计算机网站建设 是什么培训网页

在MVC模式中,随着代码量越来越大,主要用来处理各种逻辑和数据转化的Controller首当其冲,变得非常庞大,MVC的简写变成了Massive-View-Controller(意为沉重的Controller)
我曾经接手老项目,springMVC + Hibernate技术栈,更能体现朴素的mvc,其中有些controller层代码8000+行,一个方法体1000+行。
在使用Hibernate\mybatisPlus\Spring data GPA这种完全的ORM框架、且不使用三层架构的项目中,controller过大这一缺点更加明显。因为了三层架构中service层分担业务逻辑。而由重量级ORM框架直接生成的service层只做与实体有关的、对实体数据部分的程序逻辑。
hibernate主要是要在controller通过前端http传来的参数动态拼接sql来处理逻辑,如果view的参数直接传到service处理,相当于直接和model接触了
-
MVC:
-
MVC+三层架构
所以有人想到把Controller的数据和逻辑处理部分从中抽离出来,用一个专门的对象去管理,这个对象就是ViewModel,。当人们去尝试这种方式时,发现Controller中的代码变得非常少,变得易于测试和维护,只需要Controller和ViewModel做数据绑定即可。
3.开发解耦(举两个例子):
a.一人负责逻辑实现、另一人负责UI实现;
b.敏捷开发时,会发经常发不是等后端做好了接口我们再去开发,不过在没有接口的情况下通常我们可以把Controller和View完成。
将整个前端页面分成View,Controller,Modal,视图上发生变化,通过Controller(控件)将响应传入到Model(数据源),由数据源改变View上面的数据。
通过数据来驱动视图,开发者只需要关心数据变化,DOM操作被封装了。
- 但这是mvvm的特性吗?封装dom?这么一来只有浏览器前端可以用mvvm了?
可以看到MVVM分别指View,Model,View-Model,View通过View-Model的DOM Listeners将事件绑定到Model上,而Model则通过Data Bindings来管理View中的数据,View-Model从中起到一个连接桥的作用。
一、ViewModel将改变传给Controller,Controller定位到需要修改的View部分并改变这部分
二、ViewModel包揽了Controller的数据处理功能之後,由于Controller的存在,原本的一个大视图的控制与处理,被Controller切割成了很多小的ViewModel和Model的编写问题,每一个View、ViewModel和Model组成了一个单独的单元,问题规模变小,问题就更容易处理了
三、数据绑定是,将视图中的某个小组件(View)、小组件的处理函数(ViewModel)、小组件相关的数据(Model)互相绑定起来。原本大Controller的处理是收到一个事件後,Controller需要从整个Model的顶端一层层下来,找到对应的数据进行计算,计算完成後,又从document对象上,一层层找下来,找到对应的小组件进行修改。每一个数据查找和视图修改操作,都需要从全局空间找下来。进行数据绑定之後,所有的这些都在局部空间操作,不再经过全局空间,所以代码看起来就舒服很多
- 分层的时候是不是不应只看到组件,而是从逻辑上把另一方的接口也算上?如数据层是数据库+缓存+实体,model的话还算上mapper操作和service逻辑
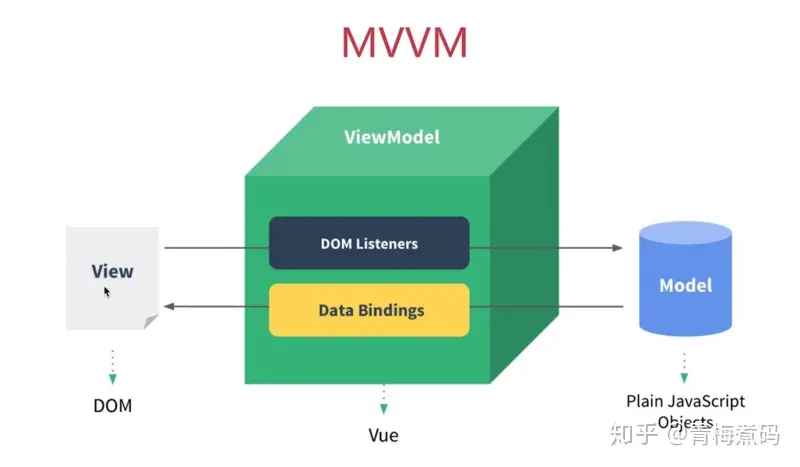
MVVM用ViewModel层代替了controller,
- mvvm目前只有B端资料
VUE实现原理
三个核心点:
- 响应式:vue如何监听data的属性变化
- 模板解析:vue的模板是如何被解析的
- 渲染:vue模板是如何被渲染成HTML的
响应式:
对于MVVM来说,data一般是放在一个对象当中,就比如这样:
var obj = {name: 'zhangsan',age: 25}
当我们访问或修改obj的属性的时候,比如:
console.log(obj.name) //访问obj.age = 22 //修改
但是这样的操作vue本身是没有办法感知到的,那么应该如何让vue知道我们进行了访问或是修改的操作呢?
那就要使用Object.defineProperty
var vm = {}var data = {name: 'zhangsan',age: 20}var key, valuefor (key in data) {(function (key) {Object.defineProperty(vm, key, {get: function () {console.log('get', data[key]) // 监听return data[key]},set: function (newVal) {console.log('set', newVal) // 监听data[key] = newVal}})})(key)}
通过Object.defineProperty将data里的每一个属性的访问与修改都变成了一个函数,在对象的getter和setter方法中我们即可监听到data的属性发生了改变。
模板解析
模板本质上是一串字符串,它看起来和html的格式很相像,实际上有很大的区别,因为模板本身还带有逻辑运算,比如v-if,v-for等等,但它最后还是要转换为html来显示。
<div id="app"><div><input v-model="title"><button v-on:click="add">submit</button></div><div><ul><li v-for="item in list">{{item}}</li></ul></div></div>
模板在vue中必须转换为JS代码,原因在于:在前端环境下,只有JS才是一个图灵完备语言,才能实现逻辑运算,以及渲染为html页面。
- 图灵完备语言
这里就引出了vue中一个特别重要的函数——render
render函数中的核心就是with函数。
with函数将某个对象添加到作用域链的顶部,如果在 statement中有某个未使用命名空间的变量,跟作用域链中的某个属性同名,则这个变量将指向这个属性值。
举个例子:
var obj = {name: 'zhangsan',age: 20,getAddress: function () {alert('beijing')}}function fn1() {with(obj) {alert(age)alert(name)getAddress()}}fn1()
with将obj这个对象放在了自己函数的作用域链的顶部,当执行下列函数时,就会自动到obj这个对象去寻找同名的属性。
而在render函数中,with的用法是这样:
<div id="app"><div><input v-model="title"><button v-on:click="add">submit</button></div><div><ul><li v-for="item in list">{{item}}</li></ul></div></div>
// 对应的js文件var data = {title: '',list: []}// 初始化 Vue 实例var vm = new Vue({el: '#app',data: data,methods: {add: function () {this.list.push(this.title)this.title = ''}}})with(this){ // this 就是 vmreturn _c('div',{attrs:{"id":"app"}},[_c('div',[_c('input',{directives:[{name:"model",rawName:"v-model",value:(title),expression:"title"}],domProps:{"value":(title)},on:{"input":function($event){if($event.target.composing)return;title=$event.target.value}}}),_v(" "),_c('button',{on:{"click":add}},[_v("submit")])]),_v(" "),_c('div',[_c('ul',_l((list),function(item){return _c('li',[_v(_s(item))])}))])])}
在一开始,因为new操作符,所以this指向了vm,通过with我们将vm这个对象放在作用域链的顶部,因为在函数内部我们会多次调用vm内部的属性,所以使用with可以缩短变量长度,提供系统运行效率。
其中的_c函数表示的是创建一个新的html元素,其基本用法为:
_c(element,{attrs},[children...])
其中的element表示所要创建的html元素类型,attrs表示所要创建的元素的属性,children表示该html元素的子元素。
_v函数表示创建一个文本节点,_l函数表示创建一个数组。
最终render函数返回的是一个虚拟DOM。
渲染为html
模板渲染为html分为两种情况,第一种是初次渲染的时候,第二种是渲染之后数据发生改变的时候,它们都需要调用updateComponent,其形式如下:
vm._update(vnode){const prevVnode = vm._vnodevm._vnode = vnodeif (!prevVnode){vm.$el = vm.__patch__(vm.$el,vnode)} else {vm.$el = vm.__patch__(prevVnode,vnode)}
}function updateComponent(){vm._update(vm._render())
}
首先读取当前的虚拟DOM——vm._vnode,判断其是否为空,若为空,则为初次渲染,将虚拟DOM全部渲染到所对应的容器当中(vm.$el),若不为空,则是数据发生了修改,通过响应式我们可以监听到这一情况,使用diff算法完成新旧对比并修改。
拓展
更新节点
Vue 节点中更新节点内容,可以使用两种方式:
- 在组件内部监听节点事件,在外部触发事件。
- 使用
Pinan,Vuex等状态管理器