正规的网站制作电话太原市建设北路小学网站
模拟器抓HTTP/S的包时如何绕过单向证书校验(XP框架)
逍遥模拟器无法激活XP框架来绕过单向的证书校验,如下图:
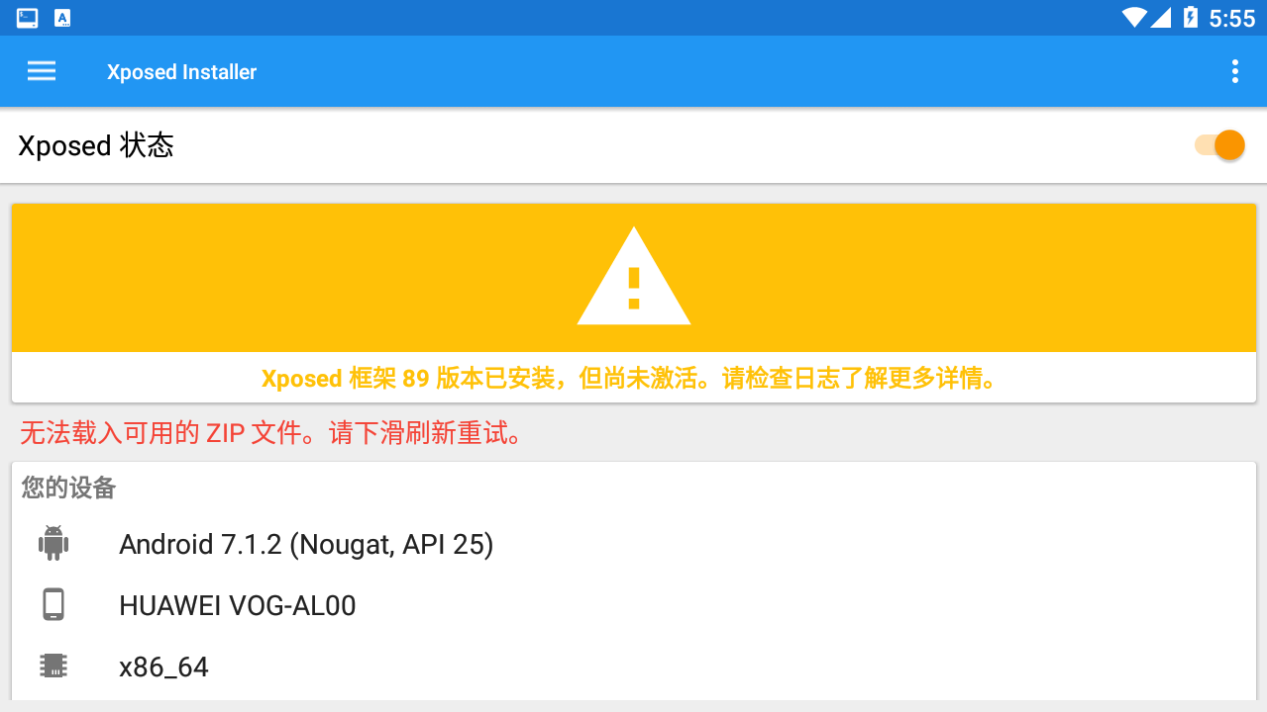
解决办法:
- 安装JustMePlush.apk
- 安装Just Trust Me.apk
- 安装RE管理器.apk
- 安装Xposedinstaller_逍遥64位版AlphaEva.apk
- 安装终端模拟器.apk
- 把xposed文件夹复制到模拟器的system目录下去
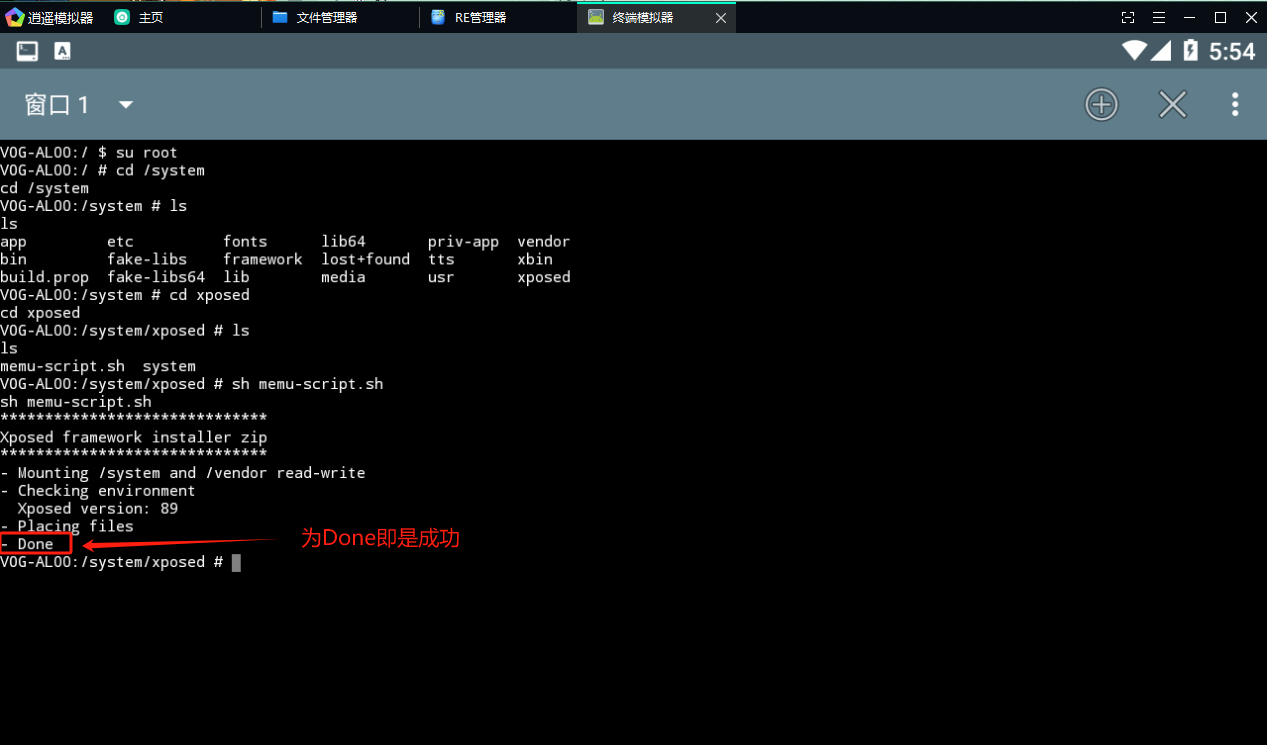
- 进入终端模拟器APP输入以下代码
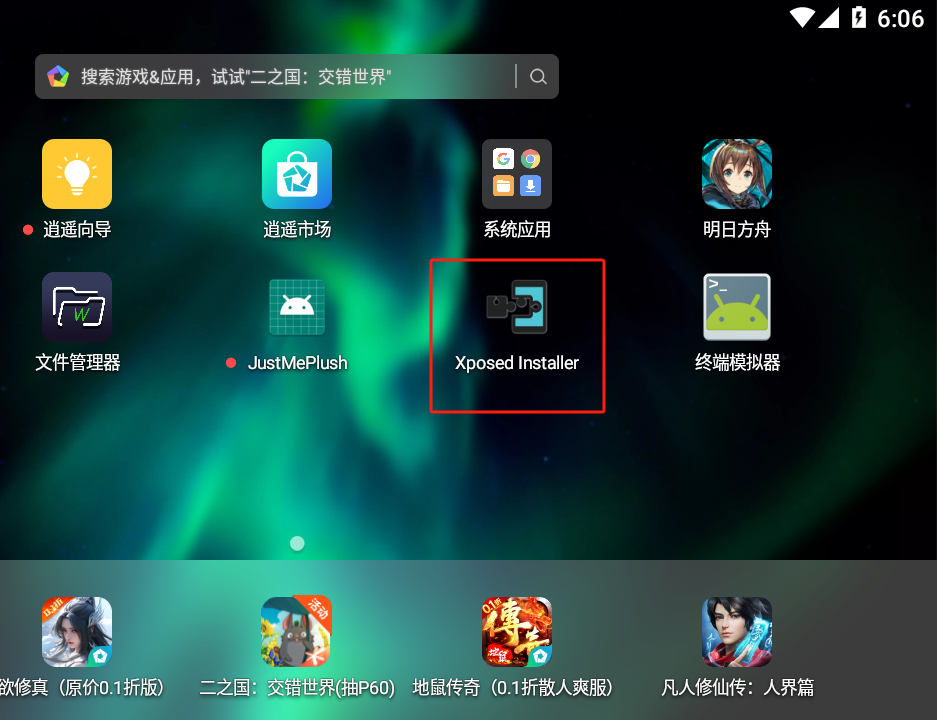
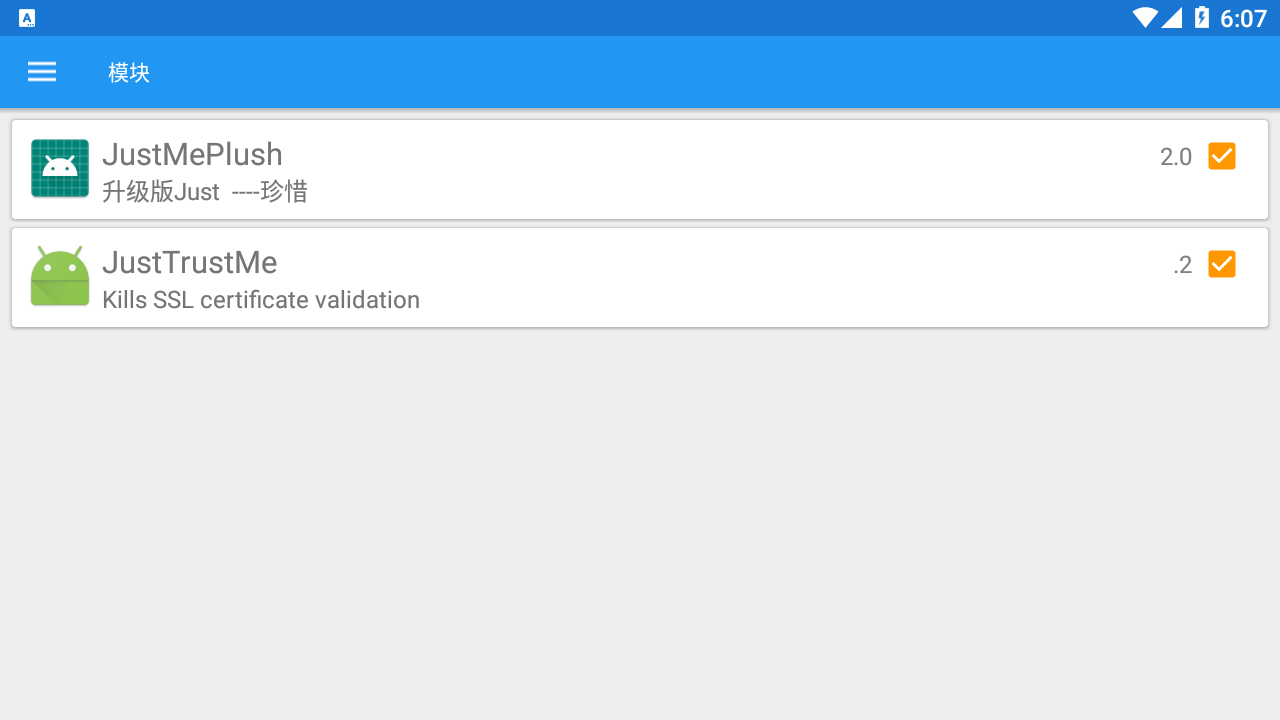
- 点击如下图的软件
再点击左上角选项中的模块功能
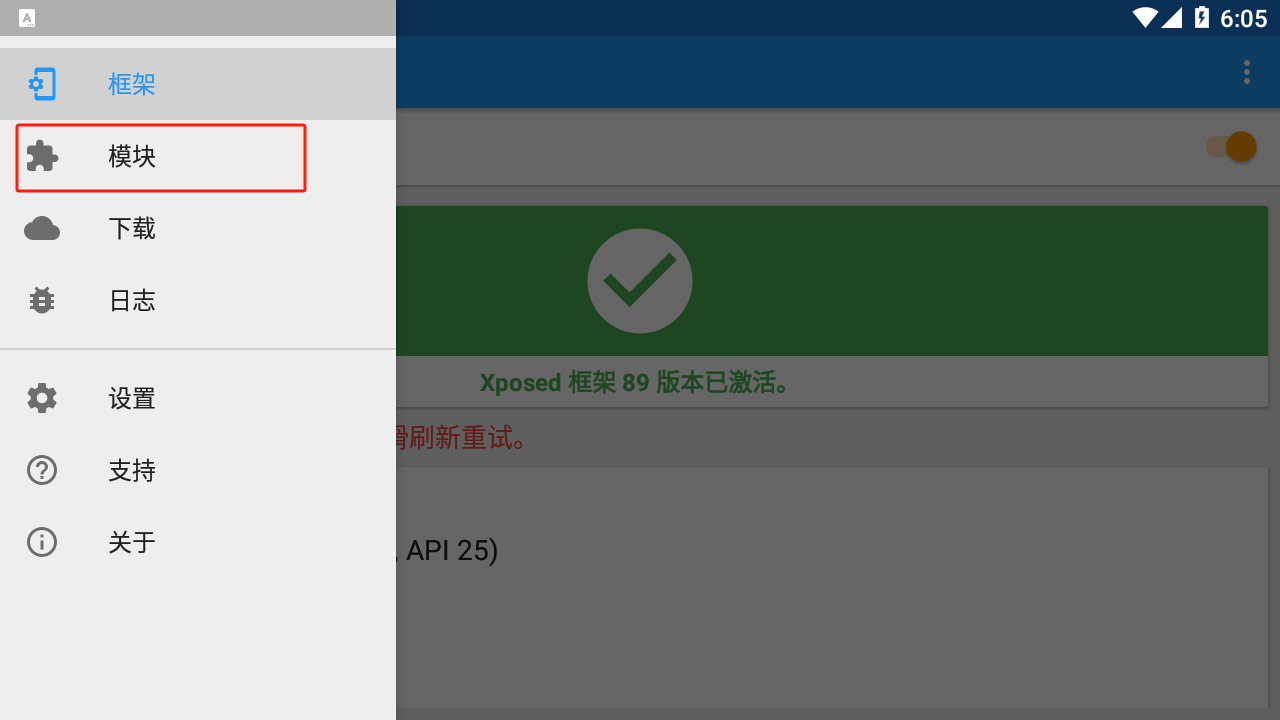
开启这两个模块后重启模拟器就完事了。
如何验证一下自己是否已经可以成功绕过抓APP包时单向证书的校验呢?
有这么一个靶场项目在Github上,是一个APK安装包你可以通过不同的选项来测试一些功能的可行性。
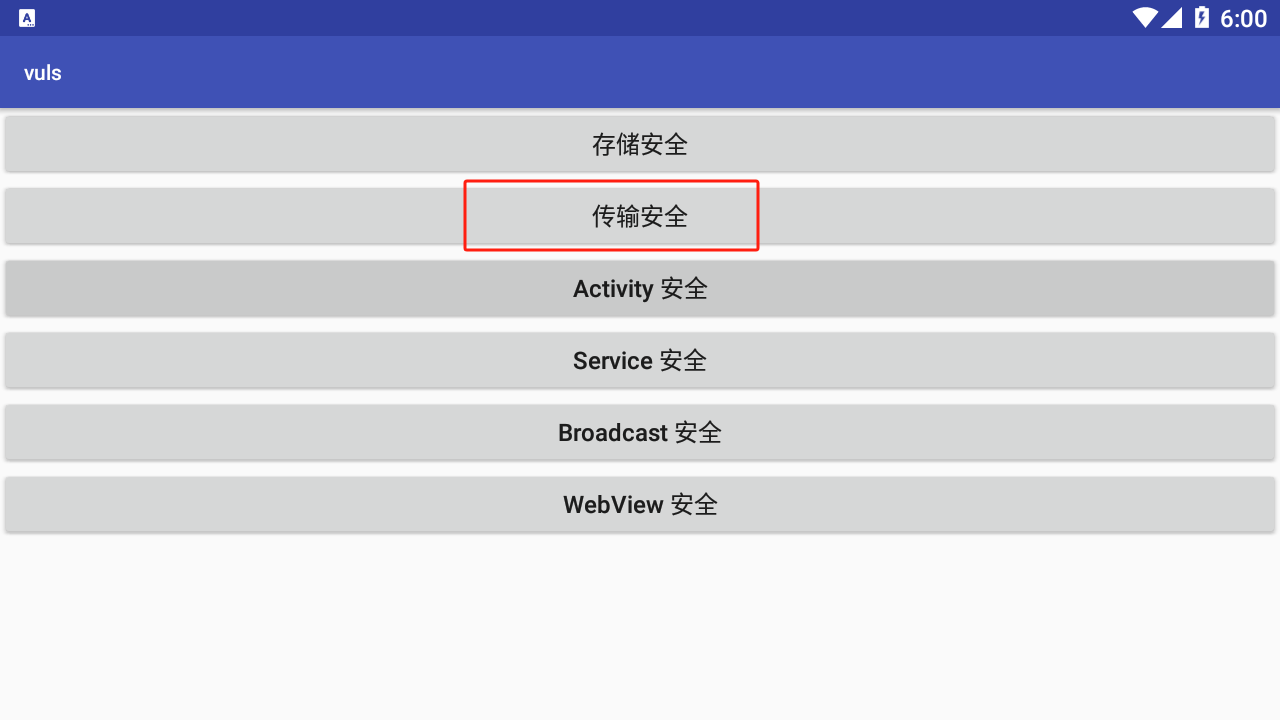
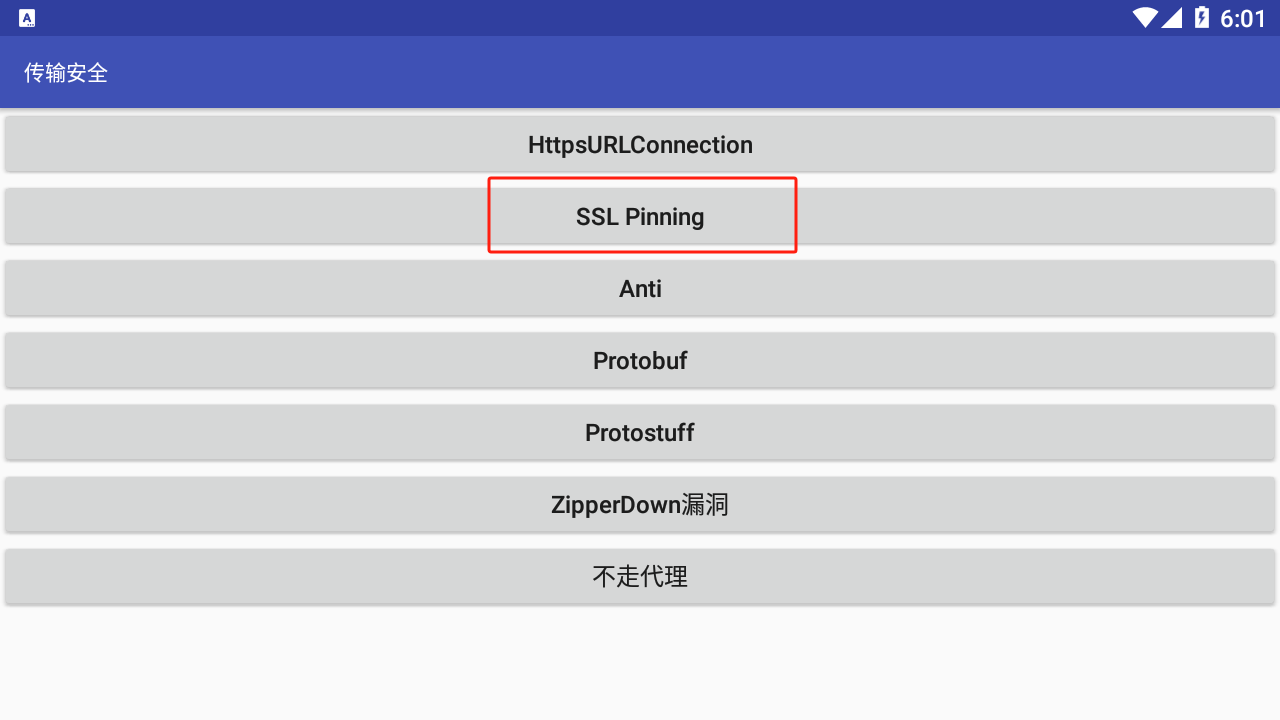
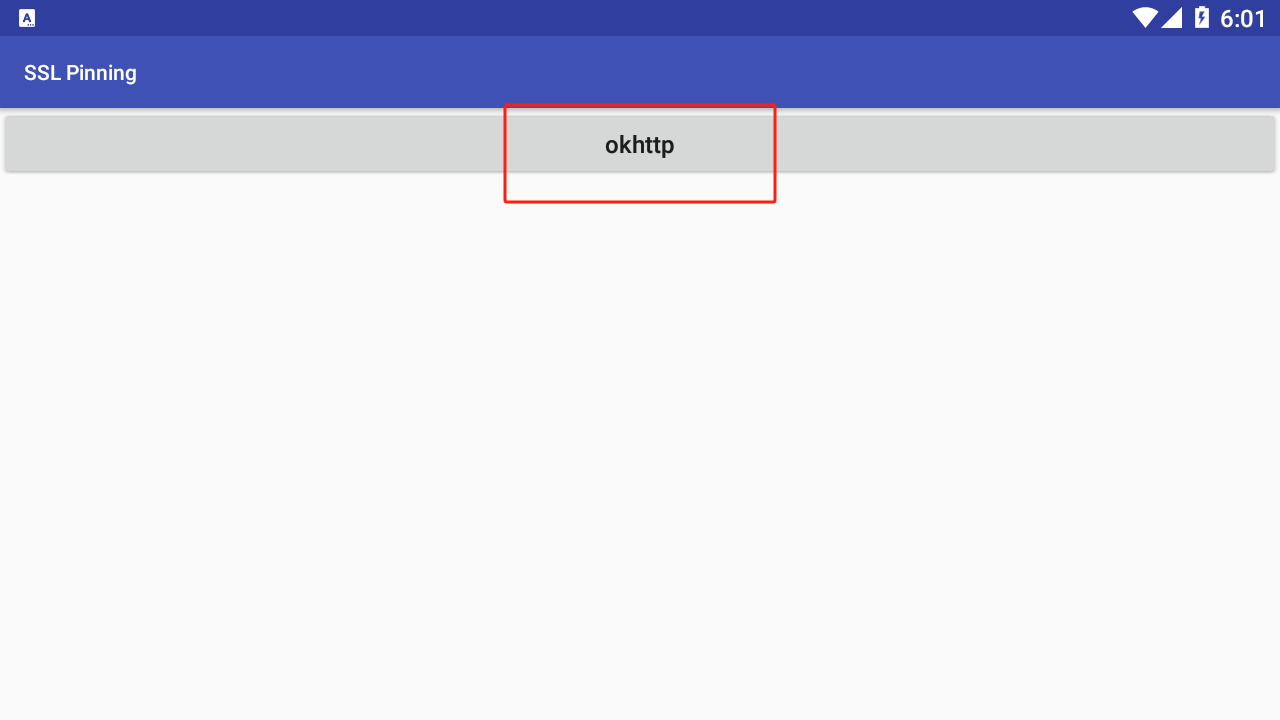
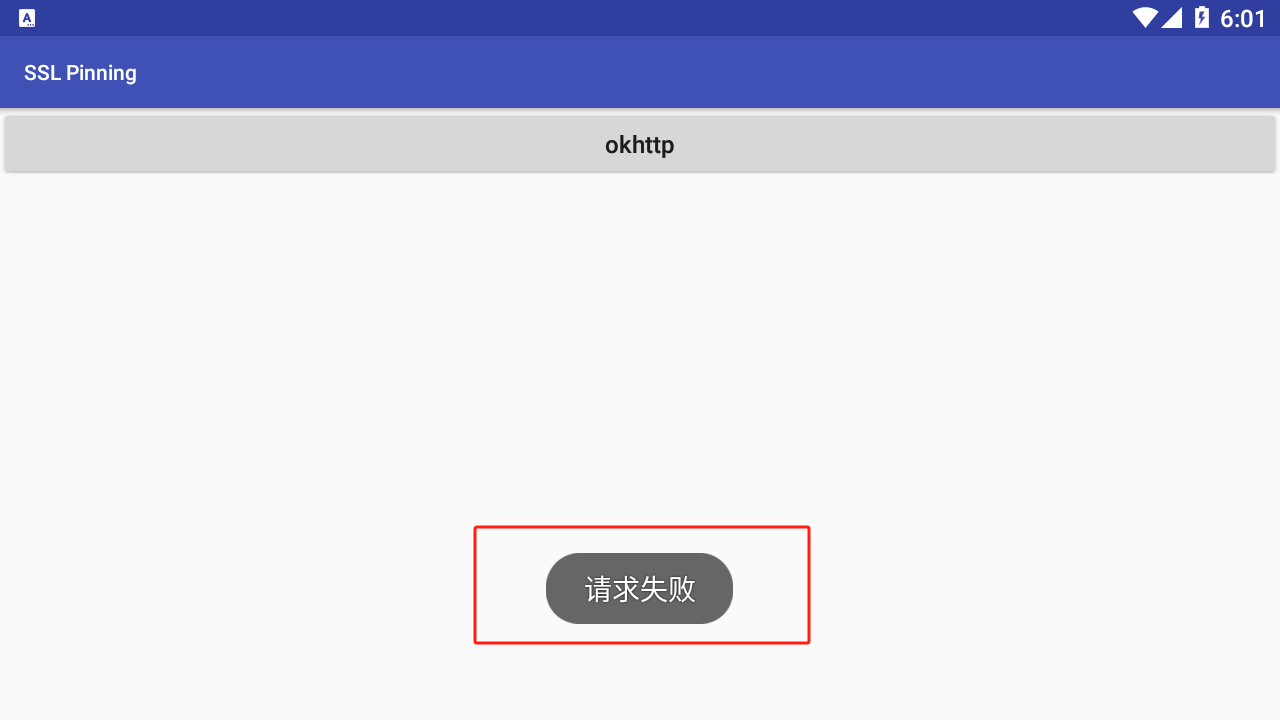
我截图展示的这个选项就是测试是否能成功绕过单向证书校验的功能,如果你能成功绕过了并抓取到数据包便会是请求成功的提示,反之则是如上图的请求失败提示。
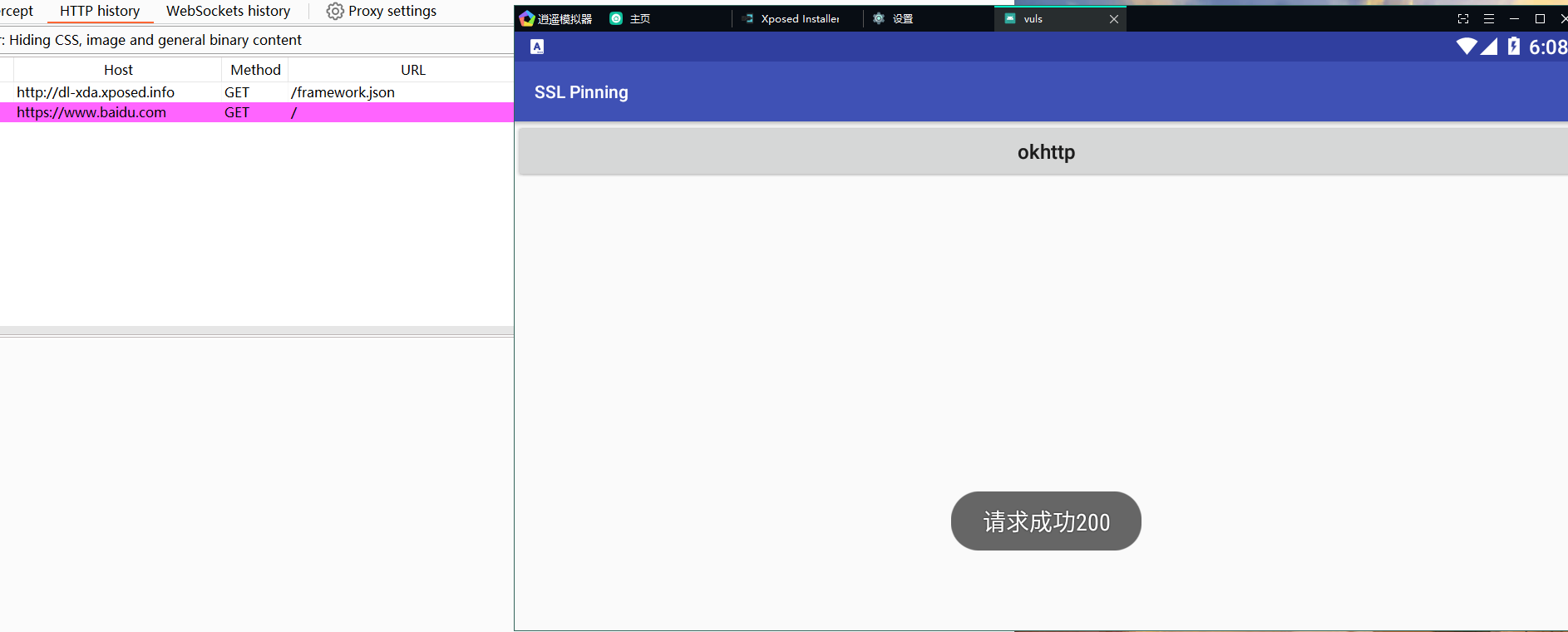
点击按钮后成功绕过如下图:
涉及的相关apk安装包:
我用夸克网盘分享了「工具APK」,点击链接即可保存。
链接:https://pan.quark.cn/s/31f803f8aea8
提取码:2kV1