如何更换网站图片网优 是什么网站
目录
1、SerialPort类的介绍和使用:
(1)、SerialPort类的功能介绍
(2)、SerialPort类提供接口函数的介绍
1)、InitPort函数
2)、控制串口监视线程函数
3)、获取事件,写缓冲大小,获取DCB的接口函数
4)、写数据到串口接口函数
5)、错误处理接口函数
6)、线程接口函数
7)、接收字符和字符串接口函数
8)、对接手的数据进行处理函数
(3)、对于这些接口函数的使用
2、设计串口通信:
(1)、UI设计
(2)、添加变量
(3)、程序设计
1)、初始化下拉框
2)、打开串口点击事件
3)、发送信息点击事件
4)、发送清空显示功能实现
5)、勾选框功能的添加
6)、保存文件功能实现
7)、实现饮水机的读取温度功能
1、SerialPort类的介绍和使用:
(1)、SerialPort类的功能介绍
SerialPort类封装了串口的基本上操作,包括打开串口,传递串口参数,控制串口监视线程,获取写缓冲事件,获取事件,获取DCB,写数据到串口,从串口读数据,判断串口是否打开,关闭串口,线程处理等功能
(2)、SerialPort类提供接口函数的介绍
1)、InitPort函数
串口连接首先要打开串口建立串口通讯协议(也就是确定串口号,波特率,数据位,校验位和停止位)。InitPort函数实现的就是串口的打开和串口设置的初始化。
函数原型:
BOOL InitPort(HWND pPortOwner, UINT portnr = 1, UINT baud = 9600,
TCHAR parity = _T('N'), UINT databits = 8, UINT stopsbits = ONESTOPBIT,
DWORD dwCommEvents = EV_RXCHAR | EV_CTS, UINT nBufferSize = 512,DWORD ReadIntervalTimeout = 1000,
DWORD ReadTotalTimeoutMultiplier = 1000,
DWORD ReadTotalTimeoutConstant = 1000,
DWORD WriteTotalTimeoutMultiplier = 1000,
DWORD WriteTotalTimeoutConstant = 1000);
BOOL CSerialPort::InitPort(HWND pPortOwner, // 接收消息的当前对话框(默认只有一个句柄)
UINT portnr, // portnumber (串口号,可以有1-100个串口号,这里数字不代表串口号)
UINT baud, // baudrate(波特率,数据每秒传输的位数,波特率大不代表准确)
TCHAR parity, // parity (校验位,用于错误检查的一种数据,通常与数据位和停止位一起传输表示一个完整的数据块)
UINT databits, // databits (二进制位,用于表示传输的原始数据)
UINT stopbits, // stopbits (数据传输结束后发送的最后一位数,通常位1或者0)
DWORD dwCommEvents, // EV_RXCHAR(有字符可读取), EV_CTS etc(清除发送),这俩标志位按照按位与和或可以检测多种事件。(串口通信时需要监测的事件类型)
UINT writebuffersize,// size to the writebuffern(表示缓冲区的大小,不能太小,防止数据丢失)DWORD ReadIntervalTimeout,(DWORD4个字节的无符号整数)
DWORD ReadTotalTimeoutMultiplier,
DWORD ReadTotalTimeoutConstant,(上面三个DWORD值代表读操作的超时时间)
DWORD WriteTotalTimeoutMultiplier,
DWORD WriteTotalTimeoutConstant)(上面俩个DWORD值代表写操作的超时时间)
2)、控制串口监视线程函数
BOOL StartMonitoring();//开始监听
BOOL ResumeMonitoring();//恢复监听
BOOL SuspendMonitoring();//挂起监听
BOOL IsThreadSuspend(HANDLE hThread);//判断线程是否挂起 //add by itas109 2016-06-29
3)、获取事件,写缓冲大小,获取DCB的接口函数
DWORD GetWriteBufferSize();///获取写缓冲大小
DWORD GetCommEvents();///获取事件
DCB GetDCB();///获取DCB
4)、写数据到串口接口函数
void WriteToPort(char* string, size_t n); //重载写字符串(二进制)
void WriteToPort(PBYTE Buffer, size_t n);// 重载写16进制
void ClosePort(); //关闭串口
BOOL IsOpened(); //判断串口是否打开
5)、错误处理接口函数
void ProcessErrorMessage(TCHAR* ErrorText);///错误处理
6)、线程接口函数
static DWORD WINAPI CommThread(LPVOID pParam);///线程函数
LPVOID相当于是一个VOID,传递一个VOID类型的指针,在线程中不断的读取串口数据
7)、接收字符和字符串接口函数
static void ReceiveStr(CSerialPort* port); //接收单个字符。
WriteChar(CSerialPort* port);//接收字符串(\0结尾)。
8)、对接手的数据进行处理函数
virtual int HandleReadData(uint8_t *pMsgBuf, uint32_t iSize) = 0;// 对接收到的数据进行响应处理
(重写纯虚函数来实现数据处理)
(3)、对于这些接口函数的使用
由于SerialPort以及封装好了底层操作,首先InItPort函数(也就是传递串口设置和对话框的句柄),其次就可以进行写入串口操作WriteToPort和数据处理重写纯虚函数HandleReadData。
2、设计串口通信:
(1)、UI设计
创建工程,选择MFC对话框,然后添加控件

(2)、添加变量
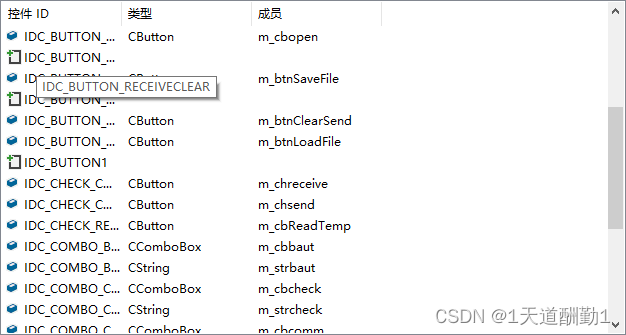

(3)、程序设计
1)、初始化下拉框
在框架类的CPP中,自定义函数MycommInit来初始化下拉列表

在OnInitDialog中被调用初始化。这个初始化仅仅是一个UI上的初始化。
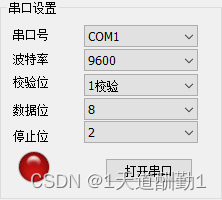
2)、打开串口点击事件
打开串口的点击事件,首先需要根据SerialPort的打开串口接口函数进行串口属性的初始化(真正的属性初始化)和打开串口操作,同时设置了一个picture control(更改属性加载BTM的图片)根据串口打开和关闭改变颜色。
先判断什么时候需要进行串口的初始化
UpdateData(TRUE);
//将控件中的内容同步到变量中,我们操作控件就相当于操作变量。
CString strOpen;
//strOpen来获得按钮上面的文字内容。
GetDlgItemText(IDC_BUTTON_OPEN, strOpen);if (strOpen == "打开串口")
//点击按钮事件,点击的是打开串口
{进行一些操作
}
波特率
/*增加波特率的代码复用性*/
const TCHAR* buffer1 = m_strbaut.GetBuffer();// 获取 CString 对象内部字符数组的指针
UINT m_mystrbaut = _ttoi(buffer1);// 使用 _ttoi() 或其他适当的转换函数将字符串转换为 UINT 类型
m_strbaut.ReleaseBuffer();// 释放 CString 对象的缓冲区
串口号
/*增加串口号的代码复用性*/
const TCHAR* buffer2 = m_strcomm.GetBuffer();// 获取 CString 对象内部字符数组的指针
int index = m_strcomm.FindOneOf(_T("0123456789"));// 查找第一个数字字符的索引
CString numericPart = m_strcomm.Mid(index);// 提取从第一个数字字符开始的子字符串
unsigned long ulValue = _tcstoul(numericPart, nullptr, 10);// 将提取的子字符串转换为 unsigned long 类型
UINT m_mystrcomm = static_cast<UINT>(ulValue);// 将 unsigned long 类型的值转换为 UINT 类型
m_strcomm.ReleaseBuffer();// 释放 CString 对象的缓冲区
// 现在,m_mystrcomm 变量中存储了转换后的 UINT 数值
校验位
/*增加校验位的代码复用性*/
CString strcheck = getCheck();
const TCHAR* buffer = strcheck.GetBuffer();// 获取 CString 对象内部字符数组的指针
TCHAR m_mycbcheck = buffer[0];// 获取第一个字符
strcheck.ReleaseBuffer();// 释放 CString 对象的缓冲区
停止位
/*/*增加停止位的代码复用性*/
const TCHAR* buffer3 = m_strstop.GetBuffer();// 获取 CString 对象内部字符数组的指针
UINT m_mystrstop = _ttoi(buffer3);// 使用 _ttoi() 或其他适当的转换函数将字符串转换为 UINT 类型
if (m_mystrstop == 1)
m_mystrstop = 0;
m_strstop.ReleaseBuffer();// 释放 CString 对象的缓冲区
真正打开串口
//初始化串口
m_myserialport.InitPort(
m_hWnd,
m_mystrcomm,
m_mystrbaut,
m_mycbcheck,
8,
m_mystrstop
);
m_myserialport.StartMonitoring();//开始监听
异常捕获(上面的打开串口)
try{打开串口操作}
catch (CException* e)
{
MessageBox(L"端口不存在!", L"打开串口", MB_ICONERROR);
return;
}
加载自己的位图
CBitmap bitmap; // CBitmap对象,用于加载位图
HBITMAP hBmp; // 保存CBitmap加载的位图的句柄bitmap.LoadBitmap(IDB_BITMAP_GREEN); // 将位图IDB_BITMAP1加载到bitmap
hBmp = (HBITMAP)bitmap.GetSafeHandle(); // 获取bitmap加载位图的句柄
m_PictureContol.SetBitmap(hBmp); // 设置图片控件m_picIndicator的位图图片为IDB_BITMAP_GREEN
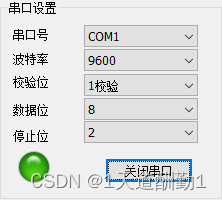
打开串口操作之后,打开串口变成关闭串口并且位图也要变化
else // 4、此时串口已经处于打开状态 执行关闭串口
{
m_myserialport.SuspendMonitoring();
m_myserialport.ClosePort();
SetDlgItemText(IDC_BUTTON_OPEN, _T("打开串口")); //串口打开之后,设置按钮为“关闭”
CBitmap bitmap; // CBitmap对象,用于加载位图
HBITMAP hBmp; // 保存CBitmap加载的位图的句柄bitmap.LoadBitmap(IDB_BITMAP_RED); // 将位图IDB_BITMAP1加载到bitmap
hBmp = (HBITMAP)bitmap.GetSafeHandle(); // 获取bitmap加载位图的句柄
m_PictureContol.SetBitmap(hBmp); // 设置图片控件m_picIndicator的位图图片为IDB_BITMAP_RED}
3)、发送信息点击事件
点击发送按钮在EDIT中发送信息
先进性一个判断如果串口没有打开就提示弹框,获取我们打开串口上面的文字内容进行判断。
CString strOpen;//strOpen来获得按钮上面的文字内容。
GetDlgItemText(IDC_BUTTON_OPEN, strOpen);if (strOpen =="打开串口")
{
MessageBox(L"串口未打开!", L"串口问题", MB_ICONERROR);
return;
}
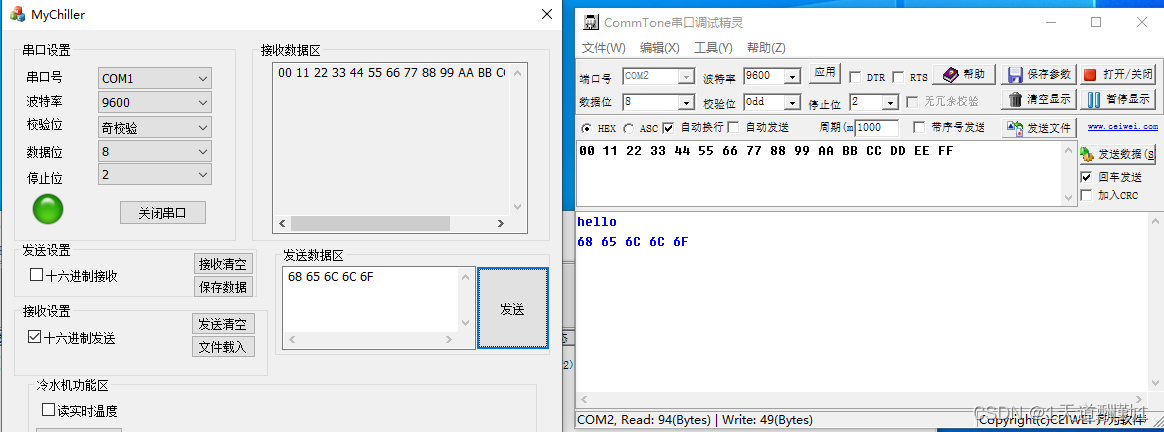
然后就可以进行发送消息的处理(首先是发送二十六进制数据)
首先定义一个BYTE类型的数组存放数据,把EDIT上的内容同步到str上
BYTE *data = new BYTE[m_strReceive.GetLength()];//自定义接收十六进制的数组
int rlen = 0;
CString str;
str = m_strReceive;
自定以一个处理函数来处理数据,先转成十进制再利用十进制转成16进制的整形存放再数组中
rlen = Str2Hex(str, data);
//自定义函数Str2Hex函数处理,十进制转换成16进制存放在data数组中
int Str2Hex(CString str, BYTE *data)
{
int t, t1;
int rlen = 0, len = str.GetLength();
if (len == 1)
{
char h = str[0];
t = HexChar(h);
data[0] = (BYTE)t;
rlen++;
}
for (int i = 0; i < len;)
{
char l, h = str[i];
if (h == ' ')
{
i++;
continue;
}
i++;
if (i >= len)
break;
l = str[i];
t = HexChar(h);
t1 = HexChar(l);
if ((t == 16) || (t1 == 16))
break;
else
t = t * 16 + t1;
i++;
data[rlen] = (BYTE)t;
rlen++;
}
return rlen;
}rlen = Str2Hex(str, data);
上面的函数需要先调用HexChar把字符数字转成十进制对应的数字
//自定义函数HexChar处理十六进制(十六进制转成10进制)
char HexChar(char c){
if ((c >= '0') && (c <= '9'))return c - '0';//16进制中的,字符0-9转化成10进制,还是0-9
else if ((c >= 'A') && (c <= 'F'))
return c - 'A' + 10;//16进制中的A-F,分别对应着11-16
else if ((c >= 'a') && (c <= 'f'))
return c - 'a' + 10;//16进制中的a-f,分别对应也是11-16,不区分大小写
else
return 0x10; // 其他返回0x10
}
利用WriteToPort函数接口第二个重载可以发送十六进制,直接传递参数
m_myserialport.WriteToPort(data, rlen);
delete[]data;
data = NULL;//释放空间
如果发送的是二进制数据可以直接调用WriteToPort函数
else
{
CString cstr;
cstr = m_strReceive;
CStringA cstrA;
cstrA = cstr; //CString类型转成char *类型才能传入参数
m_myserialport.WriteToPort(cstrA.GetBuffer(), cstr.GetLength());
}

4)、发送清空显示功能实现
void CMyChillerDlg::OnBnClickedButtonReceiveclear()
{
// TODO: 在此添加控件通知处理程序代码SetDlgItemText(IDC_EDIT1, L" ");
UpdateData(TRUE);
}
5)、勾选框功能的添加
当选中十六进制发送的时候,把原来EDIT上的文本直接转成十六进制
获取EDIT中的内容然后格式化内容
wchar_t *p = m_strReceive.GetBuffer(m_strReceive.GetLength());
m_strReceive.ReleaseBuffer();
遍历每一个字符都格式化成16进制
CString str = L"";
int length = m_strSend.GetLength();for (int i = 0; i < length; i++)
{
CStringW strTemp;
strTemp.Format(L"%02X", p[i]);
str = str + strTemp + L" ";
}
m_strSend = str.TrimRight(L" ");
没有勾选勾选框的情况下默认二进制
else //此时要把十六进制转换成字符格式
{
int length = m_strSend.GetLength();
CString str;
for (int i = 0; i < length; i += 3)
{
CStringW strTemp = m_strSend.Mid(i, 2);
wchar_t *p = strTemp.GetBuffer(2);
int num = wcstol(p, NULL, 16);
strTemp.Format(L"%c", num);
str = str + strTemp;
}
m_strSend = str;
}UpdateData(FALSE);
6)、保存文件功能实现
UpdateData(TRUE);
TCHAR szFilter[] = _T("文本文件(*.txt)|*.txt|Word文件(*.doc)|*.doc|所有文件(*.*)|*.*||"); // 设置过滤器
CFileDialog fileDlg(FALSE, _T("doc"), _T("InitFileName"), OFN_HIDEREADONLY | OFN_OVERWRITEPROMPT, szFilter, this);// 构造保存文件对话框
CString strFilePath;// 显示保存文件对话框
if (IDOK == fileDlg.DoModal())
{
strFilePath = fileDlg.GetPathName();
//MessageBox(strFilePath);CFile file; // CFile对象
if (file.Open(strFilePath, CFile::modeCreate | CFile::modeReadWrite))
{
TCHAR *p = m_strreceive.GetBuffer(m_strreceive.GetLength());
file.Write(p, m_strreceive.GetLength());file.Close();
}
}
7)、打开文件功能实现
m_strSend = L"";
TCHAR szFilter[] = _T("文本文件(*.txt)|*.txt|所有文件(*.*)|*.*||");// 设置过滤器
CFileDialog fileDlg(TRUE, _T("txt"), NULL, 0, szFilter, this);// 构造打开文件对话框
CString strFilePath;if (IDOK == fileDlg.DoModal())// 显示打开文件对话框
{
strFilePath = fileDlg.GetPathName(); // 如果点击了文件对话框上的“打开”按钮,则将选择的文件路径显示到编辑框里
//MessageBox(strFilePath);CFile file; // CFile对象
char readBuffer[2048];
if (file.Open(strFilePath, CFile::modeRead))
{
int nRet = file.Read(readBuffer, 2048);for (int i = 0; i < nRet; i++)
{
CString str;
str.Format(L"%c", readBuffer[i]);
m_strSend += str;
}
}
UpdateData(FALSE);
}
7)、实现饮水机的读取温度功能
对话框中的通信类的实例化对象调用通讯类的函数自动发送读取温度的十六进制
UpdateData(TRUE);
CString strOpen;//strOpen来获得按钮上面的文字内容。
GetDlgItemText(IDC_BUTTON_OPEN, strOpen);
if (strOpen == "打开串口")
{
MessageBox(L"串口未打开!", L"串口问题", MB_ICONERROR);
return;
}
else
{
double temp = 0.0;
m_myserialport.ReadTemp(temp);//调用读取温度的函数,发送特定的十六进制。
}
通讯类发送温度ReadTemp函数
m_bReciveFlag = false;
//发送读取指令
BYTE buffer[] = {0XFE,0X03,0X00,0X2D,0X00,0X01,0X00,0X0C};
int lenth = 8;
WriteToPort(buffer,lenth);
// 等待水冷机返回内容
int iTimeOut = 5000; // 5s超时
while (iTimeOut > 0)
{
if (m_bReciveFlag)
{
drefTemp = m_dTemp;
return true;
}iTimeOut -= 50;
Sleep(50);
}
通过勾选框十六进制读取温度的勾选来解析收到的十六进制
bool m_bReciveFlag = true; // 接收到内容标志
CString strHex;
for (uint32_t i = 0; i < iSize; i++)
{
CString hexValue;
hexValue.Format(_T("%02X "), pMsgBuf[i]); // 将每个字节转换为两位十六进制数
strHex += hexValue;
}
// 获取第5和第6个字节的十六进制字符串
// 获取第 4 和第 5 个字节的十六进制字符串
CString hexSubstring2 = strHex.Mid(9, 5); // 假设第 4 和第 5 个字节对应的十六进制数在字符串中的位置为 6~9hexSubstring2.Remove(' ');//去掉空格否则是1遇到空格之间阻断。
// 将十六进制字符串转换为十进制数
unsigned long decimalNumber = _tcstoul(hexSubstring2, NULL, 16);
decimalFloat = static_cast<double>(decimalNumber) / 10.0;
CString decimalString;
decimalString.Format(_T("%.1f"), decimalFloat);
// 将十进制数转换为字符串
// 使用 += 运算符
decimalString += _T("℃");// 将结果输出到EDIT控件上
// 假设EDIT控件的ID为IDC_EDIT_RESULT
pEdit = GetDlgItem(IDC_EDIT1);
if (pEdit != NULL)
{
pEdit->SetWindowText(decimalString);
}
return m_bReciveFlag;