企业做网站400电话作用徐州网站的优化

*本文首发自《中国电信业》
数字经济时代,数据库作为企业核心数据存储、处理、挖潜等方面的关键载体,重要性日益凸显。对于运营商而言,数据库具有行业用户数量多、访问数量多、业务复杂度高、数据安全性高、响应要求性高以及需要 7*24 小时服务等特点,其运行情况直接影响客户体验和支撑能力。
近几年,随着我国自主研发的基础软硬件产品发展、进步,部分应用场景已经实现数据库的自主可控。江苏移动全力构建基于 5G+算力网络+智慧中台的“连接+算力+能力”新型信息服务体系,统筹推进 CHBN 全向发力、融合发展,在此阶段底层架构需要做较大的调整,特别是集中式数据库在高并发、高负载、海量数据存储的业务场景投资多、无法扩容的问题越来越突出,对于业务发展正逐步带来负面影响。
江苏移动生产系统经过多年的发展,业务模块繁多,逻辑复杂,对底层数据库的性能、稳定性要求几近苛刻,在 IT 基础架构上持续演进时,不仅要求生产业务不受影响,而且还要求在数字经济的发展,一流服务科技创新创建提供强劲动能。
在中移动信息技术有限公司的大力支持下,江苏移动充分研究了多种商用数据库,以加强数据安全、满足业务发展、降本增效为前提,慎重选择了 OceanBase 作为核心数据库。在项目实施过程中,OceanBase 结合江苏移动业务现状和未来发展目标,同江苏移动IT部专家、应用开发方等从分布式架构设计、应用兼容性适配、容灾高可用场景、数据库性能提升等方面开展专项工作,稳步推进项目落地,支撑运营商核心数据库的技术升级发展。

基于企业在生产系统中使用数据库的经验,江苏移动认为,运营商的数据库必须确保数据安全,利用数据库自身的能力以保证数据不丢失,可根据需要分层访问、授权访问和数据加密。同时,数据库要具备优秀的高可用性,能够做到异地多活部署,保证生产系统稳定运行。
目前,江苏移动核心系统数据库架构规划按照无锡、南京两地三中心三副本进行部署,基于 Paxos 多副本架构,让整个系统没有任何单点故障,可以最大限度缩短业务停服时间,保证系统的持续可用,做到机房故障无影响,城市级故障业务不受损,可达到 RPO=0,RTO<30s ,即国际标准灾难恢复能力最高级别 6 级。
CRM 核心库采用 4-4-4 架构,采用自动负载均衡策略将主副本随机打散在 2 个 Primary Zone 中以承载业务读写负载,物理备库承载业务只读访问。经过长时间验证,该架构能够满足业务海量连接、高负载的业务需求,通过完全自主研发的数据库架构优势,将分布式数据库的技术能力转变成江苏移动的生产力,带动企业经济效益的增长。
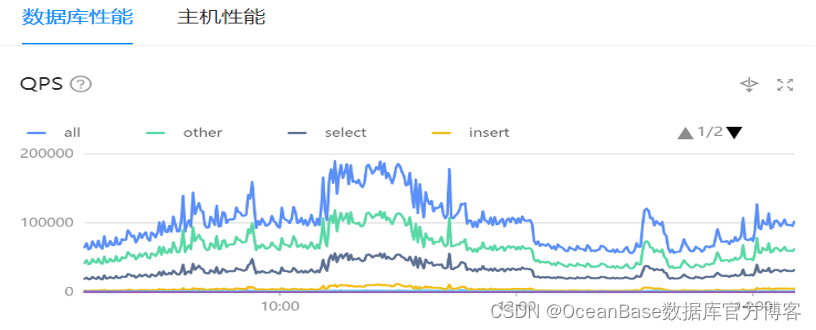
核心库业务高峰期QPS近20万

原生分布式数据库 OceanBase 语法兼容性强,对象兼容性高,既满足了江苏移动的业务逻辑需求,又极大降低了应用的改造工作量。
通过 OceanBase的OMA 评估工具,连接上源端数据库抓取对象结构、SQL 语句信息以评估对应 OceanBase 版本的整体兼容性情况,并给出分析报告和不兼容点改造建议 ;OMA SQLReplay 模块可通过捕获生产库业务高峰或者长时间的 SQL 负载文件后在 OceanBase 集群进行回放,可直观掌握原 SQL 在 OceanBase 集群的响应时间和整体负载情况,在前期就可针对性进行 SQL 语句级别优化或集群规模调整,保障割接后系统稳定运行。
OceanBase 的配套迁移工具 OMS 提供的同构或异构数据源与 OceanBase 数据库之间进行数据交互的服务,具备在线结构迁移、全量迁移和增量数据同步,无缝迁移源端数据库中的存量业务数据和增量数据至 OceanBase 数据库 租户中;在全量数据迁移完成,增量数据迁移至目标端并与源端基本追平后,OMS 会自动发起针对源库数据表和 OceanBase 目标表的全量数据校验任务,保证迁移任务可以准确完成。整个迁移任务和校验过程完全依托 OMS 自动化能力,极大降低人力迁移运维成本。

OceanBase 数据库支持超大规模集群(节点超过 1500 台,最大单集群数据量超过 3 PB,单表数量达到万亿行级别)动态扩展,在 TPC-C 场景中,系统扩展比可以达到 1:0.9,使用户投资的硬件成本被最大化利用。
在江苏移动的整体架构设计中,划分了若干个中心生产集群,每个生产集群上按照不同业务系统对应 OceanBase 的不同租户,租户间实现资源隔离,让每个租户的实例不感知其他实例的存在,并通过权限控制确保不同租户数据的安全,配合 OceanBase 数据库强大的在线扩缩容特性,能够提供安全、灵活的 DBaaS 服务。
不仅如此,与传统关系型数据库相比,OceanBase 可以在不影响在线业务的前提下,明显降低存储成本;OceanBase 采用 LSM-Tree 存储引擎,存储模块采用全新设计的行列混合存储结构,同时将高效的数据编码技术与数据压缩算法相结合,实现存储空间大幅减少;压缩比率超过 85%。

随着移动互联网的高度发展以及 5G 时代的到来,数据量爆发式增长,我们正在进入一个大数据时代,对于数据的处理,也就是对于数据库产业而言,是一个巨大的机会。
长期以来,运营商对系统服务稳定性要求高,对数据库产品要求严苛。以自研数据库使用为契机,OceanBase 完全自主研发,能够做到自主可控,能够满足核心数据库的安全及稳定运行要求。从项目实际运行效果来看,OceanBase 针对中国移动自研国产操作系统 BCLinux、国产服务器、数据库一体机进行全面适配,实现“数据库+操作系统+硬件服务器“的全栈自主可控,为核心数据库未来长期的安全稳定运行提供有力保障。
江苏移动一直致力于推动技术自主创新,在项目中实施过程中,基于业务现状和未来规划,从分布式架构、应用兼容性适配、容灾高可用场景、全栈化适配、数据库性能提升等多个方面开展专项工作,目前已经取得较好效果,部分核心库已经上线并稳定运行,在运营商甚至整个政企行业的核心 IT 数据库领域都有较好的推广价值,也凸显了江苏移动在数智化转型上的前瞻性与领先性。
近期,中国通信标准化协会大数据技术标准推进委员会(CCSA TC601)公布了第六届大数据“星河”案例获奖名单, 特别值得一提的是,江苏移动联合 OceanBase 打造的 “CRM 系统核心数据库替代项目”脱颖而出获得了数据库方向的“标杆案例奖”。
据悉,2022 年第六届大数据“星河”案例征集活动意在通过总结和推广大数据产业发展的优秀成果,推动大数据在社会生产生活中的应用, 促进大数据技术产品及相关产业发展。自 2022 年 9 月启动以来,征集活动受到了业界广泛关注,共收到包括行业数据应用、数据安全、隐私计算、数据资产管理、数据库五大方向的申报案例 595 份。此次江苏移动获得数据库标杆案例奖,是江苏移动与 OceanBase 在推动数据库自主可控联合创新实践过程中的又一个成功范例,标志着双方在数据库关键领域的合作迈出了更坚实的一步。
未来,随着技术发展以及市场成熟,分布式数据库行业将迎来爆发式增长,双方将将聚力创新,继续合作探索运营商行业核心系统数据库自主创新解决方案,如两地三中心部署、HTAP 场景等,以期打造更多运营商行业数据库自主创新样板点,成就行业标杆,助推运营商开启数字化转型发展新征程。