网站策划方案详解深圳商城网站哪家做的好
引言
随着区块链技术的不断发展,智能合约和分布式应用(DApps)逐渐成为数字经济中的重要组成部分。智能合约是一种自执行的协议,能够在预设条件满足时自动执行代码,而无需人工干预或中介机构。这种自动化和信任机制极大地提升了交易和合同执行的效率和安全性。分布式应用(DApps)则是基于区块链技术构建的去中心化应用程序,具有去中心化、透明和抗审查等特点,能够提供更可靠和公平的服务。
在现代数字经济中,智能合约和DApps的应用日益广泛。它们不仅在金融领域中发挥着重要作用,如去中心化金融(DeFi)平台的建设,还在供应链管理、医疗健康和公共服务等各行业中展现出巨大的潜力。智能合约和DApps的结合,使得业务流程自动化、数据透明和安全性大幅提升,从而推动了整个数字经济的发展和创新。
本文旨在探讨智能合约和分布式应用的基本概念、技术架构及其在各行业中的实际应用。首先,我们将介绍智能合约和DApps的定义和技术基础,随后分析二者的结合及其管理系统的必要性和实现方式。接着,我们将通过具体案例,展示智能合约和DApps在金融、供应链、医疗和公共服务等领域的应用。最后,本文将总结当前面临的技术挑战,提出可能的解决方案,并展望未来的发展趋势。通过全面的分析和研究,希望为读者提供深入的见解,助力智能合约和DApps技术的进一步发展和应用。
一、智能合约概述
智能合约是一种自执行的数字协议,其条款和执行步骤被直接写入代码中。智能合约在预设条件满足时自动执行,从而实现合同的自动化和去中介化。智能合约的基本功能包括:
自动执行:智能合约在预设条件达到时自动执行,无需人为干预。
条件触发:智能合约根据预先设定的条件和规则触发执行,可以包括时间、事件或外部数据的变化。
不可篡改:一旦智能合约部署在区块链上,其代码和数据是不可篡改的,确保了执行的可信性和公正性。
去中介化:智能合约消除了对中介机构的依赖,降低了交易成本和信任风险。
1、智能合约的技术基础:区块链技术的支持
智能合约依赖于区块链技术的支持。区块链是一种分布式账本技术,具有去中心化、透明性和不可篡改的特点,为智能合约的执行提供了安全和可靠的环境。智能合约与区块链的结合,主要体现在以下几个方面:
去中心化账本:智能合约部署在去中心化的区块链网络上,没有单一的控制中心,确保了合约的执行不受个别节点的控制和干扰。
共识机制:区块链采用的共识机制(如PoW、PoS等)确保了网络中各节点对智能合约执行结果的共识,从而保证了合约执行的准确性和一致性。
加密技术:区块链使用先进的加密技术保护智能合约的数据和执行流程,防止未经授权的访问和篡改。
透明性和可追溯性:区块链上的所有交易和智能合约执行记录都是公开和可追溯的,提高了系统的透明度和信任度。
2、智能合约的优势:自动化、透明性、安全性
智能合约在自动化、透明性和安全性方面具有显著优势,这些优势使其在多种应用场景中得以广泛应用。
自动化:智能合约的自动执行功能消除了人工干预的需要,显著提高了效率和速度,减少了人为错误和操作成本。例如,在金融领域,智能合约可以实现自动支付、自动结算等功能,提高金融交易的效率和准确性。
透明性:智能合约的代码和执行记录公开透明,所有参与方都可以查看合约条款和执行状态。这种透明性增强了合约执行的可信度,防止了信息不对称和欺诈行为。比如,在供应链管理中,智能合约可以提供透明的物流跟踪和验证,提升供应链的可视性和信任度。
安全性:智能合约基于区块链技术的加密保障和去中心化特性,使其具有很高的安全性和抗篡改能力。智能合约的不可篡改性和共识机制确保了合约执行的准确性和公正性。在医疗健康领域,智能合约可以保护患者数据的隐私和安全,确保医疗信息的准确传递和管理。
智能合约的这些优势,使其在金融、供应链管理、医疗健康、公共服务等多个领域具有广泛的应用前景。通过结合区块链技术,智能合约不仅能够提升业务流程的自动化和透明度,还能提供强有力的安全保障,推动各行业的数字化和智能化发展。
二、分布式应用(DApps)概述
分布式应用(Decentralized Applications,简称DApps)是指运行在去中心化网络上的应用程序,通常依赖于区块链技术。DApps的主要特点包括:
去中心化:DApps运行在区块链网络的各个节点上,而不是集中在单一的服务器上,避免了单点故障和控制问题。
公开透明:DApps的代码和交易记录是公开的,任何人都可以查看和验证,这增强了应用的透明度和信任度。
不可篡改:一旦DApps的代码和数据被记录在区块链上,就无法被篡改,保证了数据的完整性和安全性。
自主运行:DApps依赖于智能合约来自动执行预定的逻辑,无需人工干预,确保了应用的连续性和可靠性。
1、DApps与传统应用的区别
DApps与传统应用在架构和运行机制上存在显著差异:
中心化 vs. 去中心化:传统应用依赖于集中式服务器,数据和应用逻辑都由中心服务器控制和管理。而DApps运行在去中心化的区块链网络上,没有单一控制中心。
数据控制权:在传统应用中,数据由应用所有者控制,用户对数据的掌控有限。而在DApps中,用户对自己的数据拥有更多的控制权,数据存储在区块链上,公开透明且不可篡改。
安全性:传统应用易受单点故障和黑客攻击的影响,而DApps由于其去中心化和加密技术,具备更高的安全性和抗攻击能力。
信任机制:传统应用需要用户信任中心服务器和运营者,而DApps通过区块链和智能合约的透明性和自动化,减少了对第三方的信任依赖。
2、DApps的技术架构:区块链、智能合约、去中心化存储
DApps的技术架构主要由以下三个核心组件构成:
(1)区块链
去中心化账本:区块链是DApps的基础,提供了去中心化的账本记录所有交易和数据。区块链的共识机制确保了数据的准确性和一致性,防止篡改和欺诈。
安全性:区块链使用加密技术保护数据的安全性和隐私性,确保只有授权方才能访问和操作数据。
(2)智能合约
自动执行:智能合约是运行在区块链上的自执行代码,自动执行预定的逻辑和条件,确保应用的自主运行。
透明和可信:智能合约的代码和执行记录公开透明,任何人都可以查看和验证,增强了应用的信任度。
(3)去中心化存储
数据存储:DApps需要存储大量数据,去中心化存储解决方案(如IPFS、Swarm等)提供了分布式的数据存储服务,确保数据的可用性和安全性。
数据共享:去中心化存储允许数据在网络中的多个节点间共享和访问,避免了单点存储的风险。
DApps通过结合区块链、智能合约和去中心化存储,构建了一个去中心化、透明和安全的应用环境。这种技术架构不仅消除了传统应用的单点故障和数据控制问题,还提高了应用的信任度和抗攻击能力。DApps的这些特性,使其在金融、供应链管理、医疗健康和公共服务等领域展现出巨大的潜力和应用前景。通过不断的发展和创新,DApps有望推动各行业的数字化转型和智能化升级。
三、智能合约和DApps的结合
智能合约和分布式应用(DApps)的结合代表了区块链技术在应用层面的深度融合,不仅增强了应用程序的自动化和透明性,还推动了去中心化应用生态系统的发展。
1、智能合约在DApps中的应用:案例分析
(1)去中心化金融(DeFi)平台
案例:MakerDAO
应用:MakerDAO使用智能合约来创建去中心化的稳定币Dai,通过智能合约自动管理抵押品,保持Dai的价值稳定。用户可以通过DApps存入加密资产作为抵押品,生成Dai。
优势:自动化管理、透明性和去中介化,使得借贷过程更高效和可信。
(2)供应链管理
案例:VeChain
应用:VeChain通过智能合约和DApps实现供应链全程的可追溯性。从原材料采购到生产、运输、销售,每个环节的数据都被记录在区块链上,确保产品信息的透明和可信。
优势:增强供应链的透明度和可信度,有助于防伪和质量控制。
(3)医疗健康
案例:MedRec
应用:MedRec使用智能合约和DApps管理患者的电子健康记录(EHR)。智能合约自动处理访问权限,确保只有授权人员才能访问患者数据。
优势:提升数据隐私和安全性,简化医疗数据的共享和管理。
(4)公共服务
案例:Aid
应用:Aid
利用智能合约和DApps实现透明和高效的社会福利分发。通过智能合约自动执行福利发放,确保资金流向符合条件的受益人。
优势:减少腐败和欺诈,确保资金分配的透明和高效。
2、实现智能合约与DApps的交互:技术实现和挑战
(1)技术实现
智能合约部署:将智能合约部署到区块链网络上,智能合约的代码和状态存储在区块链中。
前端DApp:DApp的前端通常使用Web3.js等库与区块链交互,通过调用智能合约的接口实现功能。
后端支持:DApps的后端服务器用于处理复杂逻辑和数据存储,通过API与前端和区块链进行通信。
钱包集成:用户通过数字钱包(如MetaMask)与DApp交互,管理私钥和签署交易。
(2)挑战
性能瓶颈:区块链的交易处理速度和扩展性限制了DApps的性能,需要优化智能合约和链下处理。
安全性:智能合约代码的漏洞和攻击风险高,需进行严格的安全审计和测试。
用户体验:区块链交易的确认时间和费用可能影响用户体验,需要改进界面和交互设计。
互操作性:不同区块链平台之间的互操作性差,影响了DApps的广泛应用,需要跨链技术的支持。
3、优化智能合约和DApps的结合:性能提升和安全保障
(1)性能提升
Layer 2 解决方案:使用侧链、状态通道和Rollup等技术,将部分交易移到链下处理,提高处理速度和扩展性。
链下计算:将复杂计算和大数据处理移到链下,通过链下计算和链上验证相结合,提升效率。
分片技术:通过分片技术将区块链网络分成多个小片并行处理交易,提升整体性能。
(2)安全保障
智能合约审计:定期进行专业的智能合约代码审计,发现并修复潜在漏洞。
形式化验证:使用形式化验证工具对智能合约进行数学证明,确保合约逻辑的正确性。
安全开发流程:采用安全开发生命周期(SDL),在开发过程中引入安全评估和测试。
多重签名机制:引入多重签名机制,增强智能合约的安全性和交易确认的可靠性。
通过优化智能合约和DApps的结合,可以提升其性能和安全性,确保在实际应用中的可靠性和用户体验。这些优化措施不仅推动了智能合约和DApps的技术进步,也促进了其在各行业中的广泛应用和普及。
四、智能合约和DApps的管理系统
智能合约和分布式应用(DApps)的管理系统是确保这些复杂系统安全运行的关键。它涵盖了部署管理、版本控制、安全监控和性能优化等核心功能,以应对不断增长的技术和安全挑战。
1、管理系统的必要性:复杂性的应对和效率提升
随着智能合约和DApps在各行业中的广泛应用,其复杂性和规模不断增加,传统的手动管理方式已难以满足实际需求。建立一个完善的管理系统对于应对复杂性和提升效率至关重要:
复杂性的应对:智能合约和DApps涉及多层次的技术架构和业务逻辑,管理系统可以提供统一的视图和控制界面,简化开发和运维过程。
效率提升:管理系统自动化和规范化智能合约和DApps的部署、监控、更新和优化,减少人为错误,提升工作效率和系统稳定性。
2、关键功能模块:部署管理、版本控制、安全监控、性能优化
(1)部署管理
功能:管理智能合约和DApps的部署过程,包括合约编译、测试和上链部署。
工具:提供自动化脚本和工具,确保部署过程的一致性和可靠性。
监控:实时监控部署状态和结果,快速识别和解决部署问题。
(2)版本控制
功能:管理智能合约和DApps的版本更新和迭代,跟踪代码变更历史。
回滚机制:支持快速回滚到稳定版本,确保在出现问题时能够迅速恢复系统正常运行。
兼容性检查:确保新版本与现有系统的兼容性,避免引入新的问题。
(3)安全监控
功能:实时监控智能合约和DApps的运行状态,检测潜在的安全威胁和异常行为。
漏洞扫描:定期扫描智能合约代码,发现并修复安全漏洞。
告警系统:在检测到安全问题时及时发出告警,并提供解决建议。
(4)性能优化
功能:监控和分析智能合约和DApps的性能指标,识别性能瓶颈。
优化工具:提供性能优化建议和工具,提升系统响应速度和处理能力。
资源管理:有效管理系统资源,确保在高负载情况下系统的稳定性和高效运行。
3、管理系统的架构设计:前端、后端和区块链层的集成
(1)前端
用户界面:提供友好和直观的用户界面,支持用户便捷地进行智能合约和DApps的管理和操作。
功能模块:包含部署管理、版本控制、安全监控和性能优化等功能模块的操作界面。
可视化工具:提供数据可视化工具,展示系统的运行状态和性能指标,帮助用户直观了解系统状况。
(2)后端
业务逻辑处理:负责处理前端发起的请求,执行智能合约和DApps的管理操作。
数据存储:管理和存储智能合约和DApps的相关数据,包括代码版本、部署记录和运行日志等。
API接口:提供统一的API接口,与前端和区块链层进行交互,确保数据传输的准确性和一致性。
(3)区块链层
合约部署:管理智能合约的部署和运行环境,确保合约在区块链上的正常执行。
状态同步:实时同步智能合约和DApps的状态数据,确保管理系统中的数据与区块链上的数据一致。
安全保障:利用区块链的去中心化和加密技术,提供智能合约和DApps的安全保障,防止未经授权的访问和操作。
通过前端、后端和区块链层的集成,智能合约和DApps的管理系统可以提供全方位的管理和优化支持。前端界面为用户提供便捷的操作和监控手段,后端处理复杂的业务逻辑和数据管理,区块链层确保智能合约和DApps的安全和稳定运行。整体架构设计确保了系统的高效性、可靠性和安全性,推动了智能合约和DApps的广泛应用和发展。
五、智能合约和DApps在各行业的应用
智能合约和分布式应用(DApps)在各行业的广泛应用展示了它们作为区块链技术核心组成部分的多样性和灵活性。它们正在改变金融、供应链管理、医疗健康和公共服务等领域的商业模式和操作方式,推动着行业创新和效率提升。
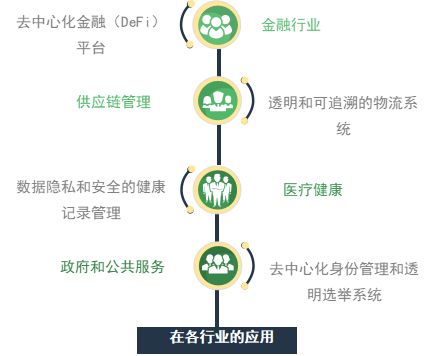
1、金融行业:去中心化金融(DeFi)平台
应用案例:Compound, Uniswap, MakerDAO
去中心化借贷:平台如Compound和Aave利用智能合约实现去中心化的借贷服务。用户可以存入加密资产作为抵押品,借出其他资产。智能合约自动管理抵押和清算,确保系统的安全性和稳定性。
去中心化交易所(DEX):Uniswap和SushiSwap等DEX平台利用智能合约实现去中心化的资产交易。智能合约自动撮合交易,无需中介机构,降低了交易成本并提高了交易透明度。
去中心化稳定币:MakerDAO通过智能合约创建和管理去中心化的稳定币Dai,确保其价值与法定货币挂钩。智能合约自动调整抵押率,维持Dai的稳定价值。
优势:
自动化和高效的金融服务
降低信任成本和中介费用
提高金融交易的透明度和安全性
2、供应链管理:透明和可追溯的物流系统
应用案例:VeChain, IBM Food Trust
透明物流:VeChain利用智能合约和区块链技术跟踪和记录供应链中的每个环节,包括生产、运输、存储和销售。智能合约自动执行关键流程,确保数据的准确性和透明度。
食品安全:IBM Food Trust利用智能合约管理食品供应链,确保从农场到餐桌的每个环节都可追溯。智能合约自动记录和验证每个环节的数据,提升食品安全和质量。
优势:
提高供应链的透明度和可追溯性
防止假冒伪劣产品
优化物流管理和库存控制
3、医疗健康:数据隐私和安全的健康记录管理
应用案例:MedRec, Patientory
电子健康记录(EHR)管理:MedRec利用智能合约管理患者的电子健康记录。智能合约自动处理访问权限,确保只有授权人员才能访问患者数据。所有数据存储在区块链上,确保隐私和安全。
患者数据共享:Patientory利用智能合约实现不同医疗机构之间的患者数据共享。智能合约确保数据的准确性和完整性,提高医疗服务的质量和效率。
优势:
提高数据隐私和安全性
简化医疗数据的共享和管理
提升医疗服务的效率和准确性
4、政府和公共服务:去中心化身份管理和透明选举系统
应用案例:uPort, FollowMyVote
去中心化身份管理:uPort利用智能合约和区块链技术创建去中心化身份管理系统。用户可以管理自己的数字身份,并授权第三方访问其数据。智能合约确保身份数据的安全和隐私。
透明选举系统:FollowMyVote利用智能合约实现去中心化的选举系统。智能合约记录选民的投票数据,确保投票过程的透明和公正。所有投票数据存储在区块链上,防止篡改和欺诈。
优势:
提高身份数据的安全性和隐私性
确保选举过程的透明和公正
降低管理和监督成本
智能合约和DApps在金融、供应链管理、医疗健康和政府公共服务等各行业展现了广泛的应用前景。它们通过去中心化、透明和自动化的方式,提升了各行业的效率和安全性,推动了数字经济的发展和创新。随着技术的不断进步,智能合约和DApps有望在更多领域发挥重要作用,进一步改变传统业务模式和管理方式。
六、技术挑战和解决方案
智能合约和分布式应用(DApps)在其发展过程中面临着多种技术挑战,如安全性、可扩展性和互操作性等。针对这些挑战,已经出现了一系列创新的解决方案,旨在提升系统的稳定性和功能性。
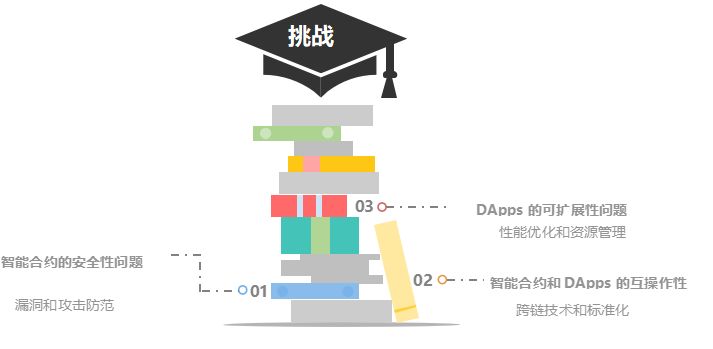
1、智能合约的安全性问题:漏洞和攻击防范
(1)挑战:
漏洞风险:智能合约一旦部署到区块链上,其代码是不可更改的,这使得任何代码漏洞都可能导致严重的安全问题,如资金被盗、数据被篡改等。
攻击类型:常见的攻击类型包括重入攻击(Reentrancy Attack)、整数溢出(Integer Overflow)、拒绝服务(DoS)攻击等。
(2)解决方案:
代码审计:定期进行第三方安全审计,发现并修复潜在的漏洞。
案例:以太坊智能合约审计平台,如Quantstamp和CertiK,提供专业的代码审计服务。
形式化验证:使用数学方法验证智能合约逻辑的正确性和安全性。
工具:使用形式化验证工具如KEVM、VeriSolid进行智能合约的形式化验证。
安全开发实践:采用安全开发生命周期(SDL),在开发过程中引入安全评估和测试。
措施:代码评审、单元测试、模糊测试(Fuzz Testing)等。
多重签名机制:引入多重签名机制,确保关键操作需要多方授权。
案例:Gnosis Safe是一个常用的多重签名钱包,确保资金管理的安全性。
2、DApps的可扩展性问题:性能优化和资源管理
(1)挑战:
性能瓶颈:区块链网络的交易处理能力有限,常导致交易拥堵和高昂的交易费用。
资源消耗:智能合约和DApps的运行需要消耗大量的计算资源和存储空间,影响系统的整体性能和用户体验。
(2)解决方案:
Layer 2 解决方案:使用状态通道、侧链和Rollup等技术,将部分交易移到链下处理,减轻主链负担。
案例:Lightning Network(比特币)、Optimistic Rollups(以太坊)。
分片技术:将区块链网络分成多个分片并行处理交易,提高系统的扩展性。
案例:以太坊2.0计划引入分片技术,实现更高的吞吐量。
链下计算:将复杂计算和大数据处理移到链下,通过链下计算和链上验证相结合,提升效率。
工具:使用Oracle服务,如Chainlink,实现链上和链下数据的交互。
资源管理:优化资源分配,提升智能合约和DApps的性能。
措施:智能合约代码优化、使用高效的数据结构、减少链上存储等。
3、智能合约和DApps的互操作性:跨链技术和标准化
(1)挑战:
互操作性差:不同区块链平台之间缺乏统一的标准和协议,导致智能合约和DApps无法跨链交互。
数据孤岛:各区块链网络的数据和资产无法互通,限制了应用的广泛性和灵活性。
(2)解决方案:
跨链技术:开发跨链协议和桥接技术,实现不同区块链网络之间的互操作性。
案例:Polkadot的中继链和桥接技术、Cosmos的互链通信协议(IBC)。
标准化协议:制定统一的标准和协议,促进智能合约和DApps的互操作性。
标准:ERC-20、ERC-721等以太坊代币标准,促进了代币和NFT的广泛应用。
跨链互操作平台:使用跨链互操作平台,实现多链应用的开发和部署。
工具:Wanchain、Ren Protocol等提供跨链资产和数据转移服务。
开放API接口:开发开放API接口,支持不同区块链平台和应用之间的数据和功能互通。
措施:使用GraphQL、RESTful API等技术,提升系统的互操作性和兼容性。
智能合约和DApps在应用过程中面临多种技术挑战,包括安全性、可扩展性和互操作性问题。通过采用代码审计、形式化验证、Layer 2 解决方案、分片技术、跨链技术和标准化协议等多种解决方案,可以有效应对这些挑战,提升智能合约和DApps的安全性、性能和互操作性。随着技术的不断进步和创新,智能合约和DApps将在更多行业中发挥重要作用,推动数字经济的快速发展。
七、未来发展趋势
智能合约和分布式应用(DApps)的未来发展展示出巨大的潜力和多样化的趋势。技术创新、法规完善以及市场应用的拓展将共同推动这些技术在全球范围内的广泛应用和深入发展。
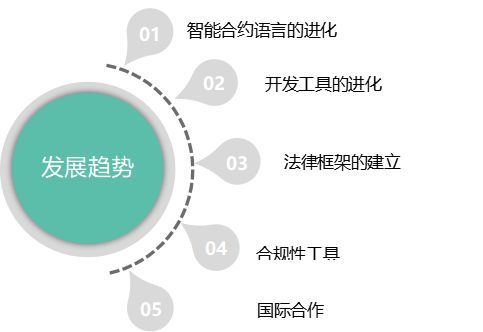
1、技术创新:智能合约语言和工具的进化
(1)智能合约语言的进化
新兴语言:随着智能合约的广泛应用,新型编程语言不断涌现,如Solidity、Vyper、Michelson(Tezos)和Scilla(Zilliqa)。
语言特性:未来的智能合约语言将更加关注安全性、可读性和开发效率。例如,Vyper注重简单性和安全性,Scilla则强调形式化验证。
领域专用语言(DSL):针对特定应用领域(如金融、供应链)的智能合约语言将会兴起,以简化特定业务逻辑的实现。
(2)开发工具的进化
集成开发环境(IDE):更强大的IDE将支持智能合约的开发和调试,如Remix、Truffle Suite和Hardhat。未来的IDE可能会集成更多的自动化工具和插件,提升开发效率。
形式化验证工具:随着智能合约安全性的需求增加,形式化验证工具将更加普及。例如,KEVM和VeriSolid等工具将成为开发过程中不可或缺的一部分。
测试框架:更完善的测试框架和模拟环境将帮助开发者在发布前发现潜在问题,如Ganache和Tenderly等工具。
2、法规和合规:智能合约和DApps的法律框架
(1)法律框架的建立
智能合约的合法性:各国政府将逐步建立和完善智能合约的法律地位,明确智能合约在合同法中的地位和效力。例如,美国和欧盟等地已经开始探讨相关法规。
数据隐私和安全:针对DApps的隐私和数据保护法规将日益严格,确保用户数据在去中心化应用中的安全和合规性。如GDPR在欧盟的实施。
(2)合规性工具
合规审计工具:开发合规性审计工具,帮助企业和开发者确保其智能合约和DApps符合相关法律和法规要求。
标准和认证:制定和推行行业标准和认证,如ISO标准,确保智能合约和DApps在开发和运营中的合规性。
(3)国际合作
跨国法规协调:各国政府和国际组织将加强合作,协调和统一智能合约和DApps的法律框架,促进跨国应用和交易的合法性和合规性。
3、市场趋势:主流应用和潜在市场的预测
(1)主流应用
去中心化金融(DeFi):DeFi将继续增长,更多创新的金融产品和服务将出现,如去中心化保险、合成资产和预测市场。
供应链管理:智能合约和DApps在供应链管理中的应用将进一步扩大,实现更高效的物流管理和透明化的供应链流程。
数字身份:去中心化身份管理(DID)将成为主流应用,改善身份验证和数据隐私保护。
(2)潜在市场
医疗健康:智能合约和DApps将在电子健康记录、远程医疗和医疗数据共享等领域发挥更大作用,提升医疗服务的效率和安全性。
能源市场:去中心化能源交易平台将兴起,实现点对点的能源交易和智能电网管理。
艺术和娱乐:NFT(非同质化代币)市场将继续扩大,艺术品、音乐和视频等数字资产的交易和管理将变得更加便捷和透明。
(3)市场预测
广泛应用:随着技术的成熟和法规的完善,智能合约和DApps将在更多传统行业中得到广泛应用,如房地产、保险和公共服务等。
投资和发展:更多的投资将涌入智能合约和DApps领域,推动技术创新和市场扩展。大型科技公司和传统金融机构将积极参与其中,促进生态系统的繁荣发展。
智能合约和DApps在未来将经历快速的技术创新、法规完善和市场扩展。随着智能合约语言和开发工具的不断进化,开发效率和安全性将显著提升。法规和合规框架的建立将为智能合约和DApps的合法性和数据安全提供保障。市场应用将不断扩展,从金融和供应链管理到医疗健康和能源市场,智能合约和DApps将深刻改变各行各业的业务模式和管理方式,推动数字经济的全面发展。
结语
智能合约和分布式应用管理系统正处于快速发展和演进的阶段,展示了巨大的潜力和广泛的应用前景。技术革新正在推动智能合约语言、开发工具和跨链技术的进步,提升了智能合约和DApps的安全性、性能和互操作性。与此同时,法规和合规框架的不断完善,为智能合约和DApps的合法性和数据安全提供了坚实保障。
在未来,智能合约和DApps将进一步渗透到各个行业,从金融、供应链管理到医疗健康和能源市场,推动行业变革和数字化转型。去中心化金融(DeFi)、去中心化身份管理(DID)和非同质化代币(NFT)等创新应用将继续引领市场发展,为用户带来更多便捷和高效的服务。
随着技术的成熟和生态系统的繁荣,智能合约和分布式应用管理系统将成为数字经济的基石,推动社会各领域的创新和进步。我们可以预见,智能合约和DApps将在未来的数字世界中扮演越来越重要的角色,为构建更加透明、安全和高效的数字化社会贡献力量。