商丘网站制作费用品牌网站制作流程
教材《软件工程 实践者的研究方法》
双语教学,但目前感觉都是在讲没用的
”过程决定质量,复用决定效率”
介绍
软工的本质
程序=数据结构+算法
软件=程序+文档(需求、模型、说明书)
软件应用:
系统软件
应用
工程/科学软件
嵌入式
产品线软件
移动应用
AI软件
随着硬件的飞速发展,软件也必须更新
web apps
mobile apps
云计算(IAAS,PAAS,SAAS):公有云、私有云
软件产品线:可复用
软件工程
cs:硬件、编译器、操作系统、编程语言
se:工程向
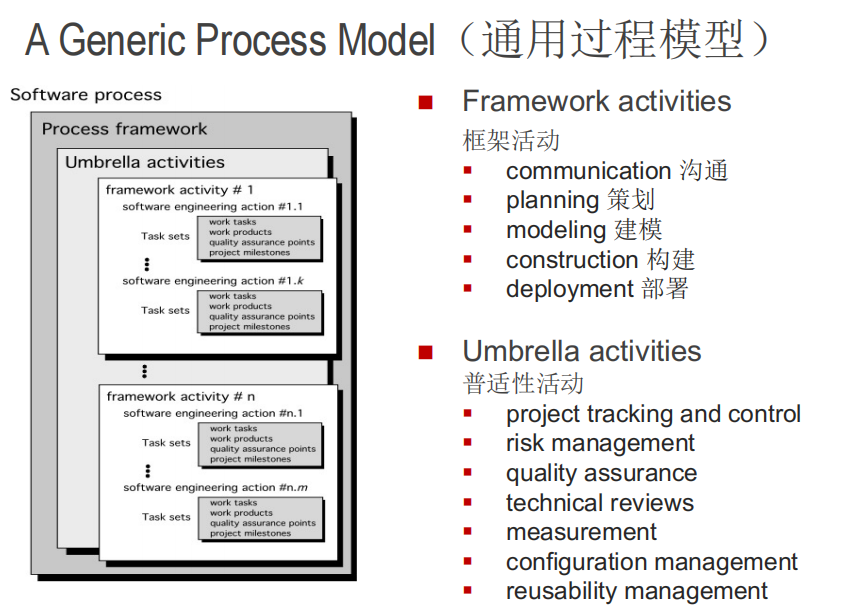
过程框架:
- 框架活动
- 沟通
- 计划
- 建模(原型):分析需求-》设计
- 构建:生成代码->测试
- 部署
- 保护伞活动
- 追踪控制
- 风险管理
- 质量保证
- 技术审查
- 度量(结对编程。。。)
- 配置管理
- 可复用性
- 准备和发布
原则:
- 存在的理由(?)
- KIS原则 KEEP IT SIMPLE,STUPID
- 保持愿景
- 你生产的就是别人消费的
- 开放
- 对复用要高瞻远瞩
- 思考
软件过程
软件过程结构
- 将通信记录为正式文档
- 规划模块接口设计
- 在集成测试之前应该自行测试本人模块
- 代码审查(少用全局变量)
- 成立代码质量团队
- 集成测试,隔离不同模块的错误
- 软件架构师
- 规范更改会议
软件过程
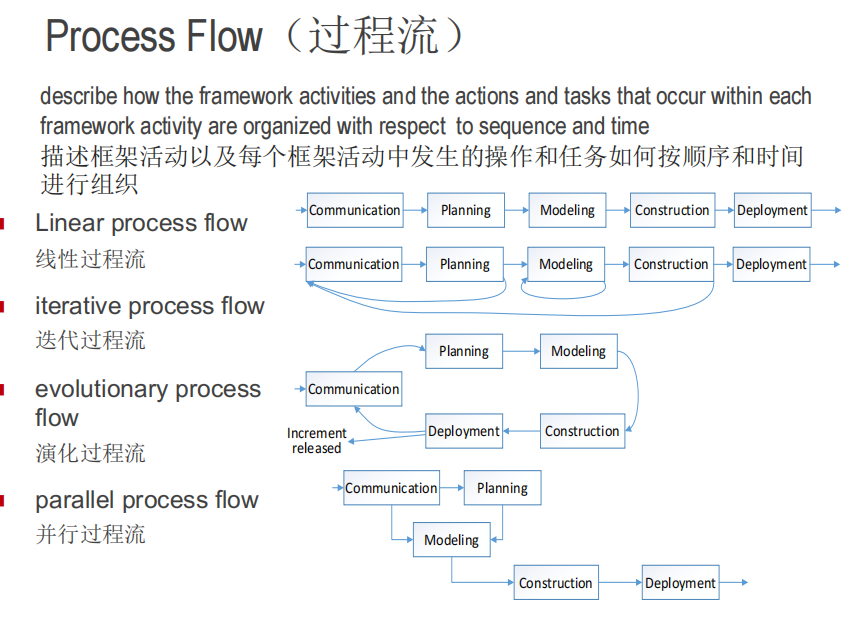
通用过程模型
过程模型
瀑布模型
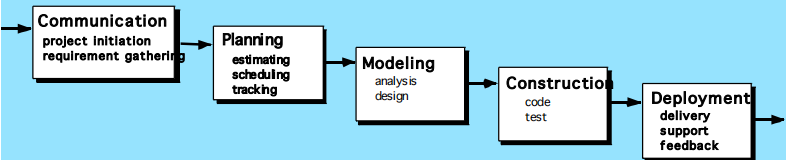
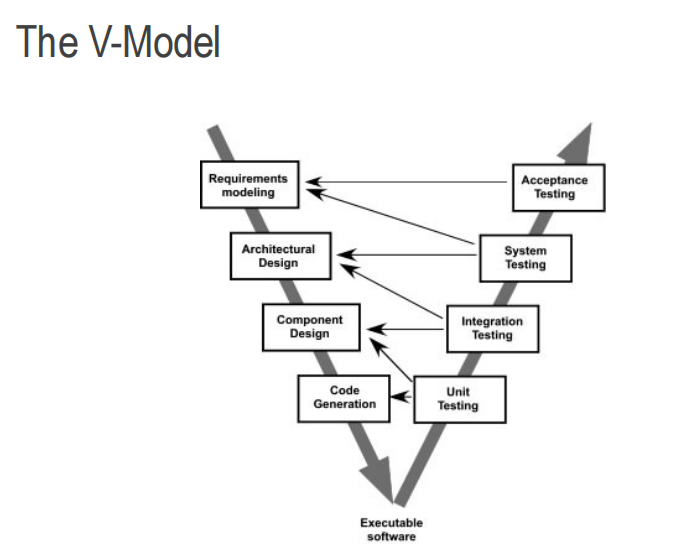
结构简单,强调软件开发过程的阶段性和顺序性,对软件开发管理严格,文档齐全,但早期无法发现缺陷,不适应需求经常发生变更的环境,要等很长时间才能得到最终产品。
增量过程模型 Incremental Process Model
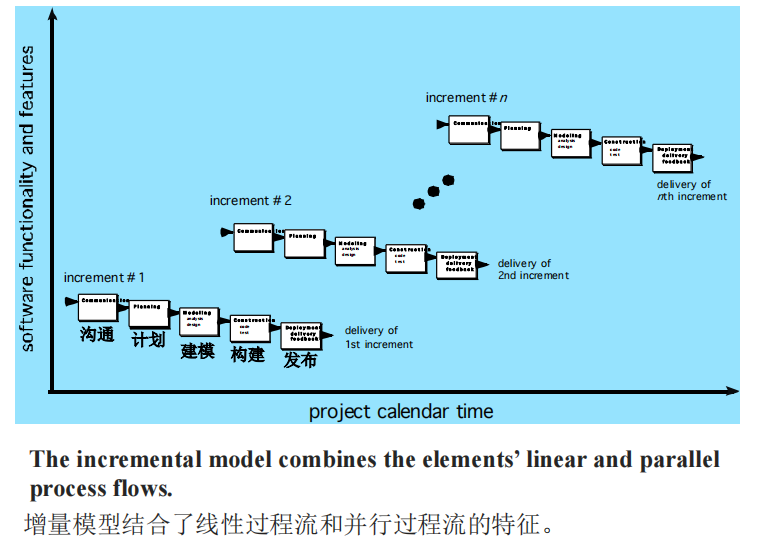
重要功能被首先交付,从而使得其得到最多的测试
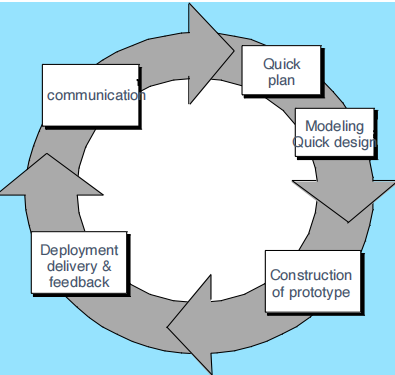
演化过程模型
Evolutionary Models: Prototyping 原型
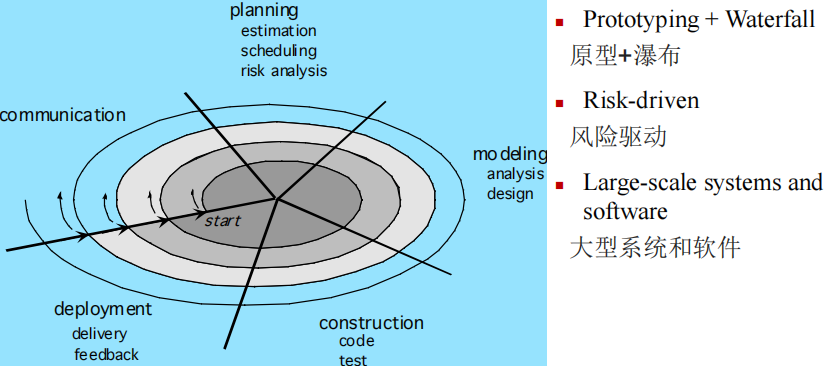
Evolutionary Models: The Spiral 螺旋