响应EDID)
8.CS5260 嵌入式V同步/H同步5V缓冲器
综上所示:CS5260芯片集成度较高,外围器件较少,设计较为简单,整体方案BOM成本较低,单芯片成本比市场其他方案芯片要低,是一款不错的方案选择。
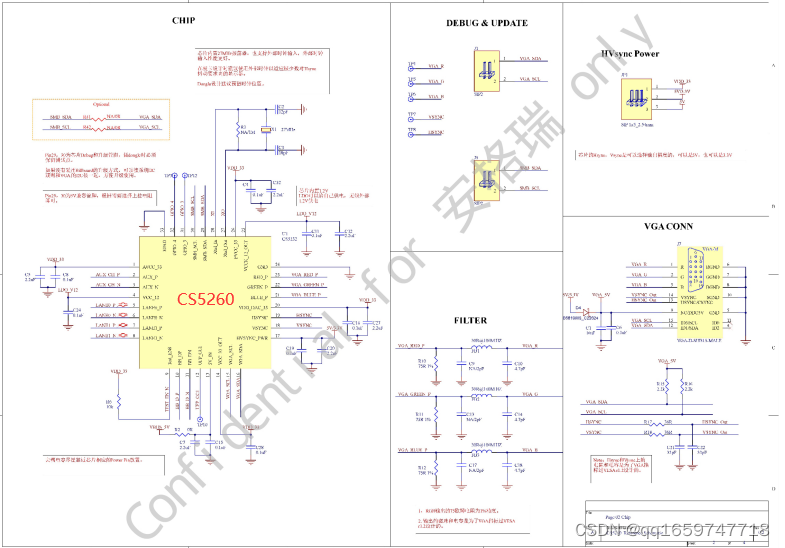
CS5260设计Type-C转VGA转换器或者Typc-C转VGA转接线测试版或者demoboard板如下所示:

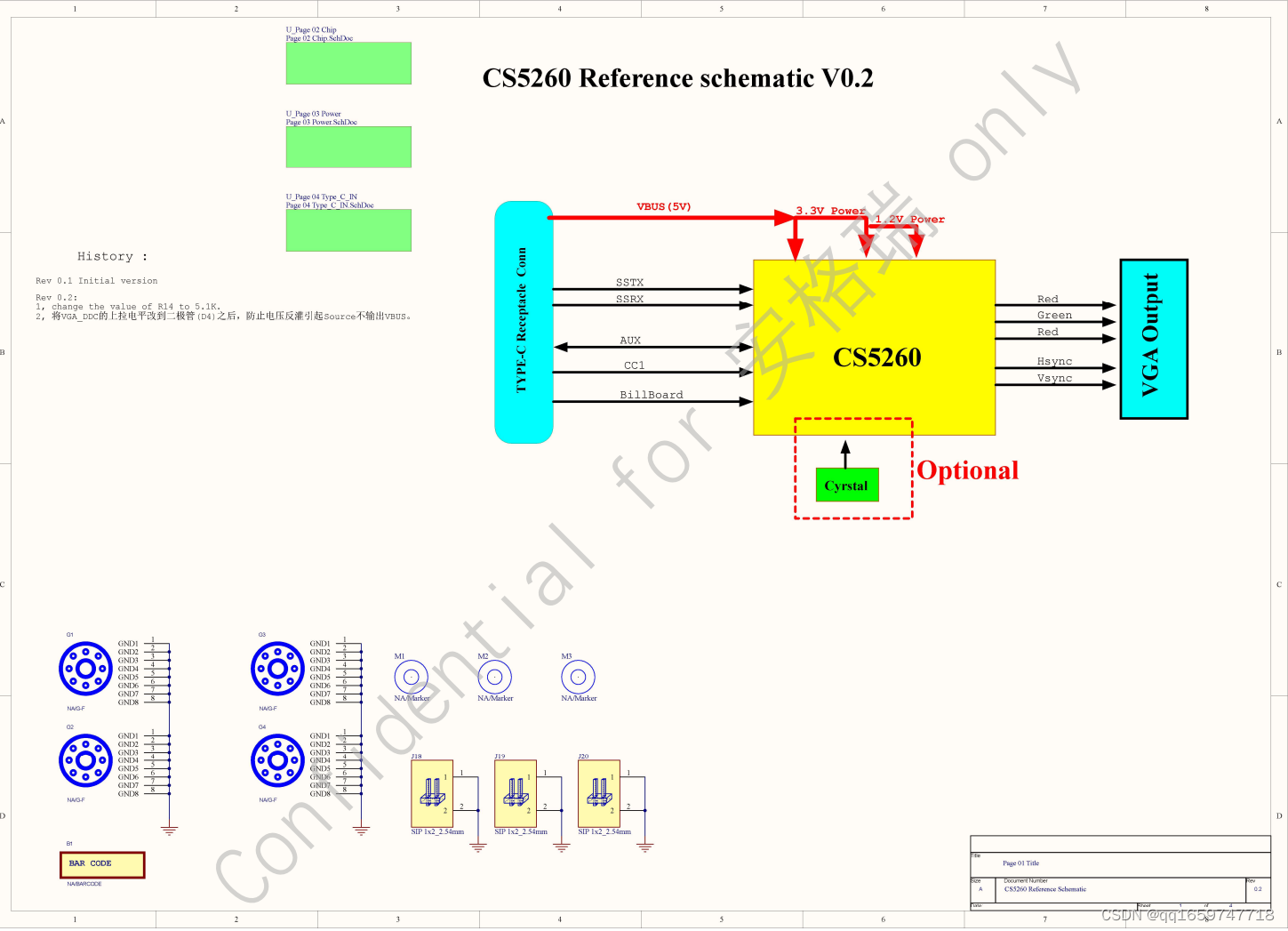
CS5260设计以上Type-C转VGA转换器或者转接线结构框图如下所示:
CS5260设计Type-C转VGA转换器或者Type-C转VGA转接线测试版电路 demoborad原理图参考如下所示: