源码网站推荐中国旅游网站的建设
spring所有配置都在WebMvcAutoConfiguration中
其中有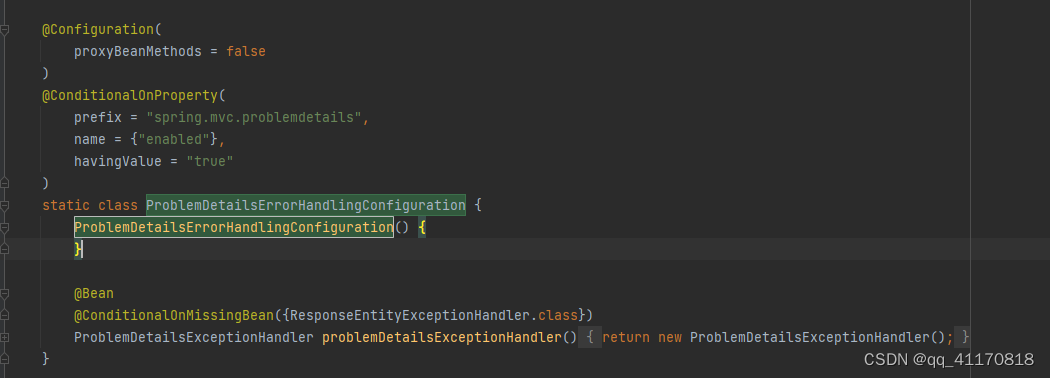
ProblemDetailsExceptionHandler 容器中的一个组件
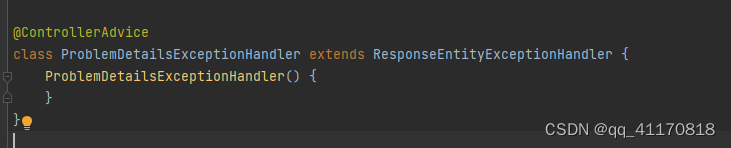
-@ControllerAdvice用来集中处理异常的
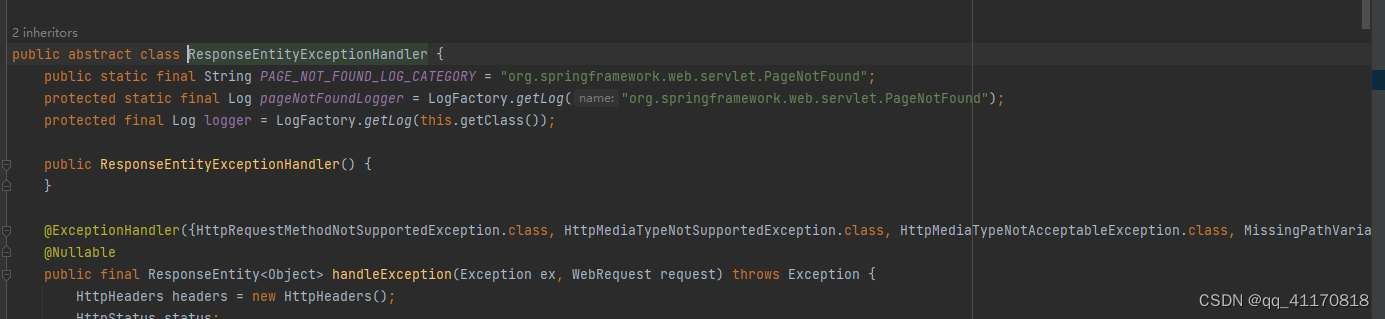
-点进ResponseEntityExceptionHandler 包含这些异常,如果出现以下异常,会被springboot支持以RFC 7807规范返回错误数据 默认未开启
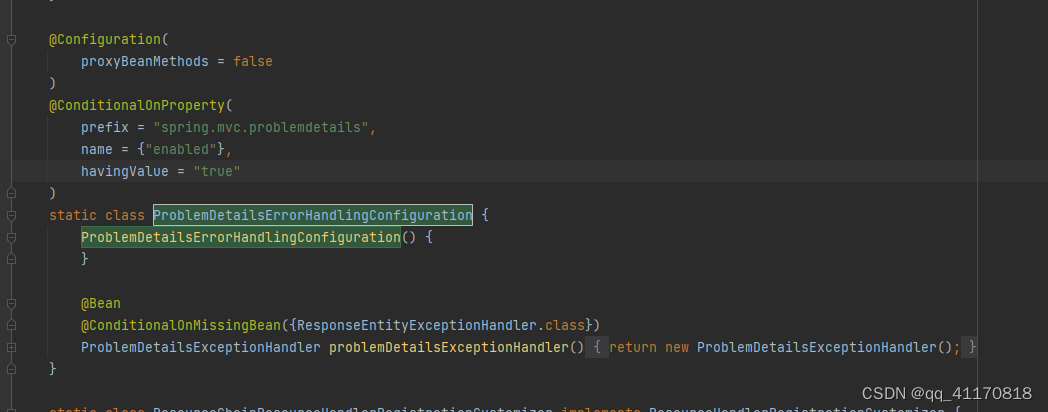
可以看到 配置过这个spring.mvc.problemdetails
没开启的返回内容:
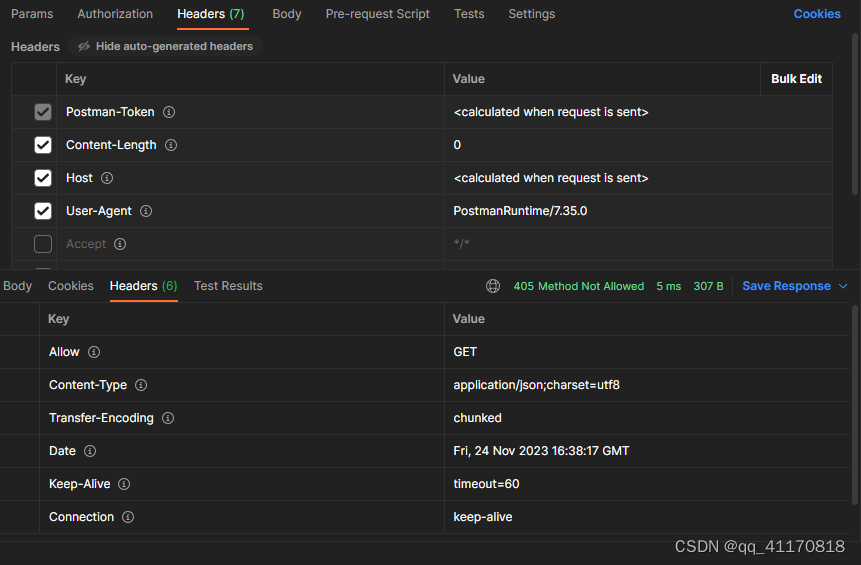
开启后:
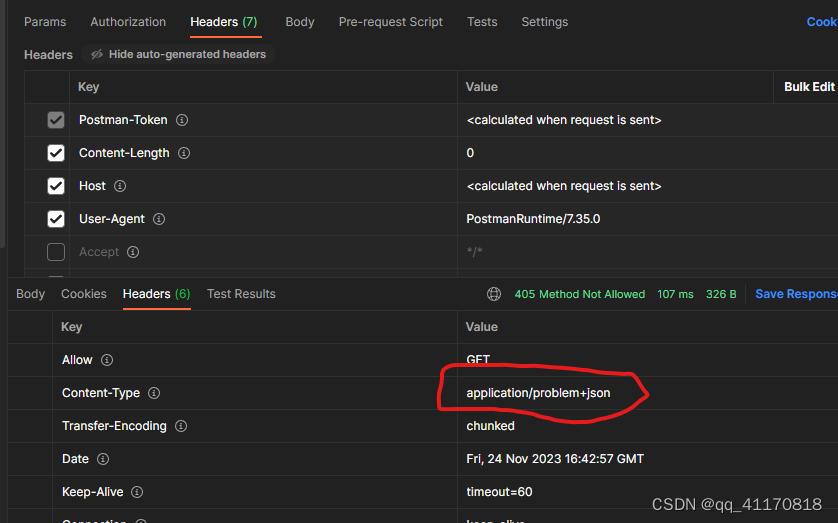
配置开启:
