嘉定网站建设网页制作安徽政务服务网
图像分类卷积神经网络模型综述
遇到问题
图像分类:核心任务是从给定的分类集合中给图像分配一个标签任务。
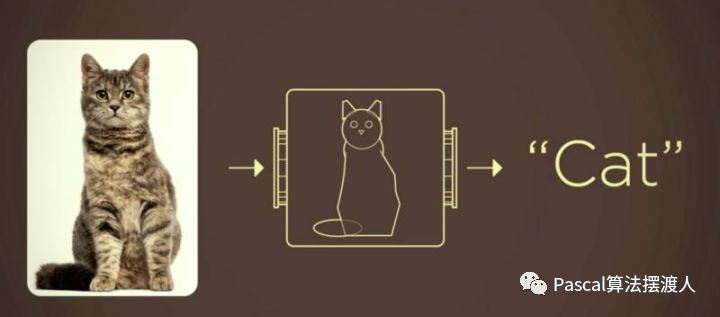
输入:图片
输出:类别。
数据集
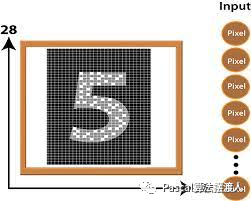
MNIST数据集
MNIST数据集是用来识别手写数字,由0~9共10类别组成。
从MNIST数据集的SD-1和SD-3构建的,其中包含手写数字的二进制图像:

MNIST数据集将SD-3作为训练集,将SD-1作为测试集,但SD-3比SD-1更容易识别,原因在于SD-3来源于人工调查局雇员,
SD-1来源于高中生,以上表明分类结果要独立于完整样本集中训练集和测试集的选择,因此,通过混合MNIST数据集来建立新
的数据集很有必要,SD-1有58537幅图像,由500位作者书写,排列混乱,SSD-3的图像是顺序的,新的训练集共有60000幅图像,
一部分来源于SD-1的前250位作家书写,剩余部分来源于SD-3.新的测试集有60000幅图像,部分来源于SD-1剩余250位作家所书写,一部分来源于SD-3。
新数据集成为MNIST数据集,共10个类别:
- 在LeNEt5实验中,训练集共60000幅图像,测试集共10000幅图像。
- 数据集包含4个文件
train-images-idx3-ubyte:训练集图像 train-labels-idx1-ubyte:训练集标签 t10k-images-idx3-ubyte:测试集图像 t10k-labels-idx1-ubyte:测试集标签
图像像素28*28.
IMagenET训练数据集
ImageNet数据集是具有超过1500万幅带标签的高分辨率图像数据库,这些图像大约属于22000个类别,这些图像由互联网收集,并由人工使用亚马逊的机械土耳其众包工具贴上标签。

从2010年开始,每年举行一次名为ImnageNet的大规模视觉识别挑战赛,ILSVRC使用ImageNet的子集
- 类别,共1000个类别
- 数量:总共大约有120万幅训练图像,其中,每个类别大约包含1000幅图像。
- 验证集合:50000幅验证图像
- 测试集:50000幅测试图像。
深度卷积网络模型在ImageNet数据集上进行训练和测试,衡量模型优劣的指标为top−1和top−5top-1和top-5top−1和top−5错误率。
top-5错误率
对每幅图像同时预测5个标签类别,若预测的五个类别任意之一为该图像的正确标签,则视为预测正确,那么预测错误的概率为top-5错误率。
top-1错误率
若对图像预测一次,预测错误的概率为top-1错误率。
CIFAR-10/100数据集
CIFAR-10数据集

- 分辨率为32 ×\times× 32
- 类别:共10个类别
- 数量:共有60 000幅彩色图像。其中,每个类别包含6 000幅图像。
- 训练集:包含50000幅彩色图像。
- 测试集:包含10 000幅彩色图像。图像取自10个类别,每个类别分别取1 000幅。
CIFAR-100数据集
• 类别:共100个类别
• 数量:共60000幅图像。其中,每个类别包含600幅图像
• 训练集:每个类别有500幅
• 测试集:每个类别有100幅
CIFAR-100中的100个类被分成20个大类别。每个图像都带有一个“精细”标签(它所属的类)和一个“粗糙”标签(它所属的超类)
SVHN数据集
该数据集用来检测和识别街景图像中的门牌号,从大量街景图像的剪裁门牌号图像中收集,包含600000幅小图像。
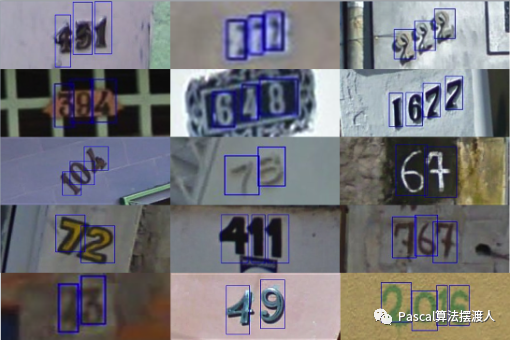
这些图像以两种格式呈现
- 一种是完整的数字,即原始的,分辨率可变的,彩色门牌号图像,每个图像包括检测到数字转录以及字符级的边界框。
- 一种是剪裁数字,图像的尺寸被调整为固定的32×3232 \times 3232×32像素。
SVHN数据集分为3个子集,73 257幅图像用于训练,26 032幅图像用于测试,531 131幅难度稍小的图像作为额外的训练数据。
类别**:10个类别,数字1~9对应标签1~9,而“0”的标签则为10**
•训练集:73257张图像
•测试集:26032张图像
•数据集格式**:带有字符级边界框的原始图像**。
评价标准
混淆矩阵
根据分类时预测与实际的情况,做出如下表格。
https://mp.weixin.qq.com/s/kAEZP20U0iRikuVKzeSe3w
准确率
准确率 = 正确预测的正反例数/总数
ACC=(TP+TN)/(TP+TN+FP+FN)=(A+D)/(A+B+C+D)ACC = (TP + TN)/(TP + TN + FP + FN) = (A + D)/(A + B + C + D)ACC=(TP+TN)/(TP+TN+FP+FN)=(A+D)/(A+B+C+D)
误分类率
误分类率 = 错误预测的正反例数/总数
误分类率 = 1 - ACC
查准率
查准率、精确率 = 正确预测到的正例数/预测正例总数。
召回率
查全率、召回率 = 正确预测到正例数/实际正例总数
F1 score
精确率与召回的调和平均值。
应用场景
- 智能楼宇中,根据人脸识别,识别员工为本大楼员工时,自动进行打卡,自动按工作流程设定电梯。
- 智能酒店中,根据人脸识别,办理自动入住,根据会员等级自动对接专属服务等。
- 电商行业中,根据图像识别、搜索类似商品。
- 教育行业中,根据人脸特征,记录学生的听课状态(打盹、走神、小动作、举手等)。
- 交通行业中,自动识别违规驾驶员
- 新零售行业中,根据人脸识别会员,实现到店提醒、导购引导、定制化运营等
- 公共交通中,实现刷脸支付。
- 游戏行业中,虚拟现实相关游戏。
解决框架
图像分类解决框架如下
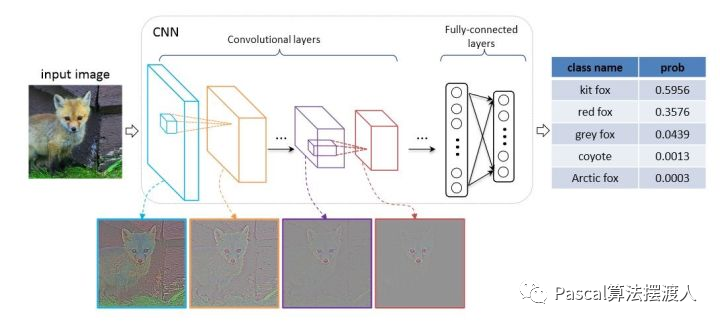
第一步
输入:图像image
第二步
图像特征提取
方法1: 传统算法(手工提取特征) - HOG、SIFT等
方法2:**深度学习(自动提取特征)- 卷神经网络(CNN)、自注意机制(Transformer)**等
第三步
分类器
方法1: 机器学习-SVM,随机树等。
方法2:图片特征进行全连接层即MLP。 加上softmax
第四步
输出:类别(label)
)、自注意机制(Transformer)**等
第三步
分类器
方法1: 机器学习-SVM,随机树等。
方法2:图片特征进行全连接层即MLP。 加上softmax
第四步
输出:类别(label)