企业门户网站功能wordpress链接设置方法
问题
传入的参数为空字符串,但还是根据参数查询了。
原因
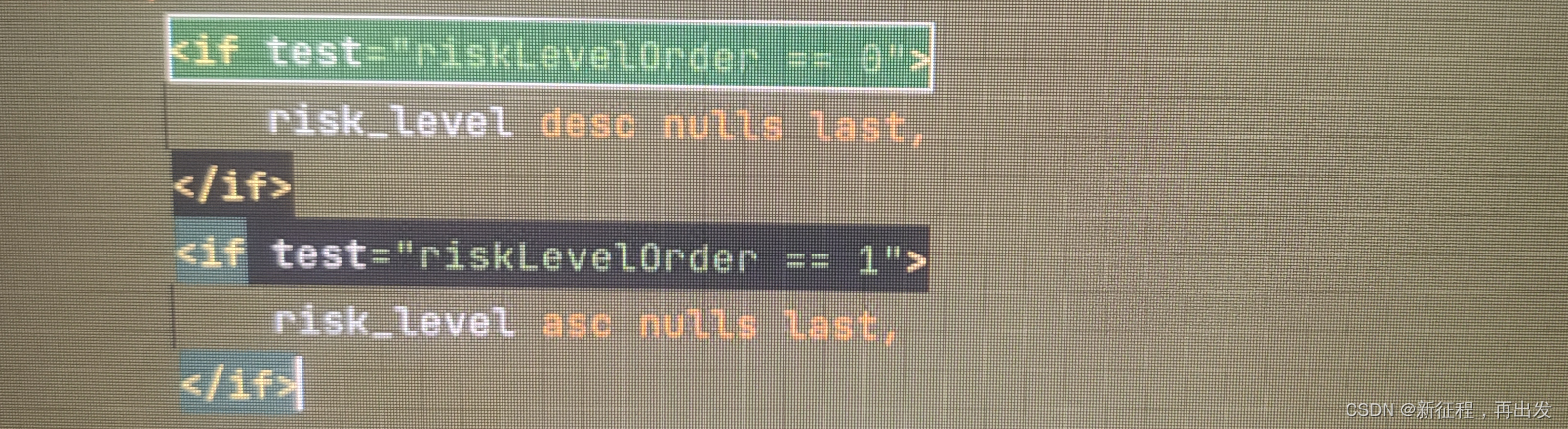
在 XML 中使用 标签进行条件判断时,需要明确理解其行为。在 MyBatis 等类似的 XML 映射文件中, 标签通常用于动态拼接 SQL 语句的条件部分。当传入的参数 riskLevel 为空字符串时,可能会导致 SQL 语句中的条件判断出现意外结果。
示例中, 标签的测试条件是 riskLevel == 0,这意味着当 riskLevel 的值为 0 时,条件成立。但是,当 riskLevel 的值为空字符串时,XML 解析器会将空字符串视为一个非空的字符串,因此条件判断会被认为成立。
解决方法
为了解决这个问题,你可以在 XML 中做进一步的处理,例如在判断之前先检查 riskLevel 是否为空,或者更改条件判断逻辑,以适应传入空字符串的情况。
<if test="riskLevel != null and riskLevel != '' and riskLevel == 0">risk_level = #{riskLevel}
</if>

hy:56
人生所有真实的快乐,一定是恒久的努力。