企业网站宽度给多少能看的网址的浏览器
传统的视频监控系统建设,经常存在各方面的因素制约,造成管理机制不健全、统筹规划不到位、联网共享不规范,形成“信息孤岛”、“数据烟囱”。在监控系统的建设中缺乏统一规划,标准不统一、视频图像信息利用率低等问题日益突出。随着互联网新兴技术的快速发展与落地应用,对传统的视频监控系统改造升级,已经成为当前各行业领域安全防范、智能监管等方面的紧迫任务。

互联网技术的高速发展也催生了人工智能技术的进步,泛在感知数据和图形处理器等计算平台推动以深度神经网络为代表的人工智能技术飞速发展。到目前为止,人工智能技术正在推动社会全面进入了智能时代,也同样带来了新一轮的科技革命和产业变革机遇,安防视频监控技术也不例外。
一、视频技术的发展与进步
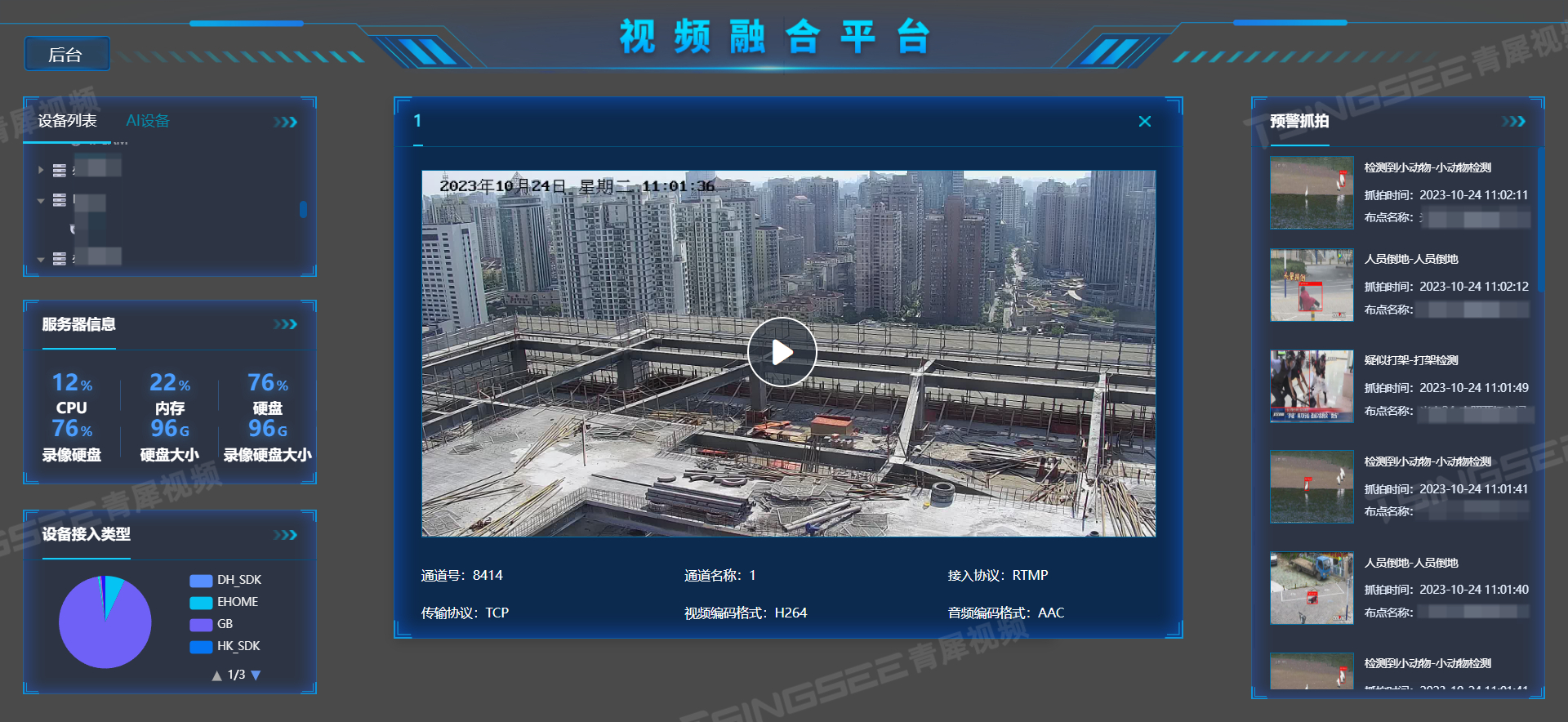
安防监控系统EasyCVR平台已经积极融入了人工智能AI视频智能分析技术,作为安防领域的主流视频监控管理平台,EasyCVR在视频能力上表现极其优秀,平台支持多协议接入、兼容多类型的设备,包括国标GB28181协议、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海康、大华、宇视、华为、萤石云、乐橙SDK等,能对外分发RTMP、RTSP、HTTP-FLV、WebSocket-FLV、HLS、WebRTC等视频流,实现全终端、全平台的覆盖与视频流展示。

不止如此,视频监控系统EasyCVR平台还采用了开放式的网络结构,能将分散的各类视频资源进行统一汇聚、整合、集中管理,实现数据采集、处理、汇聚、分析、存储、管理等全环节的视频能力。EasyCVR安防管理平台具备权限管理、设备管理、鉴权管理、流媒体接入与转发等管理能力,可以提供实时远程视频监控、视频录像、录像回放与存储、告警、语音对讲、云台控制、平台级联、磁盘阵列存储、视频集中存储、云存储等视频能力,能满足工地、工厂、石化、煤矿、住宅小区、楼宇商场、景区、校园、消防、农业、物流仓储、能源环保等多场景、多行业的视频监需求。
二、视频智能分析技术的难点
视频智能分析需要处理的数据量巨大且涉及多种类型的图像和声音数据。如何对这些数据进行有效处理和分析,以便获取准确的结果,是AI智能视频分析技术面临的重要问题。其次,视频数据的复杂性和不确定性给分析的准确度带来了困难。在视频中,各种因素如光线、角度、颜色、形状、声音等都可能影响分析结果。此外,视频中的背景、噪声和其他干扰因素也可能导致智能分析的误差。
三、AI视频分析技术的发展与应用
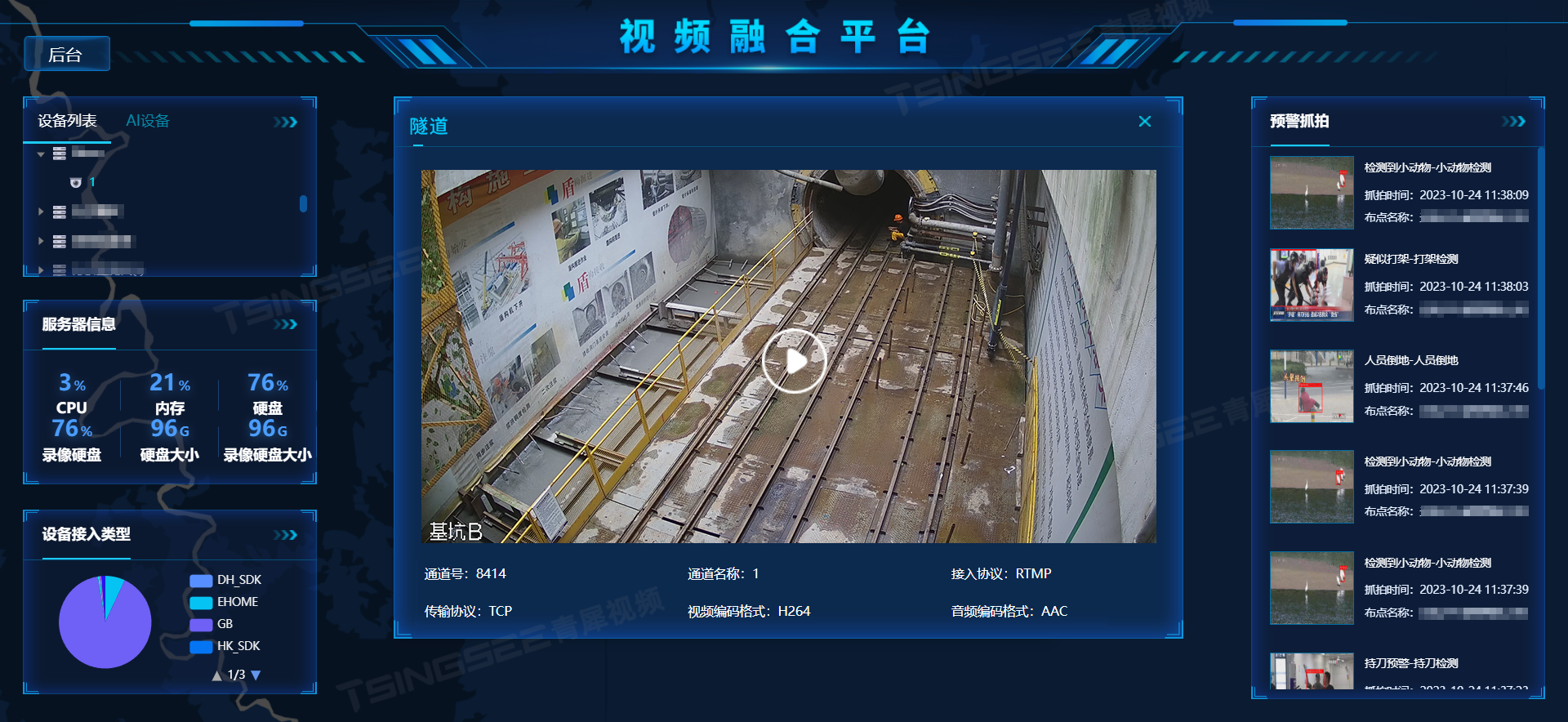
随着大数据、云计算、互联网、物联网等信息技术的发展,安防视频监控也同样面临着智能化的需求。视频监控系统EasyCVR也已经积极融入了AI视频智能识别技术方案。平台可以快速接入具备AI智能分析能力的硬件或算法平台,实现各行各业的 可视化、智能化监管需求。通过AI算法的接入,对现场的视频监控图像进行智能分析和异常情况告警,能及时发现企业生产与管理过程中中存在的安全隐患问题,并协助管理人员及时解决。

视频汇聚平台EasyCVR与TSINGSEE青犀AI智能分析网关可助力行业打造可视化视频智能监管综合管理平台,利用视频监管能力与AI深度学习算法,可以实现周界警戒、行为警戒、人数统计、人车结构化数据等识别与应用。截至目前,TSINGSEE青犀视频监控智能监管方案已经应用在智慧城管、智慧加油站、智慧社区、智慧楼宇、智慧工地、智慧工厂、智慧矿山、智慧水利、智慧校园、明厨亮灶等领域与场景中。
技术应用:
1)海量视频接入:TSINGSEE青犀视频监控智能监管方案支持基于标准协议与厂商私有协议的海量视频接入,涵盖多类型设备,包括:网络摄像头、硬盘录像机、移动执法仪、无人机、智能移动终端等,能兼容市面上大多数的视频源设备。
2)算法精准:支持对每路视频ROI区域、分析频率、持续时间、目标像素、报警阈值等进行针对性调整设置,以匹配差异环境导致的误识别,提升算法准确性。
3)算法算力资源调度:支持GPU算力潮汐调度、均衡调度,最大限度发挥GPU性能;支持设备任务、轮巡任务等多种配置模式,适应多种应用场景。
4)数据共享:支持通过GB28181协议与上级平台对接,支持GA/T 1400-2017、FTP、SDK等协议的图片传输,实现业务场景中视频及图片数据的快速与上级共享、打破数据孤岛现象。