海外短视频怎么下载seo综合查询怎么进入网站
最近小编有收到一些用户问“光引擎、光模块、光器件之间的关系和区别?”,众所周知光通信技术一直在不断演进,为满足不断增长的数据传输需求提供了强大的解决方案。而光通信系统中,光引擎、光模块和光器件是关键的组成部分,它们各自扮演着不同的角色,具有独特的功能和特点。在本文中,我们将解答该用户的疑惑,探讨这三者之间的关系和区别。
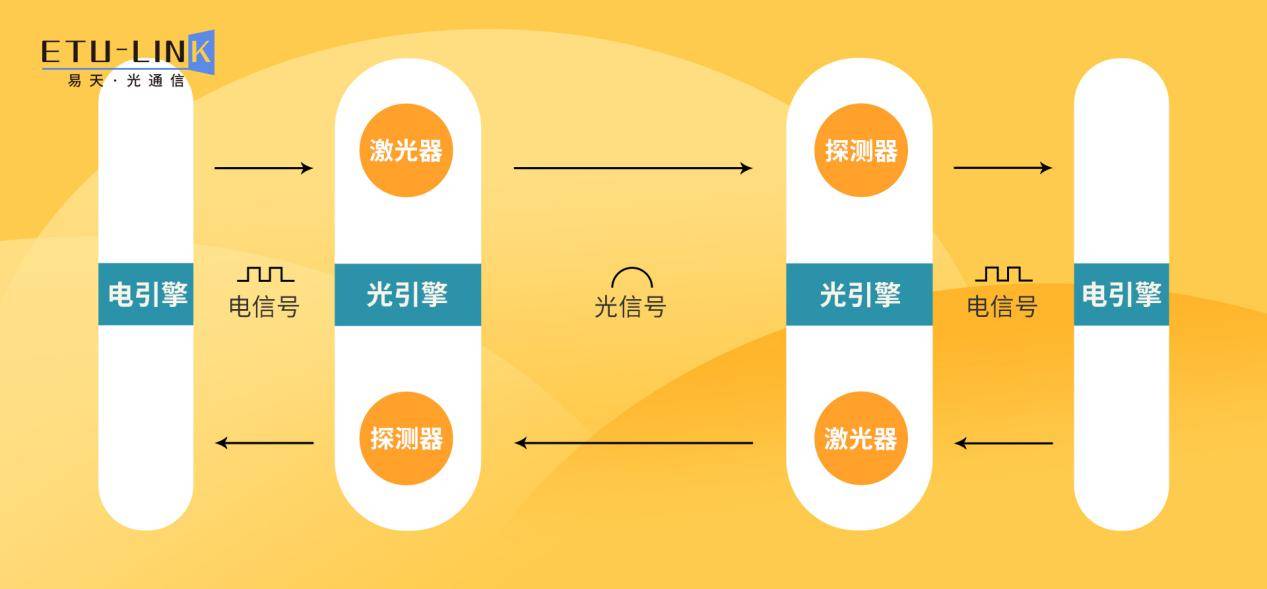
光引擎(Optical Engine)
光引擎是光通信系统中实现光信号转换的核心部件,也可以说是一个整体的光学子系统,一般会由多个光器件组成,用于实现光信号的收发、传输和处理。光引擎通常由一个激光二极管和一个调制器组成,其中激光二极管负责产生激光,而调制器则将电信号转换为光信号。在光通信系统中,光引擎的性能对整个系统的传输质量和速率有着直接的影响。
光器件(Optical Device)
光器件是光通信系统中实现光信号产生、调制、探测和放大等功能的元件。常见的光器件包括激光器、调制器、探测器、放大器等,是制造和生产光模块离不开的伙伴。光器件通常是在光芯片或光模块中使用的。同时光器件也是构成光引擎和光模块的基本组成部分,能够对光信号进行处理或转换的装置。一枚小小的光器件也是蕴含着巨大能力的,这些器件的性能对光通信系统的传输质量、速率和稳定性都有一定的影响。例如,激光器是一种产生激光光源的光器件,调制器是一种可以调制光信号的光器件,探测器是一种可以将光信号转换为电信号的光器件。
光模块(Optical Module)
最后我们来看看光模块,我们都知道光模块主要由外壳、光器件、集成电路板等组成,光器件又包括发射和接收两部分。光模块的作用通俗的说就是发送端把电信号转换成光信号,通过光纤传送后,接收端再把光信号转换成电信号,以便进一步处理。其次光模块的性能对于光通信系统的传输距离和稳定性也有着至关重要的影响。
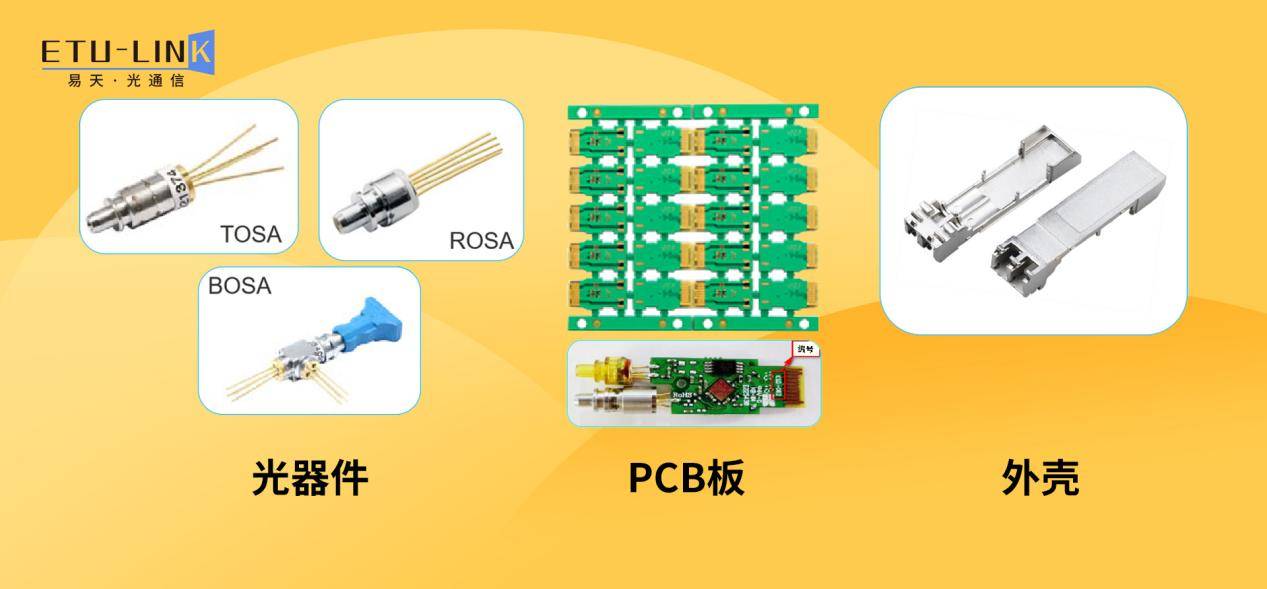
综上所述,可以这样理解光器件是构建光引擎和光模块的基本组件。三者在光通信系统中具有不同的功能和角色。光引擎是高度集成的光子器件,光模块是更广义的光学和电学组件,而光器件是独立的元件,用于处理和控制光信号。它们也将共同推动着光通信技术的不断发展,为我们的数字世界提供了更快速、更可靠的数据传输解决方案。
关于易天
易天光通信(ETU-LINK)作为光模块、DAC和AOC领域的领军生产厂家,倾心耕耘于此近十载。我们引以为傲的不仅是作为一家高新技术企业的荣誉,更是我们在光模块领域所累积的丰富经验和卓越成就。通过不懈的努力与心怀创新的信心,我们在行业内独树一帜。无论是在技术创新还是产品品质上,我们始终坚持追求卓越,为客户提供卓越的光通信解决方案。本期文章内容到这里就结束了,记得点个赞和在看哟~