网站开发宝典网站开发项目架构说明书
配置网络设备的明文密钥实验组网
实验拓扑

将一个路由器使用配置口进行连接
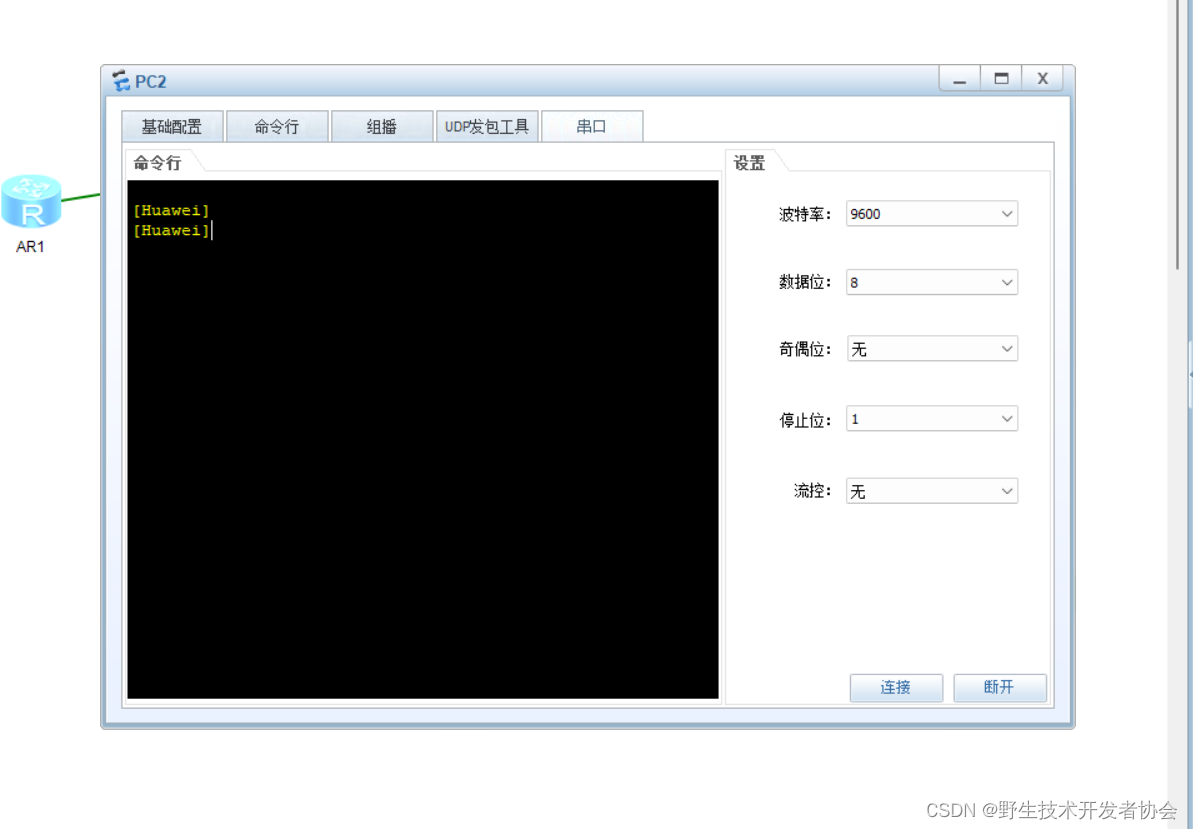
sys #进入系统视图模式
sysname RTA #给设备命名
user-interface console 0 #进入用户接口配置界面
authentication-mode password #配置认证模式为密钥认证
set authentication password cipher 123qwe #配置认证模式为密文认证,并创建密钥配置 VLAN 实验组网(一)
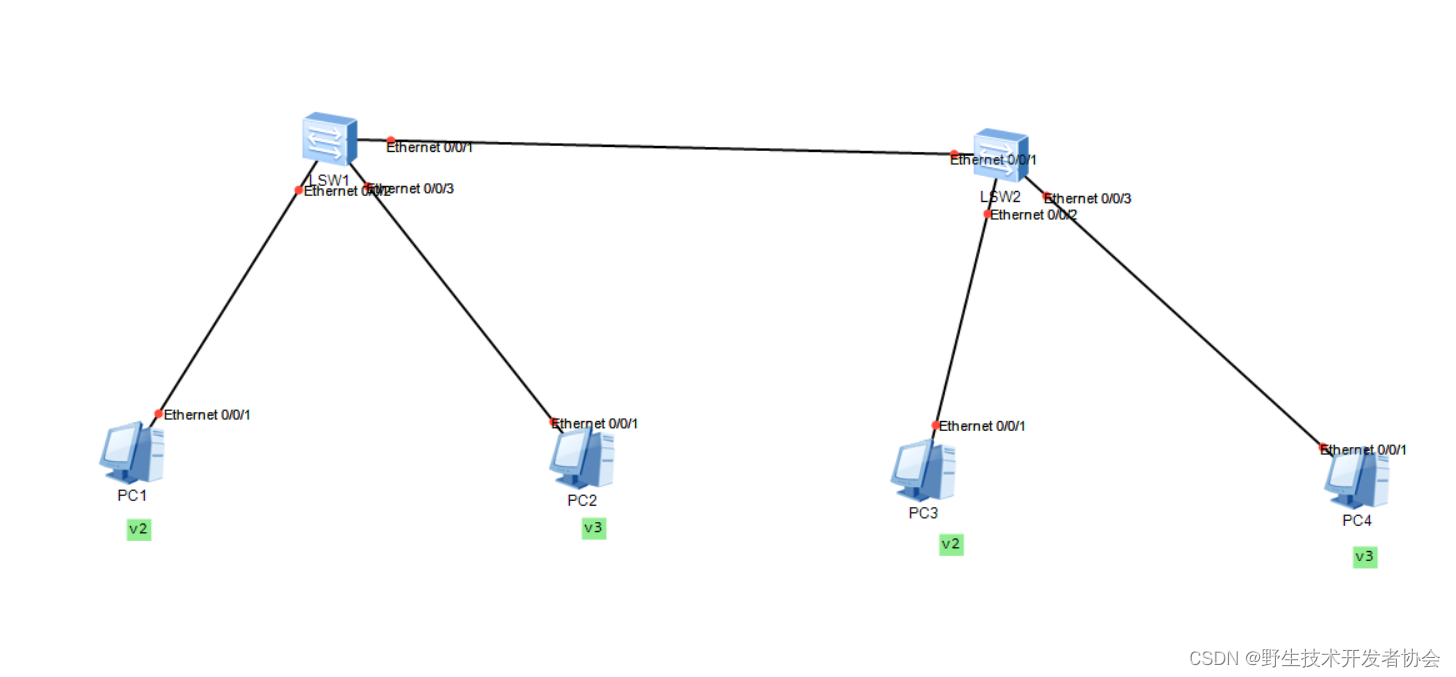
实验目的
在不同交换机的相同vlan可以通信
PC1 192.168.1.1
PC2 192.168.1.2
PC3 192.168.1.3
PC3 192.168.1.4
#LSW1命令
sys
undo info-center enable
sysname LSW
vlan 2
vlan 3
int e0/0/1
port link-type trunk
port trunk allow-pass valn allint e0/0/2
port link-type access
port default vlan 2int e0/0/3
port link-type access
port default vlan 3#LSW2
sys
undo info-center enable
sysname LSW2
vlan 2
vlan 3int e0/0/1
port link-type trunk
port trunk allow-pass valn allint e0/0/2
port link-type access
port default vlan 2int e0/0/3
port link-type access
port default vlan 3
配置 VLAN 实验组网(二)
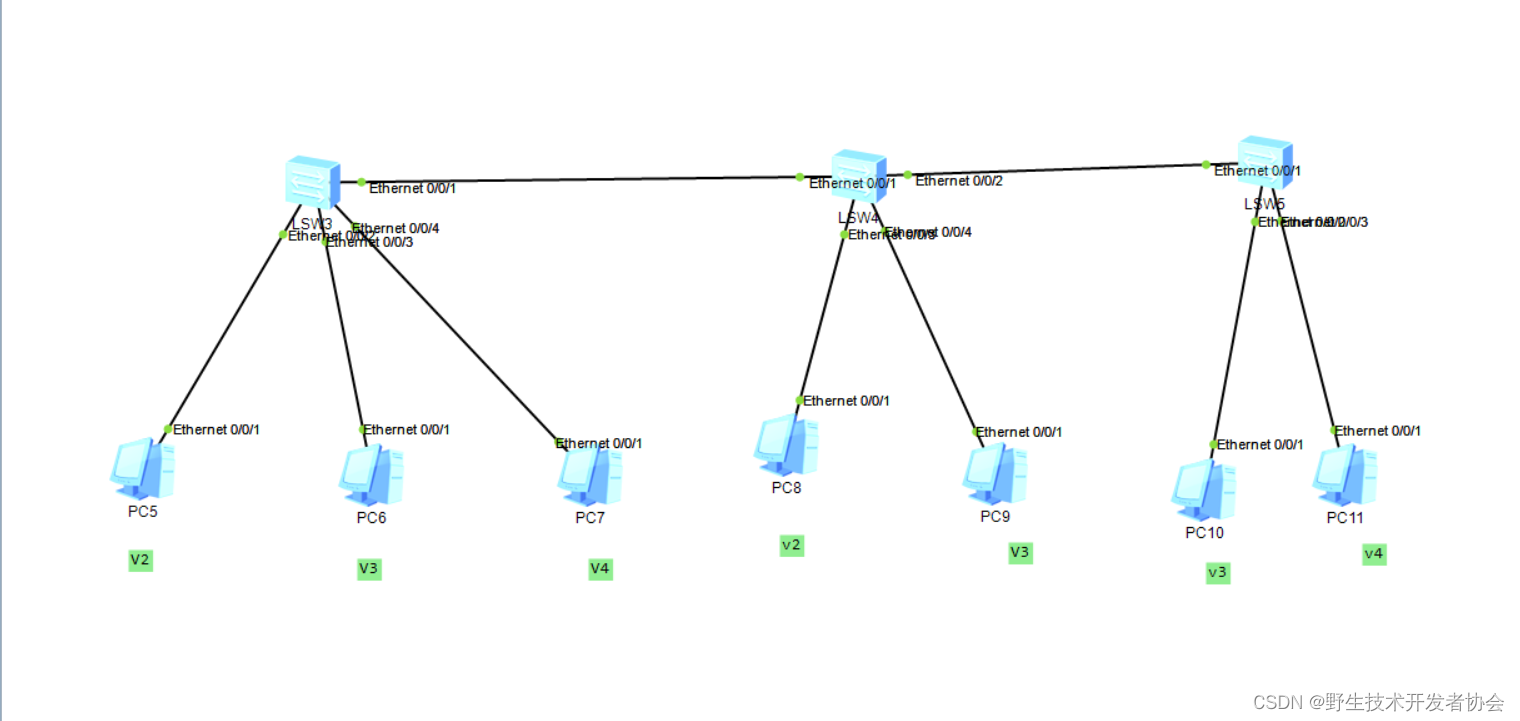
目的:在相同的子网中进行通信
#LSW1sys
sysname LSW1
undo info-center enable
vlan 2
vlan 3
vlan 4
int e0/0/1
port link-type trunk
port trunk allow-pass vlan allint e0/0/2
port link-type access
port default vlan 2int e0/0/3
port link-type access
port default vlan 3int e0/0/4
port link-type access
port default vlan 4#LS2
sys
sysname LSW2
undo info-center enable
vlan 2
vlan 3
vlan 4
int e0/0/1
port link-type trunk
port trunk allow-pass vlan allint e0/0/2
port link-type trunk
port trunk allow-pass vlan allint e0/0/3
port link-type access
port default vlan 2int e0/0/4
port link-type access
port default vlan 3#LS23
sys
sysname LSW3
undo info-center enable
vlan 3
vlan 4
int e0/0/1
port link-type trunk
port trunk allow-pass vlan allint e0/0/2
port link-type access
port default vlan 3int e0/0/3
port link-type access
port default vlan 4
# 配置 VLAN 实验组网(三)
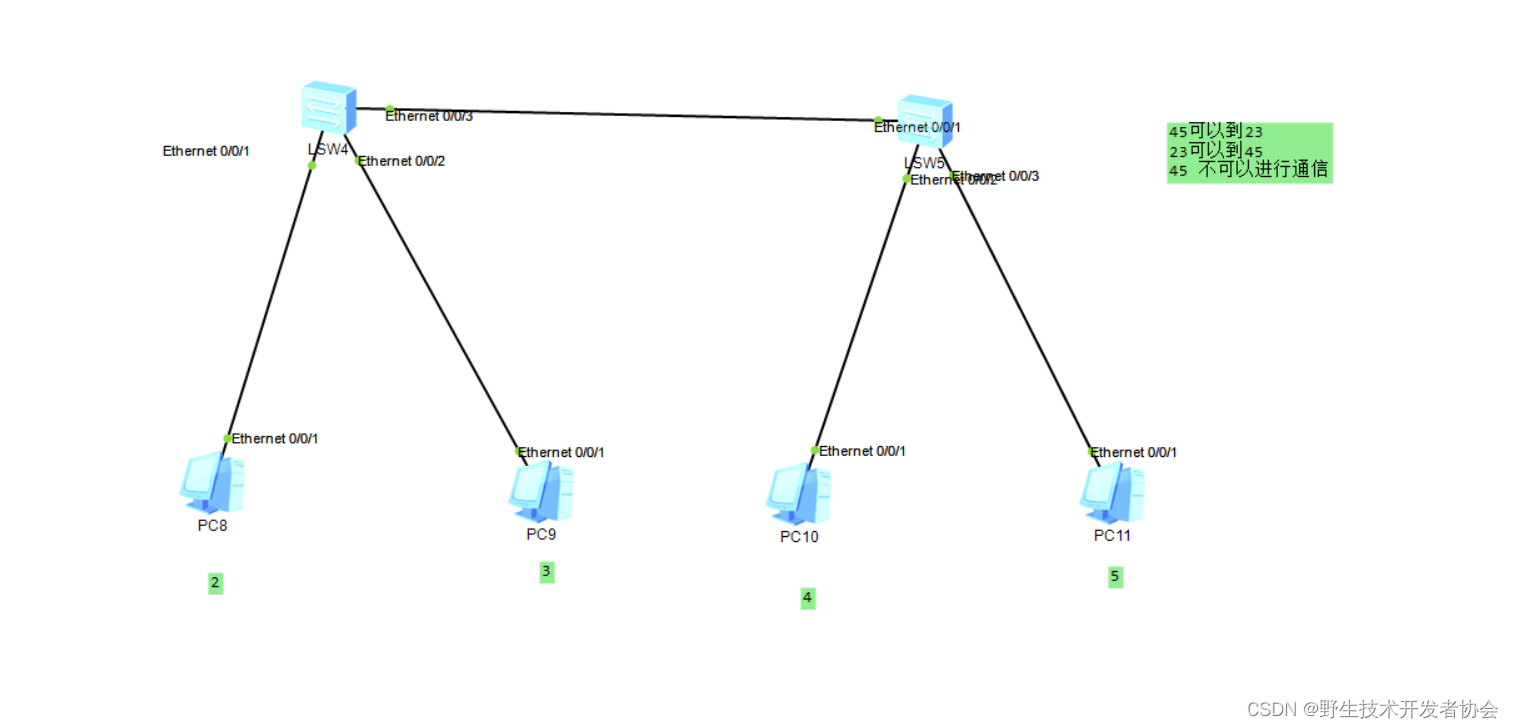
二、实验目的:
令 VLAN 2 中的 Client A 能够与 Client B,Client C,Client D
通信;令 VLAN 3 中的 Client B 能够与 Client A,Client C,
Client D 通信;令 VLAN 4 中的 Client C 不能与 VLAN 5 中的
Client D 通信
sysname LSW4
undo info-center enable
vlan batch 2 to 5interface Ethernet0/0/3
port link-type trunk
port trunk allow-pass vlan 2 to 4094interface Ethernet0/0/1
port hybrid pvid vlan 2
port hybrid untagged vlan 2 to 5interface Ethernet0/0/2
port hybrid pvid vlan 3
port hybrid untagged vlan 2 to 5sysname LSW5
undo info-center enable
vlan batch 2 to 5interface Ethernet0/0/2
port hybrid pvid vlan 4
port hybrid untagged vlan 2 to 4
interface Ethernet0/0/3port hybrid pvid vlan 5
port hybrid untagged vlan 2 to 3 5