德文网站建设正规网站建设公司多少钱
目录
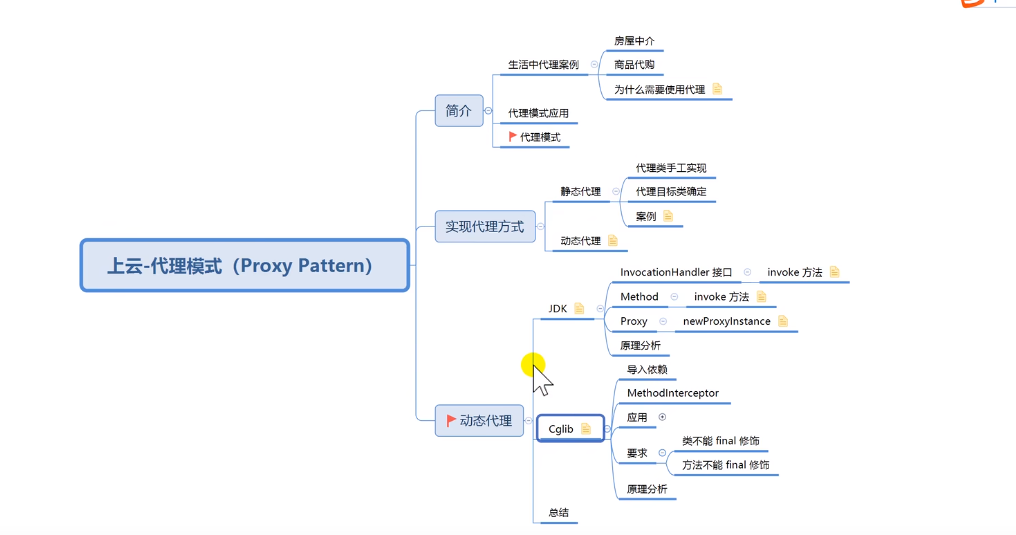
- 一、代理模式
- 1、生活中代理案例
- 2、为什么要使用代理
- 3、代理模式在Java中的应用
- 4、什么是代理模式
- 二、代理的实现方式
- 1、java中代理图示
- 2、静态代理
- 三、动态代理
- 1、概述
- 2、JDK动态代理
- ==jdk动态代理原理分析==
- 3、Cglib动态代理
- 3.1 基本使用
- 3.2 cglib基本原理
一、代理模式
1、生活中代理案例
- 房屋中介
- 商品代购
2、为什么要使用代理
对于消费者而言,可以减少成本,只需要关心自己需要的商品,不需要去寻找渠道或者房源
3、代理模式在Java中的应用
- 统一异常处理
- MyBatis
- Spring AOP
- 日志框架
4、什么是代理模式
代理模式(proxy pattern): 是23种设计模式中的一种,属于结构型的模式。
意义:目标对象只需要关系自己的实现细节,通过代理对象来实现功能的增强,可以扩展目标对象的功能
体现了非常重要的编程思想,不能随便修改源码,通过代理的方式来拓展
二、代理的实现方式
1、java中代理图示
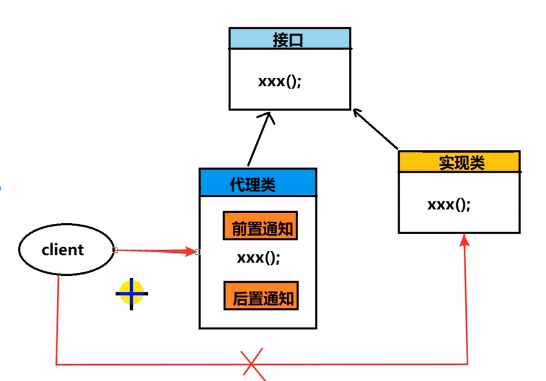
元素:
- 接口
- 接口实现类
- 代理类
2、静态代理
详细见连接中的静态代理:https://blog.csdn.net/hc1285653662/article/details/127199791
静态代理存在的问题
- 不利于代码的扩展,比如接口中新添加一个抽象方法,所有的实现类都需要做修改
- 代理对象需要创建许多
三、动态代理
1、概述
在不改变原有功能代码的前提下,能够动态的实现方法的增强
2、JDK动态代理
详细见连接中的动态代理:https://blog.csdn.net/hc1285653662/article/details/127199791
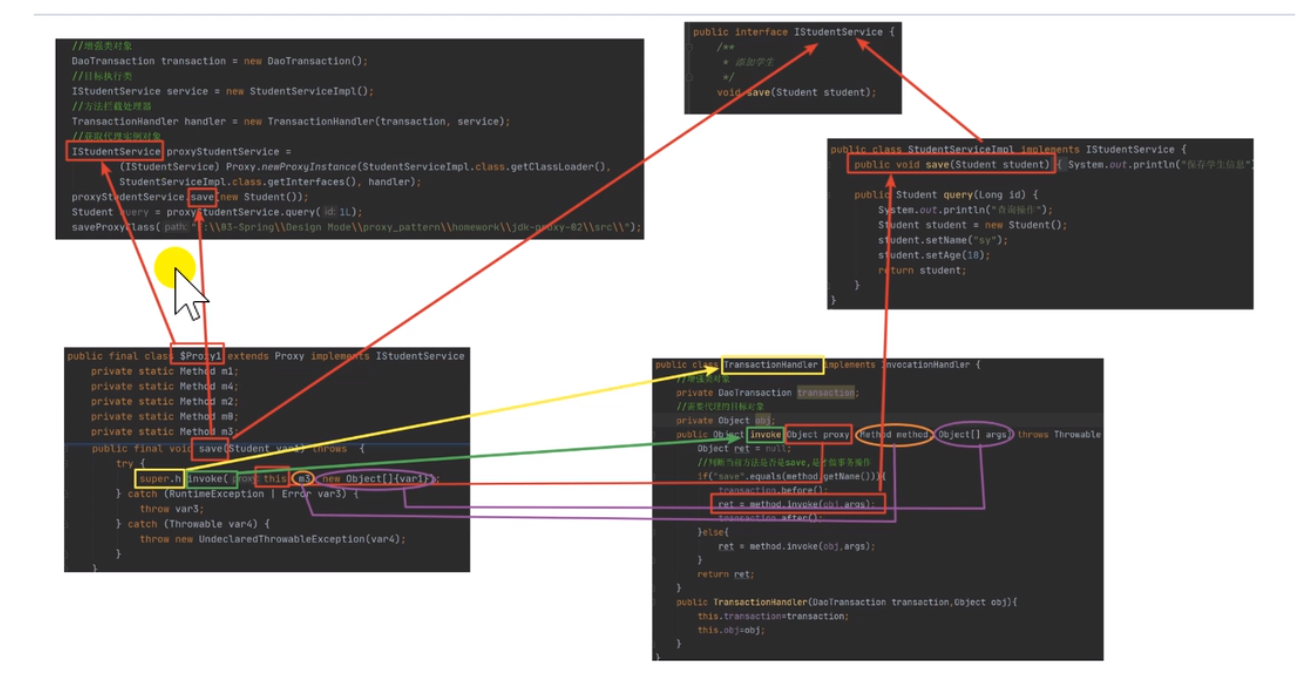
jdk动态代理原理分析
- 生成代理类的字节码
/*** 生成代理类的字节码文件* @param path*/public static void saveProxyClass(String path) {byte[] $Proxy1s = ProxyGenerator.generateProxyClass("$Proxy1",Calculator.class.getInterfaces());FileOutputStream out = null;try {out = new FileOutputStream(path + "$Proxy1.class");out.write($Proxy1s);} catch (IOException e) {throw new RuntimeException(e);} finally {try {out.flush();out.close();} catch (IOException e) {throw new RuntimeException(e);}}}
- 生成字节码反编译结果
public final class $Proxy1 extends Proxy implements Calculate {private static Method m1;private static Method m2;private static Method m3;private static Method m0;public $Proxy1(InvocationHandler var1) throws {super(var1);}public final boolean equals(Object var1) throws {try {return (Boolean)super.h.invoke(this, m1, new Object[]{var1});} catch (RuntimeException | Error var3) {throw var3;} catch (Throwable var4) {throw new UndeclaredThrowableException(var4);}}public final String toString() throws {try {return (String)super.h.invoke(this, m2, (Object[])null);} catch (RuntimeException | Error var2) {throw var2;} catch (Throwable var3) {throw new UndeclaredThrowableException(var3);}}public final int add(int var1, int var2) throws {try {return (Integer)super.h.invoke(this, m3, new Object[]{var1, var2});} catch (RuntimeException | Error var4) {throw var4;} catch (Throwable var5) {throw new UndeclaredThrowableException(var5);}}public final int hashCode() throws {try {return (Integer)super.h.invoke(this, m0, (Object[])null);} catch (RuntimeException | Error var2) {throw var2;} catch (Throwable var3) {throw new UndeclaredThrowableException(var3);}}static {try {m1 = Class.forName("java.lang.Object").getMethod("equals", Class.forName("java.lang.Object"));m2 = Class.forName("java.lang.Object").getMethod("toString");m3 = Class.forName("com.houchen.staticproxy.Calculate").getMethod("add", Integer.TYPE, Integer.TYPE);m0 = Class.forName("java.lang.Object").getMethod("hashCode");} catch (NoSuchMethodException var2) {throw new NoSuchMethodError(var2.getMessage());} catch (ClassNotFoundException var3) {throw new NoClassDefFoundError(var3.getMessage());}}
}- 执行原理图
3、Cglib动态代理
- jdk动态代理有个前提:需要被代理的类必须实现接口,如果被代理类没有实现接口,则只能通过CGLIB来实现
3.1 基本使用
- 导入依赖
<dependency><groupId>cglib</groupId><artifactId>cglib</artifactId><version>2.2.2</version></dependency>
- 实现方法拦截
public class MyInvocationHandler implements InvocationHandler {private Object target = null;//动态代理,目标对象是活动的,不是固定的,需要传入进来public MyInvocationHandler(Object target) {this.target = target;}@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {System.out.println("代理对象中进行功能增强 start....");Object res = method.invoke(target, args);System.out.println("代理对象中进行功能增强 end ....");return res;}
}
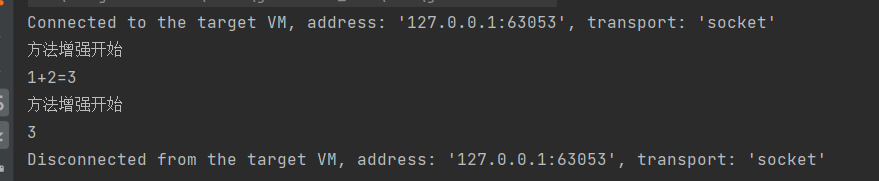
- 测试方法
public class Test {public static void main(String[] args) {// 得到方法拦截器CglibInterceptor cglibInterceptor = new CglibInterceptor();// 使用CGLIB框架生成目标类的子类(代理类)实现增强Enhancer enhancer = new Enhancer();// 设置父类字节码文件enhancer.setSuperclass(Calculator.class);// 设置拦截处理enhancer.setCallback(cglibInterceptor);// 创建代理对象Calculator proxy = (Calculator) enhancer.create();int add = proxy.add(1, 2);System.out.println(add);}
}
3.2 cglib基本原理
- 生成cglib的目标代理类对象
public class Test {public static void main(String[] args) {// 生成cglib的目标代理类对象System.setProperty(DebuggingClassWriter.DEBUG_LOCATION_PROPERTY,"E:\\Code\\JavaSE\\ProxyModeTest\\src");// 得到方法拦截器CglibInterceptor cglibInterceptor = new CglibInterceptor();// 使用CGLIB框架生成目标类的子类(代理类)实现增强Enhancer enhancer = new Enhancer();// 设置父类字节码文件enhancer.setSuperclass(Calculator.class);// 设置拦截处理enhancer.setCallback(cglibInterceptor);// 创建代理对象Calculator proxy = (Calculator) enhancer.create();int add = proxy.add(1, 2);System.out.println(add);}
}