中昌国际建设集团网站登陆网站取消备案
说明:
- 面试群,群号: 228447240
- 面试题来源于网络书籍,公司题目以及博主原创或修改(题目大部分来源于各种公司);
- 文中很多题目,或许大家直接编译器写完,1分钟就出结果了。但在这里博主希望每一个题目,大家都要经过认真思考,答案不重要,重要的是通过题目理解所考知识点,好应对题目更多的变化;
- 博主与大家一起学习,一起刷题,共同进步;
- 写文不易,麻烦给个三连!!!
1.对称密钥加密的优点缺点?
答案:
对称密钥加密(Symmetric-Key Encryption),加密和解密使用同一密钥。
- 优点:运算速度快
- 缺点:无法安全地将密钥传输给通信方
2.非对称密钥加密你了解吗?优缺点?
答案:
非对称密钥加密,又称公开密钥加密(Public-Key Encryption),加密和解密使用不同的密钥。
公开密钥所有人都可以获得, 通信发送方获得接收方的公开密钥之后,就可以使用公开密钥进行加密, 接收方收到通信内容后使用私有密钥解密。
非对称密钥除了用来加密,还可以用来进行签名。因为私有密钥无法被其他人获取,因此通信发送方使用其私有密钥进行签名,通信接收方使用发送方的公开密钥对签名进行解密,就能判断这个签名是否正确。
- 优点:可以更安全地将公开密钥传输给通信发送方;
- 缺点:运算速度慢。
3.HTTPS是什么
答案:
HTTPS 并不是新协议,而是让 HTTP 先和 SSL ( Secure Sockets Layer )通信,再由 SSL 和 TCP 通 信,也就是说 HTTPS 使用了隧道进行通信。通过使用 SSL,HTTPS 具有了加密(防窃听)、认证(防伪装)和完整性保护(防篡改)。
4.HTTP的缺点有哪些?
答案:
- 使用明文进行通信,内容可能会被窃听;
- 不验证通信方的身份,通信方的身份有可能遭遇伪装;
- 无法证明报文的完整性,报文有可能遭篡改。
5.TCP对应的应用层协议
答案:
FTP:定义了文件传输协议,使用21端口.
Telnet:它是一种用于远程登陆的端口,23端口
SMTP:定义了简单邮件传送协议,服务器开放的是25号端口。
POP3:它是和SMTP对应,POP3用于接收邮件。
6.UDP对应的应用层协议
答案:
DNS:用于域名解析服务,用的是53号端口
SNMP:简单网络管理协议,使用161号端口
TFTP(Trival File Transfer Protocal):简单文件传输协议,69
7.可以解释一下RTO,RTT和超时重传分别是什么吗?
答案:
超时重传:发送端发送报文后若长时间未收到确认的报文则需要重发该报文。可能有以下几种情况:
- 发送的数据没能到达接收端,所以对方没有响应。
- 接收端接收到数据,但是ACK报文在返回过程中丢失。
- 接收端拒绝或丢弃数据。
RTO:从上一次发送数据,因为长期没有收到ACK响应,到下一次重发之间的时间。就是重传间隔。
- 通常每次重传RTO是前一次重传间隔的两倍,计量单位通常是RTT。例:1RTT,2RTT,4RTT,8RTT......
- 重传次数到达上限之后停止重传。
RTT:数据从发送到接收到对方响应之间的时间间隔,即数据报在网络中一个往返用时。大小不稳
定。
8.文件上传漏洞是如何发生的?你有经历过吗?
答案:
文件上传漏洞,指的是用户上传一个可执行的脚本文件,并通过此脚本文件获得了执行服务端命令的能力。
许多第三方框架、服务,都曾经被爆出文件上传漏洞,比如很早之前的Struts2,以及富文本编辑器等等,可被攻击者上传恶意代码,有可能服务端就被人黑了。
9.CSRF攻击?你知道吗?
答案:
跨站点请求伪造,指攻击者通过跨站请求,以合法的用户的身份进行非法操作。可以这么理解CSRF攻击:攻击者盗用你的身份,以你的名义向第三方网站发送恶意请求。CRSF能做的事情包括利用你的身份发邮件,发短信,进行交易转账,甚至盗取账号信息。
10.常见的HTTP状态码有哪些?
答案:
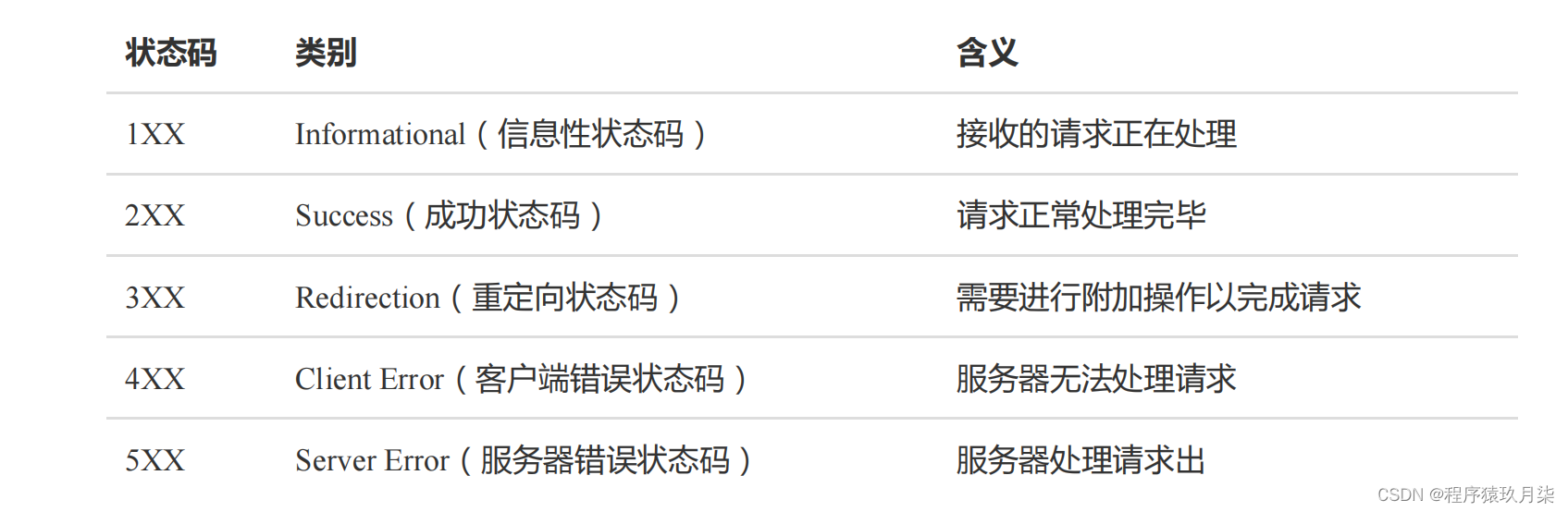
1xx 信息
100 Continue :表明到目前为止都很正常,客户端可以继续发送请求或者忽略这个响应。
2xx 成功
200 OK
204 No Content :请求已经成功处理,但是返回的响应报文不包含实体的主体部分。一般在只需要从客户端往服务器发送信息,而不需要返回数据时使用。
206 Partial Content :表示客户端进行了范围请求,响应报文包含由 Content-Range 指定范围的实体内容。
3xx 重定向
301 Moved Permanently :永久性重定向
302 Found :临时性重定向
303 See Other :和 302 有着相同的功能,但是 303 明确要求客户端应该采用 GET 方法获取资源。
304 Not Modified :如果请求报文首部包含一些条件,例如:If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since,如果不满足条件,则服务器会返回 304 状态码。
307 Temporary Redirect :临时重定向,与 302 的含义类似,但是 307 要求浏览器不会把重定向请求的 POST 方法改成 GET 方法。
4xx 客户端错误
400 Bad Request :请求报文中存在语法错误。
401 Unauthorized :该状态码表示发送的请求需要有认证信息(BASIC 认证、DIGEST 认证)。如果之前已进行过一次请求,则表示用户认证失败。
403 Forbidden :请求被拒绝。
404 Not Found。
5xx 服务器错误
500 Internal Server Error :服务器正在执行请求时发生错误。
503 Service Unavailable :服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。