做算命类网站违法吗火车头采集器和wordpress
很多在centos7上安装ffmpeg的教程都需要使用编译方式的安装;编译时间较长而且需要配置;
后来搜索到可以通过加载rpm 源的方式实现快速便捷操作
第一种方式:
- 首先需要安装yum源:
yum install epel-release
yum install -y https://mirrors.ustc.edu.cn/rpmfusion/free/el/rpmfusion-free-release-7.noarch.rpm
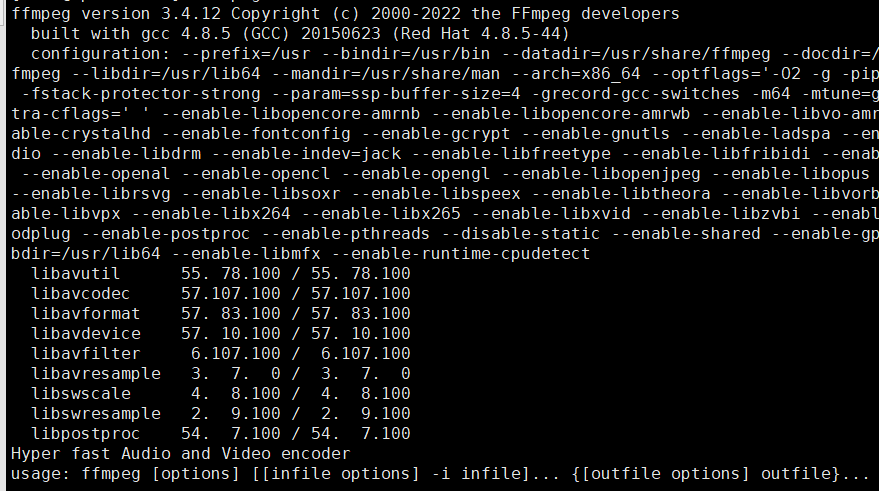
- 然后可以安装ffmpeg
yum install -y ffmpeg ffmpeg-devel
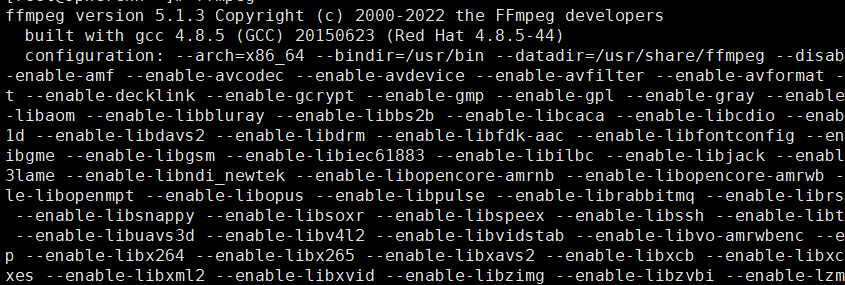
- 这个源安装的ffmpeg版本是3.4
第二种方式:
换一个yum源:
yum-config-manager --add-repo=https://negativo17.org/repos/epel-multimedia.repo
yum-config-manager --disable epel-multimedia
yum install --enablerepo=epel-multimedia ffmpeg ffmpeg-devel
这个安装的ffmpeg版本是 5.1