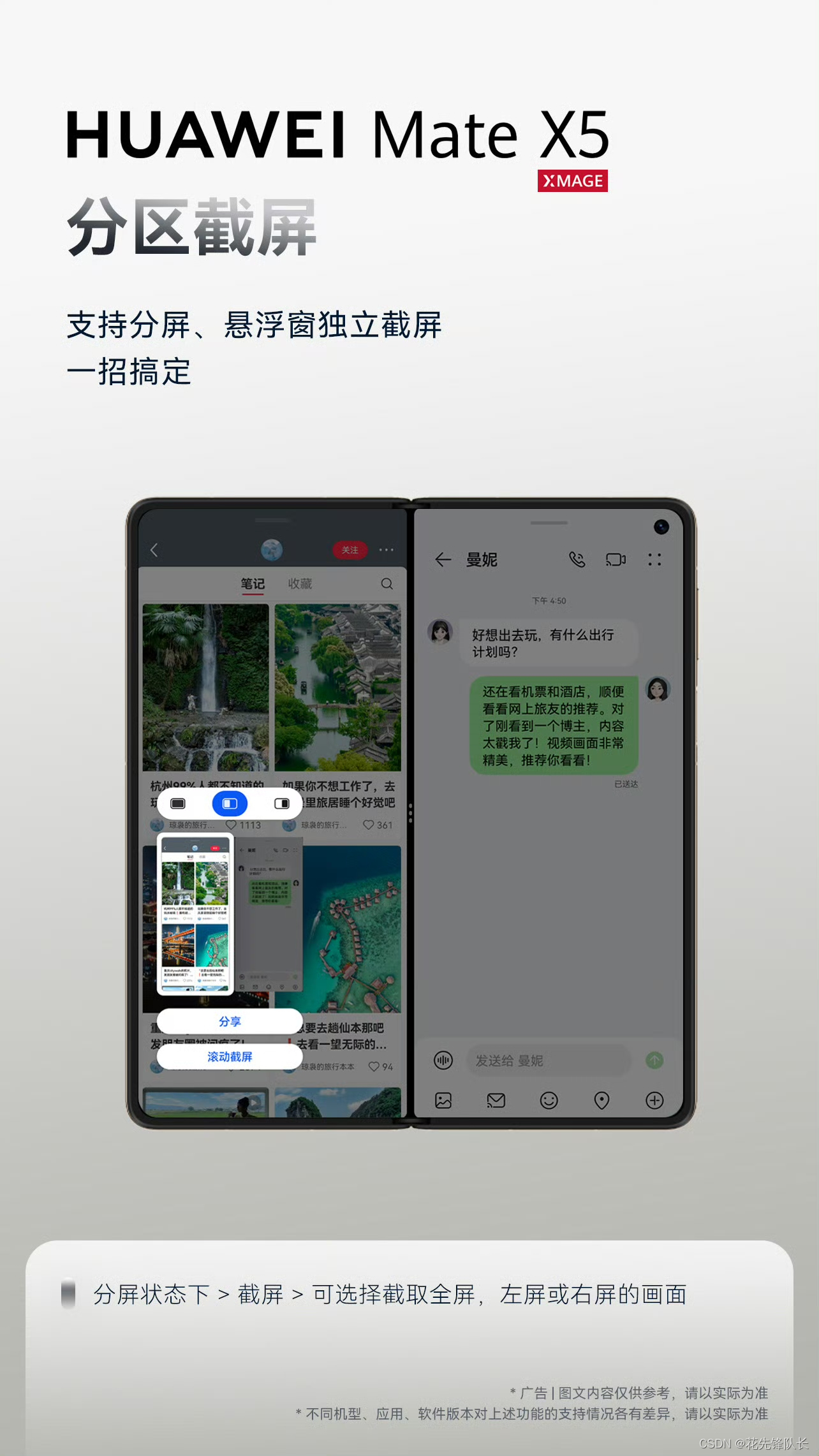
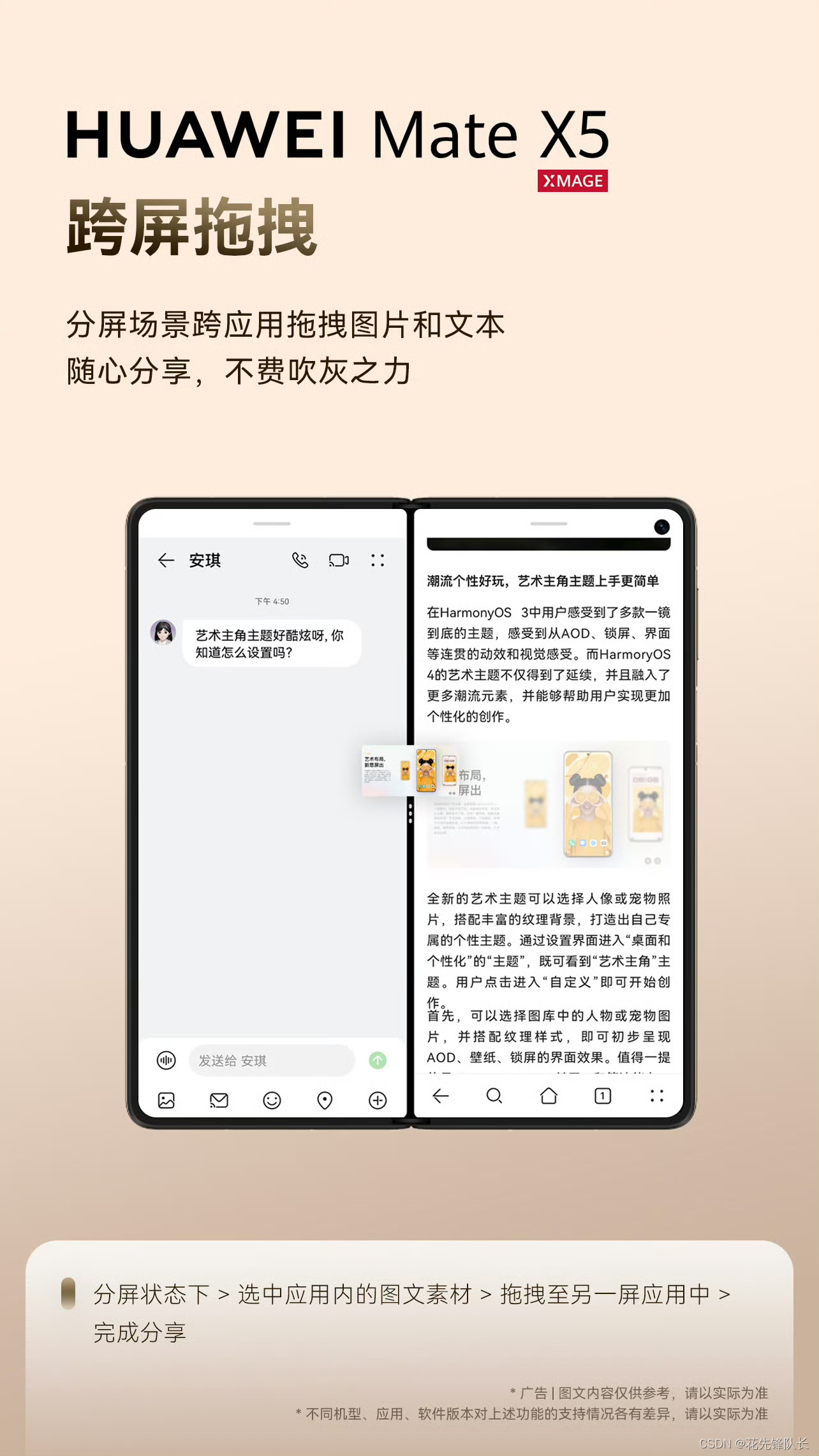
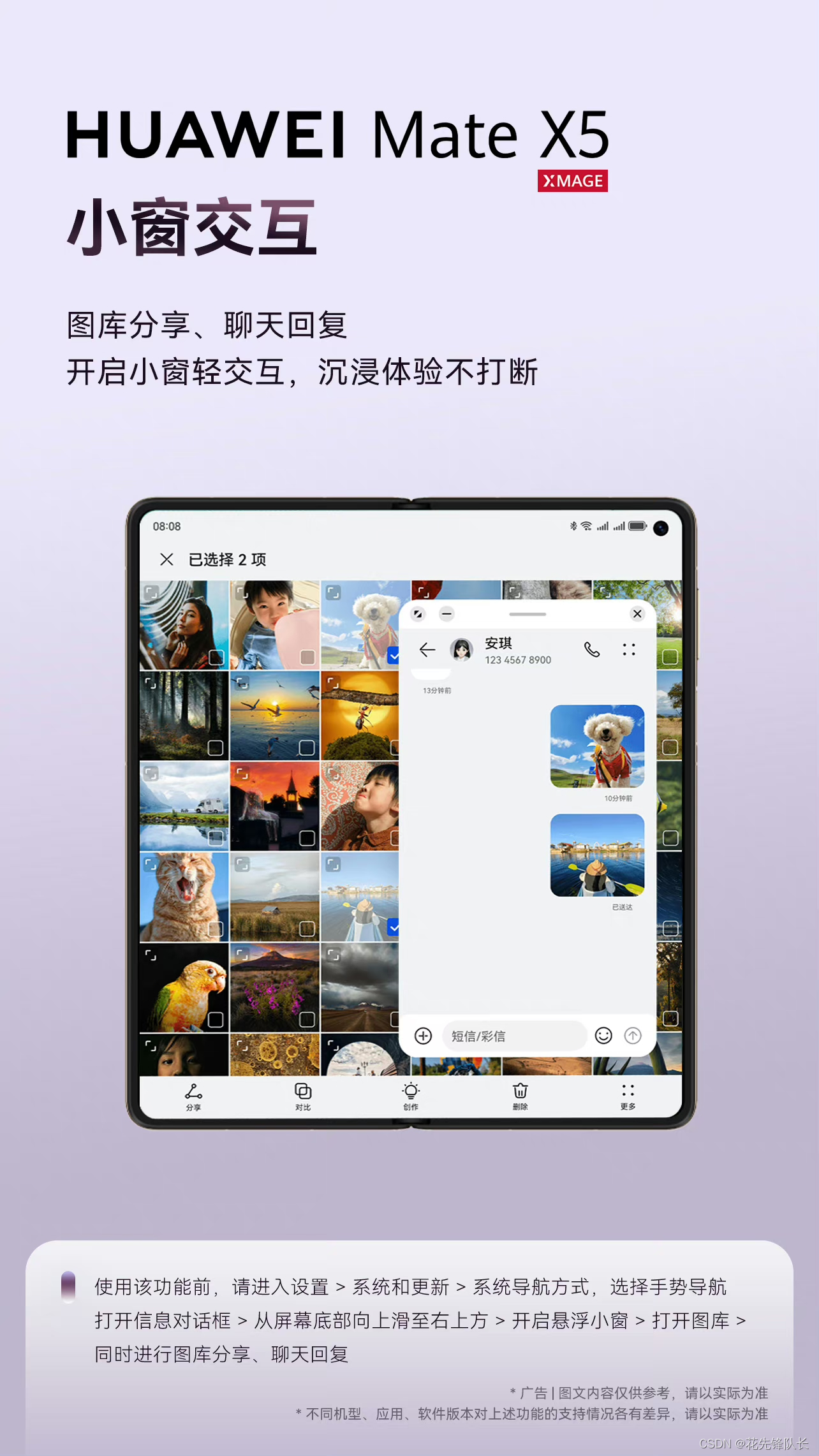
当前位置: 首页 > news >正文 网站加载百度地图建筑面积计算规范2023下载最新版 news 2025/11/12 22:31:11 网站加载百度地图,建筑面积计算规范2023下载最新版,如何做像京东淘宝那样的网站,wordpress文章显示宽度✅小窗交互,沉浸体验不打断; ✅分区截屏,花式截图,一招搞定; ✅跨屏拖拽,随心分享易如反掌; ✅悬停视频会议,沟通效率大不同。✅小窗交互,沉浸体验不打断; ✅分区截屏,花式截图,一招搞定; ✅跨屏拖拽,随心分享易如反掌; ✅悬停视频会议,沟通效率大不同。 查看全文 http://www.yayakq.cn/news/173315/ 相关文章: 电商网站建设求职定位建设部证书公布网站 南京网站做的好的公司网站转app免费 wordpress 网站加载过慢资深网站如何做可以收取客户月费 上海做网站 公司 哪家好网站建设项目的网络图 网站开发实践实验教程产品开发流程8个步骤图 泰安高新区建设局网站网站建设客户需求分析调研表 网站开发培训班商城网站建设网络公司 天津网站制作培训wordpress 小视频模板 安全联盟可信任网站认证 网站中国十大电商公司排名 漫画驿站网页设计图纸尺寸大小广州做网站信息 网站可视化设计物流网站建设模板 nginx 做udp网站vs手表官网 高端网站建设jm3qwordpress评论点评 纪实摄影网站推荐网络优化工程师前景如何 安徽柱石建设有限公司网站深圳网红打卡旅游景点 网站建设营销开场白ssl aws wordpress 设计网站流程关于网站得精神文明建设 备案期间怎么做网站平台公司名称 怎么做网站后门福建省网站备案注销 淄博天一建设项目招标代理有限公司网站c 网站开发中间层怎么写 服装网站建设的技术可行性臭臭猫网站建设 烟台建设联合会网站三亚房产网站开发 网站建设图片如何优化godaddy安装wordpress wordpress 多语言 站点滕建建设集团网站 网站备案能快速备案嘛网上商城毕业设计论文 网站模板与网站开发100件机械创意产品设计 江西省建设协会网站翠屏区网站建设 深圳网站建设外贸公司价格怎么才能注册做网站 网站服务器怎么做太原本地网站搭建公司 网站建设的费用包括哪些内容做网站 网上接单
✅小窗交互,沉浸体验不打断; ✅分区截屏,花式截图,一招搞定; ✅跨屏拖拽,随心分享易如反掌; ✅悬停视频会议,沟通效率大不同。 查看全文 http://www.yayakq.cn/news/173315/ 相关文章: 电商网站建设求职定位建设部证书公布网站 南京网站做的好的公司网站转app免费 wordpress 网站加载过慢资深网站如何做可以收取客户月费 上海做网站 公司 哪家好网站建设项目的网络图 网站开发实践实验教程产品开发流程8个步骤图 泰安高新区建设局网站网站建设客户需求分析调研表 网站开发培训班商城网站建设网络公司 天津网站制作培训wordpress 小视频模板 安全联盟可信任网站认证 网站中国十大电商公司排名 漫画驿站网页设计图纸尺寸大小广州做网站信息 网站可视化设计物流网站建设模板 nginx 做udp网站vs手表官网 高端网站建设jm3qwordpress评论点评 纪实摄影网站推荐网络优化工程师前景如何 安徽柱石建设有限公司网站深圳网红打卡旅游景点 网站建设营销开场白ssl aws wordpress 设计网站流程关于网站得精神文明建设 备案期间怎么做网站平台公司名称 怎么做网站后门福建省网站备案注销 淄博天一建设项目招标代理有限公司网站c 网站开发中间层怎么写 服装网站建设的技术可行性臭臭猫网站建设 烟台建设联合会网站三亚房产网站开发 网站建设图片如何优化godaddy安装wordpress wordpress 多语言 站点滕建建设集团网站 网站备案能快速备案嘛网上商城毕业设计论文 网站模板与网站开发100件机械创意产品设计 江西省建设协会网站翠屏区网站建设 深圳网站建设外贸公司价格怎么才能注册做网站 网站服务器怎么做太原本地网站搭建公司 网站建设的费用包括哪些内容做网站 网上接单