网站前端设计公司旅游网站开发背景论文
这篇给大家整理了200+企业数字化转型案例合集,涵盖了制造、建筑、教育、零售、互联网等10+行业的大中小型企业数字化转型思路,希望对大家有所帮助。

案例全部整合在这篇文章中,点击即可查看>>数字化干货资料合集!
01 首先,不同行业对数字化转型的需求不同。
比如建筑行业的数字化转型不仅其行业的固有特性——多组织、多业态、多产业链协同的产业环境有关,还和每家企业的经营方式差异有很大的关系。
以建筑企业最核心的业务板块——项目管理为例:
绿城建筑科技集团是建筑施工行业的典型代表,在他们的数字化转型探索中,使用简道云对项目的立项和创建两个阶段进行数字化改革,其中包括:
项目流程规范化:解决了以前项目牛头不对马嘴的问题 关键节点权责分离:减少重叠工作中、提高业务效率 业务流程直接调用项目固化数据:杜绝以往常见的低级错误
对每个项目按主要节点编制计划、资金专款专用、流程单独核算、进度实时汇报,对重点项目设置巡检机制,对质量及其他问题设计整改流程,最终实现项目的全过程闭环管理。
其成效也是非常显著的——
自系统运行以来,原来一个项目多个合同需要多个编码,现在仅需一个编码关联多个合同,编码资源至少节约了60%,部门管理渠道从“多头管理”转为“直线对接”,业务员对接效率至少提升了70%。

而教育行业的数字化转型则更加倾向于战略和文化保障,期望通过数字技术系统解决信息孤岛和数据管理问题。
作为典型的教育行业,丽水南城幼儿园认为——
如果一味地去强调投入硬件和系统建设,不关注老师的使用情况,不去解决在教学之中遇到的一些问题,就会走入“重建设、轻应用”的怪圈。
想清楚这一点后,他们致力于寻找一款“连买菜大妈都会使用的应用”来帮助其完成园区的数字化转型,最终选择了简道云——
- 后勤管理数字化:隐患报修、采购申请、幼儿清点、消毒记录等数据记录全部在手机上完成,相比每天填写各类纸质表单,后勤人员非常乐意在手机上使用简道云进行填报。

- 信息收集数字化:疫情期间,第一时间在简道云搭建起了疫情防控管理应用,对全园 1700 多名师生进行了新冠肺炎防控数据统计,我们仅用了两小时就收集了两万余条数据。
- “一人一案一码”:为孩子们构建更加丰富完整的健康画像。自定义生成了带有二维码的健康画像,成功实现“一人一案一码”。
 清廉食堂大数据平台:通过多方联动,对食材的采购、验收、保质期等数据实现有效监管,从根源上杜绝食材出入库环节可能出现的廉政风险,真正意义上实现了阳光采购。
清廉食堂大数据平台:通过多方联动,对食材的采购、验收、保质期等数据实现有效监管,从根源上杜绝食材出入库环节可能出现的廉政风险,真正意义上实现了阳光采购。

02 同一行业的数字化转型侧重点也不同
就算是同一行业,不同企业的数字化转型路径、侧重点也是不尽相同的,以制造行业为例——
- 以钢铁行业为代表的装备制造行业数字化转型的重点是以生产管控为核心的智能生产体系。
- 以机械行业为代表的装备行业数字化转型的重点是完成产品的智能化、服务化转型,即智能服务。
山东龙辉起重机械有限公司就是典型的以“机械”为代表的制造企业,在他们使用简道云的数字化转型中——
搭建生产管理系统:通过对每一台行车定义唯一编码,实现全流程的管理,生产的每一环节,员工都只要通过扫码上传照片或者勾选相应信息。

搭建原材料管理系统:实时观察主要原材料的价格波动趋势,在原材料的入库的时候就录入当天价格并设置简单的分析,管理人员或者领导可以随时在手机上看到价格变化,为决策提供参考依据。
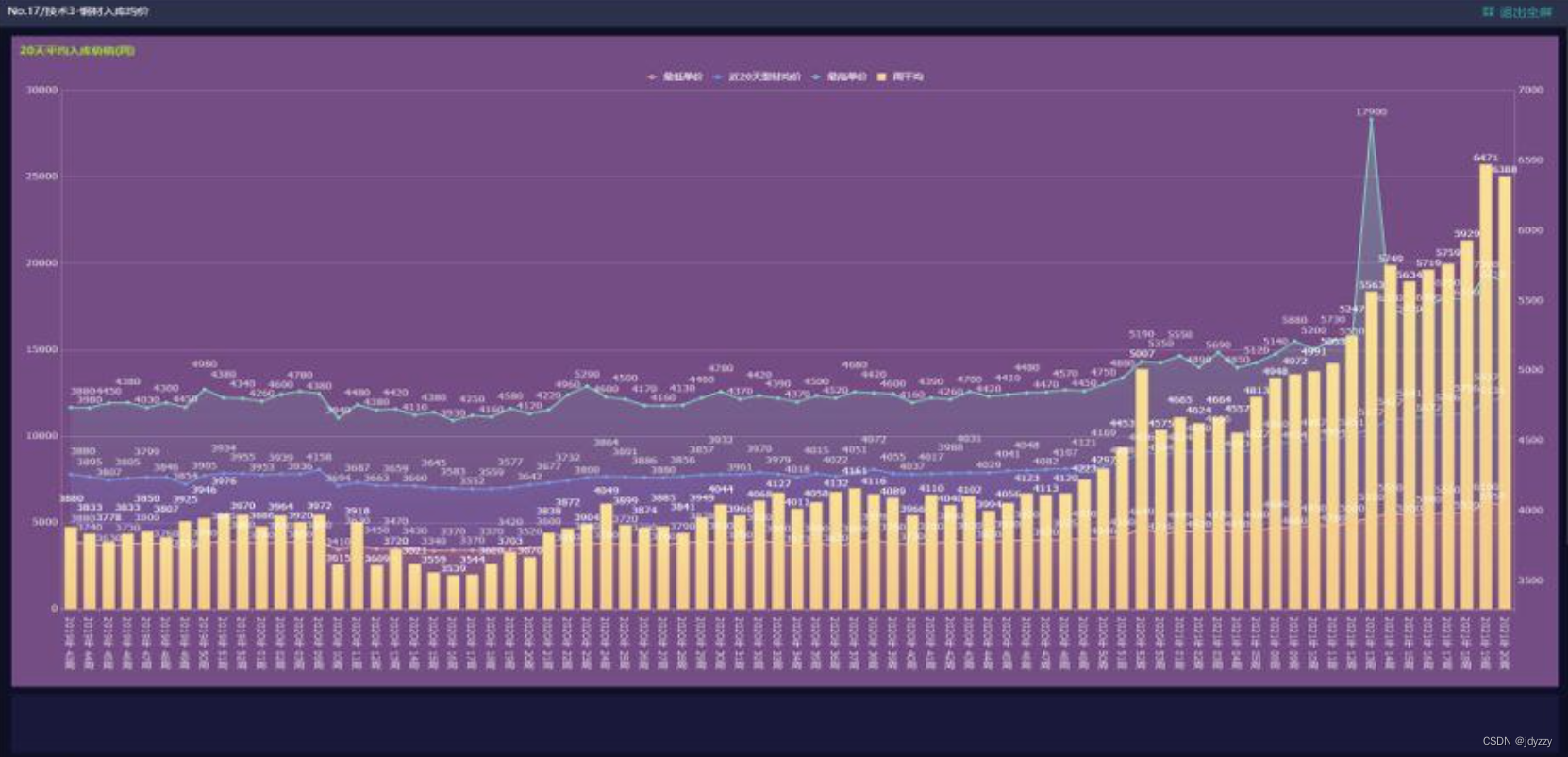
搭建订单管理系统:结合生产、原材料管理等数据,从派单到发货每一步都可查可追溯。
 而广西钢铁集团有限公司作为我国华南、西南地区最大的钢铁联合企业,其数字化转型则另有特色,他们通过简道云——
而广西钢铁集团有限公司作为我国华南、西南地区最大的钢铁联合企业,其数字化转型则另有特色,他们通过简道云——
- 设备巡检:柳钢通过简道云“一张表单多张码”的巡检解决方案,在系统后台建立设备信息表,给每个设备都生成一个随机码,有力确保了巡检质量和真实性。
- 设备维修:手机扫码填写故障信息并提交维修申请,维修人员在第一时间收到任务提醒,根据故障信息进行预判,携带相应工具进行维保。

其数字化转型在设备管理上收效良好——
隐形强制巡检员到位巡检,确保了巡检的规范性; 减少从发现故障到维修的响应时长,做到了早发现早维修; 报修流程规范化,报修信息完善,避免了因沟通问题导致的效率降低; 危险作业必须申请危险作业证,实现了安全交底,保障了员工安全; 领导拿出手机,即可查看具体维修情况、监督危险作业。
除此之外,还通过API对接物联网,实现有害气体自动监测、解放人力,报警信息触达时长缩短99%。

最后想说的是——
数字化转型最关键的一是业务的数字化,二是组织的数字化。后者因易被忽视,显得更加重要。