任县网站建设多少钱免费推广网站2023mmm
本文内容很容易理解,会阐述当dubbo使用zookeeper作为注册中心时候,zookeeper节点是什么样子的
本文的代码使用的dubbo版本是2.7.x,几年前的版本了,但是不影响探究
首先我们创建一个简单的maven项目,然后写出一段dubbo provider代码(服务提供者),然后启动服务,之后观察zookeeper节点样子
pom.xml文件需要引用2个依赖,如下
<!-- dubbo的依赖 -->
<dependency><groupId>org.apache.dubbo</groupId><artifactId>dubbo</artifactId><version>2.7.23</version>
</dependency><!-- 使用zookeeper作为注册中心的时候,dubbo要通过zookeeper客户端操作zookeeper,
这个curator就是zookeeper客户端,zookeeper客户端还有一个是zkClient,本文中我们
使用curator,不使用zkClient -->
<dependency><groupId>org.apache.dubbo</groupId><artifactId>dubbo-remoting-zookeeper-curator5</artifactId><version>2.7.23</version>
</dependency>
创建服务接口
package aa.bb;
public interface User {String getUserName();
}
创建服务接口实现类
package aa.bb;public class UserImpl implements User {@Overridepublic String getUserName() {// 返回一段文本,陈述一段客观事实return "HR is a little bitch";}
}
创建服务提供者代码(provider)
public class Provider {public static void main(String[] args) throws IOException {ServiceConfig<User> service = new ServiceConfig<>();service.setApplication(new ApplicationConfig("service_provider"));service.setRegistry(new RegistryConfig("zookeeper://127.0.0.1:2181"));service.setInterface(User.class);service.setRef(new UserImpl());ProtocolConfig protocolConfig = new ProtocolConfig();protocolConfig.setTelnet("invoke");// 允许使用telnet命令调用dubbo服务protocolConfig.setHost("127.0.0.1");protocolConfig.setPort(20880);protocolConfig.setName("dubbo");// 这个协议名必填,而且不能乱写service.setProtocol(protocolConfig);service.export();System.out.println("服务提供方启动成功并且已经注册到zookeeper");System.in.read();}}
打开zookeeper,zookeeper初始节点是下面这样子的

运行上述的main函数,之后会发现zookeeper中节点的样子如下
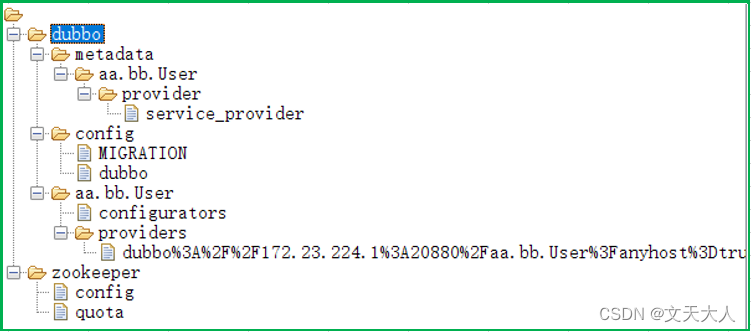
dubbo:本文中有个代码是new RegistryConfig,这个对象有一个setGroup()方法,因为我们没有调用该方法,所以根目录是dubbo,如果我们setGroup("HR"),那么根目录就会变成HR
dubbo/aa/bb/user:表示本文中的public interface User接口服务
dubbo/aa/bb/user/providers:服务提供者的目录,你可以使用相同的代码,再打开一个IDEA或者Eclipse,然后运行这段代码,此时providers目录下面就会有2条数据
dubbo/aa/bb/user/configurators:服务提供者动态配置相关的元数据信息,后续文章单独讨论
好了本文就到这里,其实非常的简单,主要是想大概过一下dubbo注册到zookeeper之后,节点是什么样子的,要是你写dubbo,也基本就是这样设计节点,没什么出彩的,但是必须要了解一下,方便后续读dubbo注册中心模块源码的时候,知道如何创建节点的
虽然本文没有写consumers的代码,但是聪明的你应该能预见到,如果有consumers,那么应该会在dubbo/aa/bb/user/providers同级目录出现一个dubbo/aa/bb/user/consumers的新目录,没错,确实是这样