手机网站开发技术pdf营销活动
项目介绍
餐饮行业是一个传统的行业。根据当前发展现状,网络信息时代的全面普及,餐饮行业也在发生着变化,单就点餐这一方面,利用手机点单正在逐步进入人们的生活。传统的点餐方式,不仅会耗费大量的人力、时间,有时候还会出错。小程序系统伴随智能手机为我们提供了新的方向。手机点餐小程序的实现,首先服务员可以根据点餐小程序系统确认点餐,并且根据账单来计算提成;其次餐厅管理人员可以根据订单记录,提前采购,提高顾客的满意度,而且更便于对员工的管理。这款基于小程序的点餐小程序的设计与实现将会使点餐小程序操作更加自如。本文通过对国内外现状的分析,明确了点餐小程序在国内外的基本情况,对系统的功能需求做出分析,此系统是由用户下单,并且完成付款,生成订单;管理端可以查看每天的订单,并且可以对菜品分类管理、菜品管理、订单管理、系统管理进行操作。根据需求对系统进行设计,明确各个部分的规范,来完成系统的设计。最后在对设计的系统进行一系列的测试,是系统达到预期要求,再对系统进行进一步的完善。
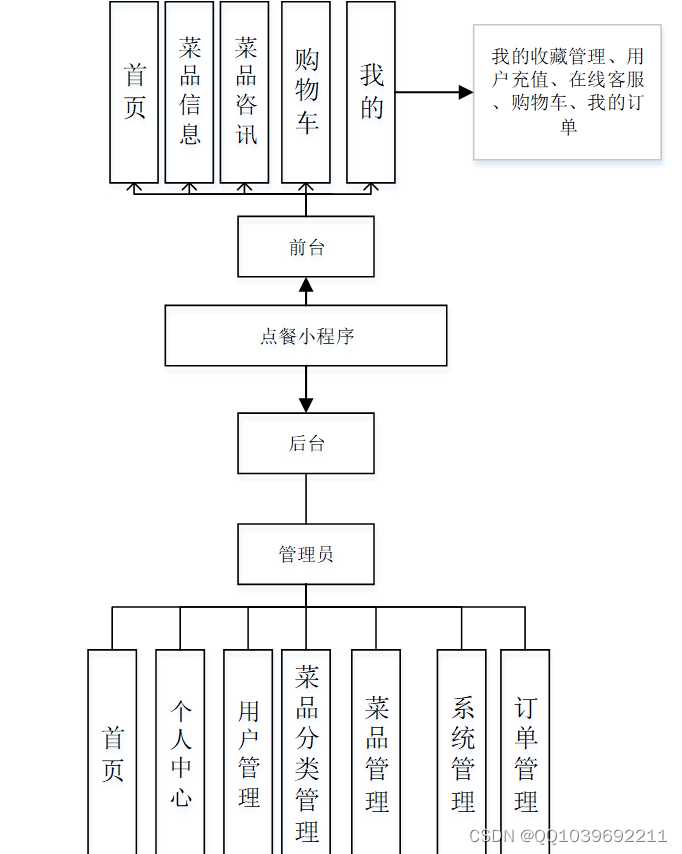
系统模块分析是对系统的各个模块做出相应的说明以及解释。此系统的模块分别有用户模块、服务端模块和管理端模块这两大基本模块,其中服务端模块包括了首页、菜品信息、菜品咨讯、购物车、我的等;而管理端模块则包括了个人中心、用户管理、菜品分类管理、菜品管理、、系统管理、订单管理等
开发环境
开发说明:前端使用微信微信小程序开发工具;后端使用springboot+VUE开发
开发语言:Java
开发工具:IDEA /Eclipse/微信小程序开发工具
数据库:MYSQL5.7或以上
应用服务:Tomcat8或以上
功能介绍
管理端登录之后,进入主界面,可以对首页、个人中心、用户管理、菜品分类管理、菜品管理、系统管理、订单管理等功能进行操作
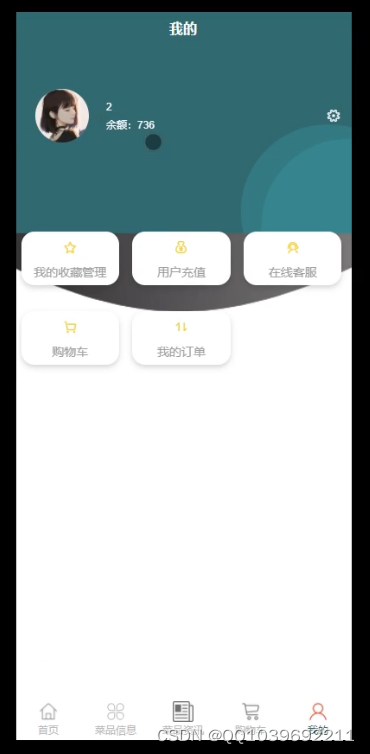
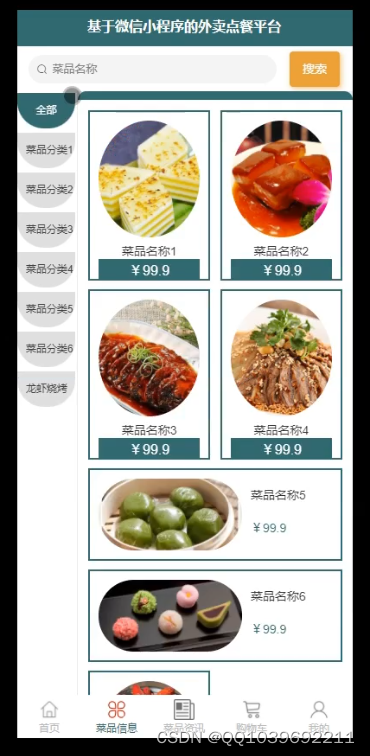
服务端登录之后,进入主界面,可以实现首页、菜品信息、购物车、我的等,在我的页面可以对我的收藏管理、用户充值、在线客服、购物车、我的订单、功能进行操作
效果图

目 录
1绪论 1
1.1项目研究的背景 1
1.2开发意义 1
1.3项目研究现状及内容 5
1.4论文结构 5
2开发技术介绍 7
2.1 B/S架构 7
2.2 MySQL 介绍 7
2.3 MySQL环境配置 7
2.4 Java语言简介 8
2.5微信小程序技术 8
3系统分析 9
3.1可行性分析 9
3.1.1技术可行性 9
3.1.2经济可行性 9
3.1.3操作可行性 10
3.2网站性能需求分析 10
3.3网站功能分析 10
3.4系统流程的分析 11
3.4.1 用户管理的流程 12
3.4.2 个人中心管理流程 13
3.4.3 登录流程 13
4系统设计 14
4.1 软件功能模块设计 14
4.2 数据库设计 13
4.2.1 概念模型设计 13
4.2.2 物理模型设计 15
5系统详细设计 21
5.1系统前台功能模块 21
5.2管理员功能模块 24
6系统测试 30
7总结与心得体会 33
7.1 总结 33
7.2 心得体会 33
参考文献 35