长沙会议网站设计哪家专业自己怎么做外贸英文网站
博主介绍:
大家好,我是一名在Java圈混迹十余年的程序员,精通Java编程语言,同时也熟练掌握微信小程序、Python和Android等技术,能够为大家提供全方位的技术支持和交流。
我擅长在JavaWeb、SSH、SSM、SpringBoot等框架下进行项目开发,具有丰富的项目经验和开发技能。我的代码风格规范、优美、易读性强,同时也注重性能优化、代码重构等方面的实践和经验总结。
我有丰富的成品Java毕设项目经验,能够为学生提供各类个性化的开题框架和实际运作方案。同时我也提供相关的学习资料、程序开发、技术解答、代码讲解、文档报告等专业服务。🍅技术交流和部署相关看文章末尾!🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
Java项目精品实战案例(300套)
网吧管理系统源码下载地址:
https://download.csdn.net/download/weixin_54828627/87798371
一、效果演示
基于springboot+vue的网吧管理系统演示视频
二、前言介绍
随着信息技术和网络技术的飞速发展,人类已进入全新信息化时代,传统管理技术已无法高效,便捷地管理信息。为了迎合时代需求,优化管理效率,各种各样的管理系统应运而生,各行各业相继进入信息管理时代,网吧管理系统就是信息时代变革中的产物之一。
任何系统都要遵循系统设计的基本流程,本系统也不例外,同样需要经过市场进行调研,论文需求进行分析,概要设计,系统详细设计,测试和编码等步骤,设计并实现了网吧管理系统。系统选用B/S模式,应用java技术, MySQL为后台数据库。系统主要包括首页,个人中心,会员管理,网管管理,商品类型管理,商品信息管理,购买商品管理,呼叫网管管理,电脑信息管理,用户上机管理,用户下机管理等功能模块。
三、主要技术
| 技术名 | 作用 |
|---|---|
| SpringBoot | 后端框架 |
| Vue | 前端框架 |
| MySQL | 数据库 |
四、系统设计(部分)
4.1、主要功能模块设计

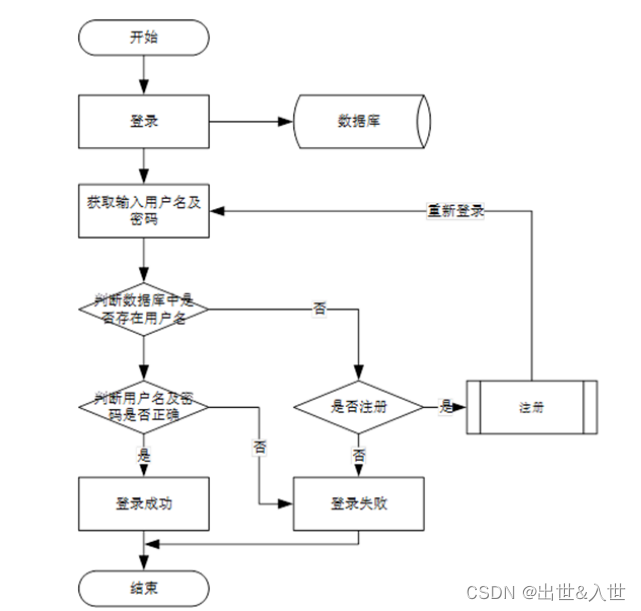
4.2、系统登录流程设计
五、功能截图
5.1、管理员功能模块
管理员登录进入系统可以查看首页,个人中心,会员管理,网管管理,商品类型管理,商品信息管理,购买商品管理,呼叫网管管理,电脑信息管理,用户上机管理,用户下机管理等功能,并进行详细操作,如图5-2所示。
 图5-2管理员功能界面图
图5-2管理员功能界面图
会员管理
 图5-3会员管理界面图
图5-3会员管理界面图
网管管理
 图5-4网管管理界面图
图5-4网管管理界面图
商品类型管理
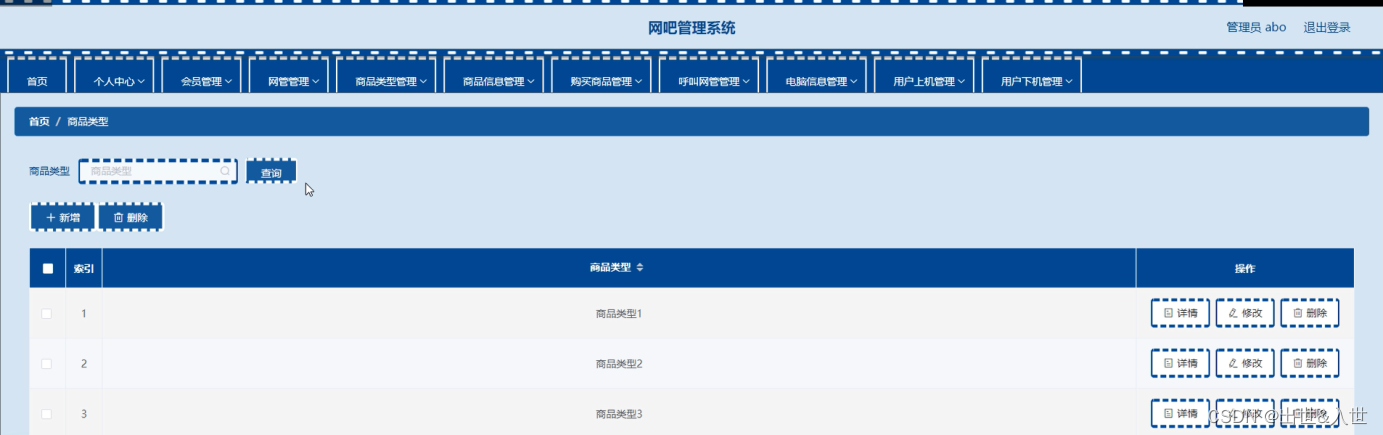 图5-5商品类型管理界面图
图5-5商品类型管理界面图
商品信息管理
 图5-6商品信息管理界面图
图5-6商品信息管理界面图
购买商品管理
 图5-7购买商品管理界面图
图5-7购买商品管理界面图
呼叫网管管理
 图5-8呼叫网管管理界面图
图5-8呼叫网管管理界面图
电脑信息管理
 图5-9电脑信息管理界面图
图5-9电脑信息管理界面图
用户上机管理
 图5-10用户上机管理界面图
图5-10用户上机管理界面图
用户下机管理
 图5-11用户下机管理界面图
图5-11用户下机管理界面图
5.2、网管功能模块
网管登录进入系统可以查看首页,个人中心,会员管理,商品信息管理,购买商品管理,呼叫网管管理,电脑信息管理,用户上机管理,用户下机管理等功能,并进行详细操作,如图5-12所示。
 图5-12网管功能界面图
图5-12网管功能界面图
购买商品管理
 图5-13购买商品管理界面图
图5-13购买商品管理界面图
呼叫网管管理
 图5-14呼叫网管管理界面图
图5-14呼叫网管管理界面图
电脑信息管理
 图5-15电脑信息管理界面图
图5-15电脑信息管理界面图
用户上机管理
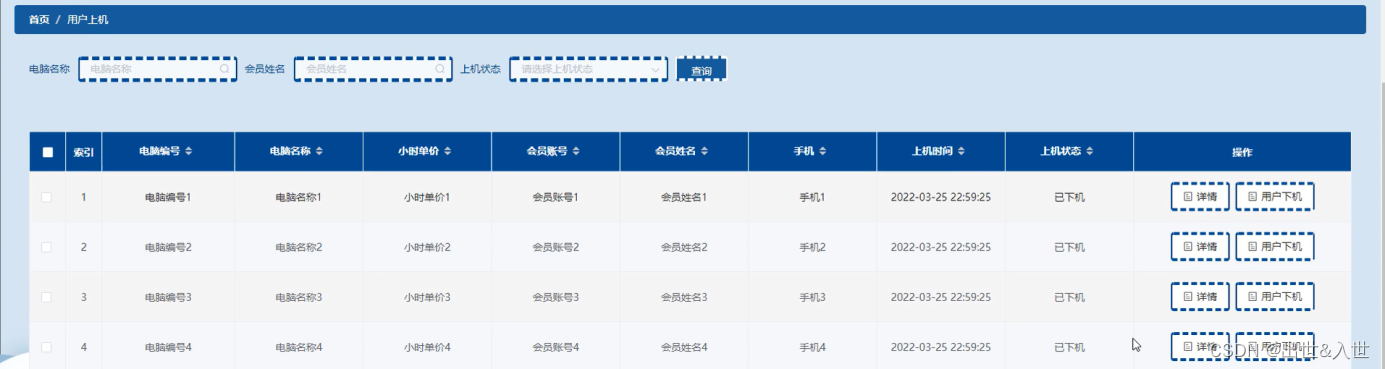 图5-16用户上机管理界面图
图5-16用户上机管理界面图
用户下机管理
 图5-17用户下机管理界面图
图5-17用户下机管理界面图
5.3、会员功能模块
会员登录进入系统可以查看首页,个人中心,商品信息管理,购买商品管理,呼叫网管管理,电脑信息管理,用户上机管理,用户下机管理等功能,并进行详细操作,如图5-18所示。
 图5-18会员功能界面图
图5-18会员功能界面图
这里功能太多,就不一一展示啦~
六、数据库设计(部分)
数据可设计要遵循职责分离原则,即在设计时应该要考虑系统独立性,即每个系统之间互不干预不能混乱数据表和系统关系。
数据库命名也要遵循一定规范,否则容易混淆,数据库字段名要尽量做到与表名类似,多使用小写英文字母和下划线来命名并尽量使用简单单词。
商品信息管理E/R图,如下所示:

图6-1商品信息管理E/R图
呼叫网管管理E/R图,如下所示:

图6-2呼叫网管管理E/R图
七、代码参考
package com.controller;import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Calendar;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;import javax.servlet.http.HttpServletRequest;import org.apache.commons.lang3.StringUtils;
import org.json.JSONObject;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.util.ResourceUtils;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;import com.annotation.IgnoreAuth;
import com.baidu.aip.face.AipFace;
import com.baidu.aip.face.MatchRequest;
import com.baidu.aip.util.Base64Util;
import com.baomidou.mybatisplus.mapper.EntityWrapper;
import com.entity.ConfigEntity;
import com.service.CommonService;
import com.service.ConfigService;
import com.utils.BaiduUtil;
import com.utils.FileUtil;
import com.utils.R;
/*** 通用接口*/
@RestController
public class CommonController{@Autowiredprivate CommonService commonService;private static AipFace client = null;@Autowiredprivate ConfigService configService; /*** 获取table表中的column列表(联动接口)* @param table* @param column* @return*/@IgnoreAuth@RequestMapping("/option/{tableName}/{columnName}")public R getOption(@PathVariable("tableName") String tableName, @PathVariable("columnName") String columnName,String level,String parent) {Map<String, Object> params = new HashMap<String, Object>();params.put("table", tableName);params.put("column", columnName);if(StringUtils.isNotBlank(level)) {params.put("level", level);}if(StringUtils.isNotBlank(parent)) {params.put("parent", parent);}List<String> data = commonService.getOption(params);return R.ok().put("data", data);}/*** 根据table中的column获取单条记录* @param table* @param column* @return*/@IgnoreAuth@RequestMapping("/follow/{tableName}/{columnName}")public R getFollowByOption(@PathVariable("tableName") String tableName, @PathVariable("columnName") String columnName, @RequestParam String columnValue) {Map<String, Object> params = new HashMap<String, Object>();params.put("table", tableName);params.put("column", columnName);params.put("columnValue", columnValue);Map<String, Object> result = commonService.getFollowByOption(params);return R.ok().put("data", result);}/*** 修改table表的sfsh状态* @param table* @param map* @return*/@RequestMapping("/sh/{tableName}")public R sh(@PathVariable("tableName") String tableName, @RequestBody Map<String, Object> map) {map.put("table", tableName);commonService.sh(map);return R.ok();}/*** 获取需要提醒的记录数* @param tableName* @param columnName* @param type 1:数字 2:日期* @param map* @return*/@IgnoreAuth@RequestMapping("/remind/{tableName}/{columnName}/{type}")public R remindCount(@PathVariable("tableName") String tableName, @PathVariable("columnName") String columnName, @PathVariable("type") String type,@RequestParam Map<String, Object> map) {map.put("table", tableName);map.put("column", columnName);map.put("type", type);if(type.equals("2")) {SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");Calendar c = Calendar.getInstance();Date remindStartDate = null;Date remindEndDate = null;if(map.get("remindstart")!=null) {Integer remindStart = Integer.parseInt(map.get("remindstart").toString());c.setTime(new Date()); c.add(Calendar.DAY_OF_MONTH,remindStart);remindStartDate = c.getTime();map.put("remindstart", sdf.format(remindStartDate));}if(map.get("remindend")!=null) {Integer remindEnd = Integer.parseInt(map.get("remindend").toString());c.setTime(new Date());c.add(Calendar.DAY_OF_MONTH,remindEnd);remindEndDate = c.getTime();map.put("remindend", sdf.format(remindEndDate));}}int count = commonService.remindCount(map);return R.ok().put("count", count);}/*** 单列求和*/@IgnoreAuth@RequestMapping("/cal/{tableName}/{columnName}")public R cal(@PathVariable("tableName") String tableName, @PathVariable("columnName") String columnName) {Map<String, Object> params = new HashMap<String, Object>();params.put("table", tableName);params.put("column", columnName);Map<String, Object> result = commonService.selectCal(params);return R.ok().put("data", result);}/*** 分组统计*/@IgnoreAuth@RequestMapping("/group/{tableName}/{columnName}")public R group(@PathVariable("tableName") String tableName, @PathVariable("columnName") String columnName) {Map<String, Object> params = new HashMap<String, Object>();params.put("table", tableName);params.put("column", columnName);List<Map<String, Object>> result = commonService.selectGroup(params);SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");for(Map<String, Object> m : result) {for(String k : m.keySet()) {if(m.get(k) instanceof Date) {m.put(k, sdf.format((Date)m.get(k)));}}}return R.ok().put("data", result);}/*** (按值统计)*/@IgnoreAuth@RequestMapping("/value/{tableName}/{xColumnName}/{yColumnName}")public R value(@PathVariable("tableName") String tableName, @PathVariable("yColumnName") String yColumnName, @PathVariable("xColumnName") String xColumnName) {Map<String, Object> params = new HashMap<String, Object>();params.put("table", tableName);params.put("xColumn", xColumnName);params.put("yColumn", yColumnName);List<Map<String, Object>> result = commonService.selectValue(params);SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");for(Map<String, Object> m : result) {for(String k : m.keySet()) {if(m.get(k) instanceof Date) {m.put(k, sdf.format((Date)m.get(k)));}}}return R.ok().put("data", result);}/*** (按值统计)时间统计类型*/@IgnoreAuth@RequestMapping("/value/{tableName}/{xColumnName}/{yColumnName}/{timeStatType}")public R valueDay(@PathVariable("tableName") String tableName, @PathVariable("yColumnName") String yColumnName, @PathVariable("xColumnName") String xColumnName, @PathVariable("timeStatType") String timeStatType) {Map<String, Object> params = new HashMap<String, Object>();params.put("table", tableName);params.put("xColumn", xColumnName);params.put("yColumn", yColumnName);params.put("timeStatType", timeStatType);List<Map<String, Object>> result = commonService.selectTimeStatValue(params);SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");for(Map<String, Object> m : result) {for(String k : m.keySet()) {if(m.get(k) instanceof Date) {m.put(k, sdf.format((Date)m.get(k)));}}}return R.ok().put("data", result);}/*** 人脸比对* * @param face1 人脸1* @param face2 人脸2* @return*/@RequestMapping("/matchFace")@IgnoreAuthpublic R matchFace(String face1, String face2,HttpServletRequest request) {if(client==null) {/*String AppID = configService.selectOne(new EntityWrapper<ConfigEntity>().eq("name", "AppID")).getValue();*/String APIKey = configService.selectOne(new EntityWrapper<ConfigEntity>().eq("name", "APIKey")).getValue();String SecretKey = configService.selectOne(new EntityWrapper<ConfigEntity>().eq("name", "SecretKey")).getValue();String token = BaiduUtil.getAuth(APIKey, SecretKey);if(token==null) {return R.error("请在配置管理中正确配置APIKey和SecretKey");}client = new AipFace(null, APIKey, SecretKey);client.setConnectionTimeoutInMillis(2000);client.setSocketTimeoutInMillis(60000);}JSONObject res = null;try {File path = new File(ResourceUtils.getURL("classpath:static").getPath());if(!path.exists()) {path = new File("");}File upload = new File(path.getAbsolutePath(),"/upload/");File file1 = new File(upload.getAbsolutePath()+"/"+face1);File file2 = new File(upload.getAbsolutePath()+"/"+face2);String img1 = Base64Util.encode(FileUtil.FileToByte(file1));String img2 = Base64Util.encode(FileUtil.FileToByte(file2));MatchRequest req1 = new MatchRequest(img1, "BASE64");MatchRequest req2 = new MatchRequest(img2, "BASE64");ArrayList<MatchRequest> requests = new ArrayList<MatchRequest>();requests.add(req1);requests.add(req2);res = client.match(requests);System.out.println(res.get("result"));} catch (FileNotFoundException e) {e.printStackTrace();return R.error("文件不存在");} catch (IOException e) {e.printStackTrace();} return R.ok().put("data", com.alibaba.fastjson.JSONObject.parse(res.get("result").toString()));}
}
八、技术交流
大家点赞、收藏、关注、评论啦 、查看文章结尾👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java项目精品实战案例(300套)