广东省企业诚信建设促进会网站企业退休做认证进哪个网站
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
文章目录
- 一项目简介
- 二、功能
- 三、系统
- 四. 总结
一项目简介
深度学习已经在许多领域中得到了广泛的应用,包括医疗健康领域。其中,YOLO(You Only Look Once)是一种先进的计算机视觉算法,用于实时目标检测。基于YOLO的V5版本,我们可以构建一个血红细胞检测识别系统。
一、系统概述
这个血红细胞检测识别系统基于深度学习和图像处理技术,能够自动识别和定位血液中的血红细胞。它利用YOLOV5算法进行实时目标检测,并通过进一步的处理和分类,实现对血红细胞的精确识别。
二、系统组件
- YOLOV5模型:使用YOLOV5算法进行实时目标检测,能够快速准确地识别出图像中的血红细胞。
- 图像预处理:对输入的血液图像进行预处理,包括去噪、增强对比度等,以提高检测的准确性。
- 特征提取:利用深度学习技术,从图像中提取出与血红细胞相关的特征,如颜色、形状等。
- 分类器:使用分类器对提取的特征进行分类,以确定是否为血红细胞。
- 输出处理:将检测结果进行可视化展示,并输出到相关系统或设备中。
三、工作流程
- 输入:将血液图像输入到系统中。
- 预处理:对图像进行去噪、增强等处理,以提高检测准确性。
- 特征提取:使用深度学习技术从图像中提取出与血红细胞相关的特征。
- 模型推理:将提取的特征输入到YOLOV5模型中进行推理,得到血红细胞的候选区域。
- 候选区域筛选:对候选区域进行筛选,排除非血红细胞区域,得到最终的检测结果。
- 输出处理:将检测结果进行可视化展示,并输出到相关系统或设备中。
四、优势与应用
- 优势:该系统具有实时性、准确性和自动化等特点,能够大大提高血红细胞检测的效率和精度。同时,它还能够减少人工干预,降低成本。
- 应用:该系统可以应用于医疗诊断、血液分析、科研等领域,为相关领域的研究和临床应用提供有力支持。
二、功能
环境:Python3.9、OpenCV4.5、torch1.9.1、PyCharm
简介:深度学习,血细胞检测识别系统,支持单个图像,批量图像检测识别,框选,计数。
三、系统
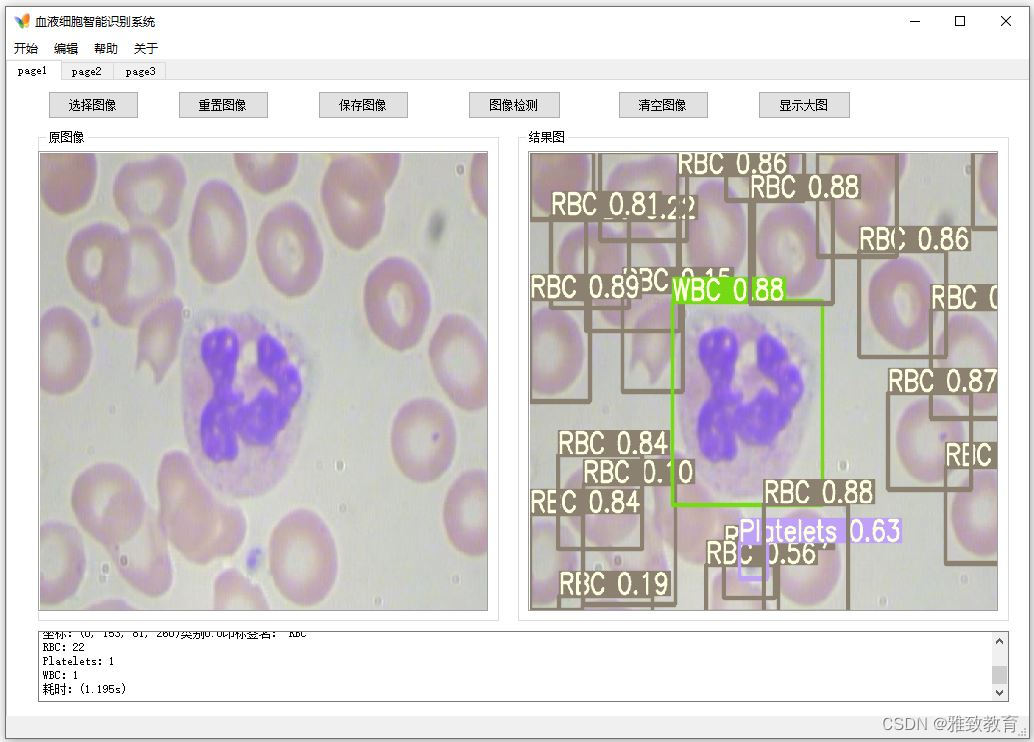

四. 总结
总之,基于YOLOV5的血红细胞检测识别系统是一种先进的医疗图像处理技术,能够大大提高血红细胞检测的效率和精度,为相关领域的研究和临床应用提供有力支持。