电白区建设局网站怎么做淘客的网站
#Apollo开发者#
学习课程的传送门如下,当您也准备学习自动驾驶时,可以和我一同前往:
《自动驾驶新人之旅》免费课程—> 传送门
《2023星火培训【感知专项营】》免费课程—>传送门
文章目录
前言
Ubuntu
Linux文件系统
Linux指令
云实验一
云实验二
总结
前言
见《自动驾驶学习笔记(一)——Apollo平台》
Ubuntu
Ubuntu基于Linux内核的基于桌面的发行版之一,项目由南非人马克·沙特尔(Mark Shuttle)发起,其目标在于为一般用户提供一个最新的、同时又相当稳定的主要由自由软件构建成的操作系统。Ubuntu具有庞大的社区力量,用户可以方便地从社区获得帮助。是 Linux众多发行版中使用量最大、普及度最高的发行版。Apollo目前推荐使用ubun18.04及其以上的版本。
Ubuntu的主界面如下图所示:

Ubuntu的优点如下:
1.友好的桌面环境,操作简单;
2.特定的特权管理,因此安全性高;
3.易于安装、可以稳定运行在台式机、笔记本电脑之上;
Linux文件系统
Linux下的文件系统为树形结构,入口为/,无论哪个版本的 Linux系统,都有这些目录,这些目录是标准的。如下图所示:

各个Linux发行版本会存在一些小小的差异,但总体来说,还是大体相近的。/bin 主要放置系统的必备执行文件。/etc 目录保存了系统管理所需的配置和子目录。/root 该目录为系统管理员,也称作超级权限者的用户主目录。
Linux指令
指令的格式如下图所示:

常用指令有:
Is 列出目录内容
cp 拷贝文件
cd 切换目录路径
pwd 显示当前目录路径
chown 改变文件属性
mkdir/rmdir 创建/删除目录
tar 文件打包
touch 修改文件时间属性,当文件不存在时创建文件
clear 清除屏幕
cat 查看文件内容
bash 启动sheel脚本
vim 代码编辑
云实验一
实验内容:
本实验将以 Ubuntu系统为例,练习 Linux的常用操作命令
实验目的:
理解Lnux的文件目录结构及各文件作用
掌握 Ubuntu操作系统的基本操作以及 Liunx的常用指令
实验配置:
云端:Apollo Studio云实验室之《 Linux基础入门与实践》实验项目
本地:Apollo EDU版
免费的实验入口如下图所示:

提示:需要用Google浏览器,暂不支持其他浏览器
实验界面如下图所示:

云实验二
实验内容:
使用 Drearview播放并分析自动驾驶离线数据包
实验目的:
掌握Apollo的启动流程及原理;
掌握应用Apollo自动驾驶调试工具去分析井定位自动驾驶问题
实验配置:
云端: Apollo Studio云实验室之《快速上手,五步入门自动驾驶》实验项目
本地: Apollo EDU版本/demo_3.5 recoder
免费的实验入口如下图所示:
实验界面如下图所示:

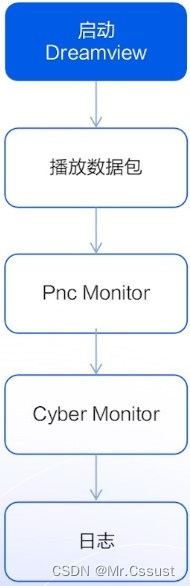
实验流程如下图所示:
总结
以上就是本人在学习自动驾驶时,对所学课程的一些梳理和总结。后续还会分享另更多自动驾驶相关知识,欢迎评论区留言、点赞、收藏和关注,这些鼓励和支持都将成文本人持续分享的动力。
另外,如果有同在小伙伴,也正在学习或打算学习自动驾驶时,可以和我一同抱团学习,交流技术。
版权声明,原创文章,转载和引用请注明出处和链接,侵权必究!
文中部分图片来源自网络,若有侵权,联系立删。