石家庄便宜做网站湖南系统开发
对于中小型海外仓来说,想在大型集团海外仓同台竞争中获得优胜,提升其管理效率是非常关键的一环。
我们所熟知的wms系统,也就是第三方成熟海外仓系统,正是这些海外仓企业提升管理水平、降低成本的重要工具。
1、wms第三方海外仓系统能为海外仓解决什么问题
wms第三方海外仓系统作为一种仓库管理工具,可以解决海外仓两个方面的难题。一个是基础的仓储管理,一个是科学的数据分析。
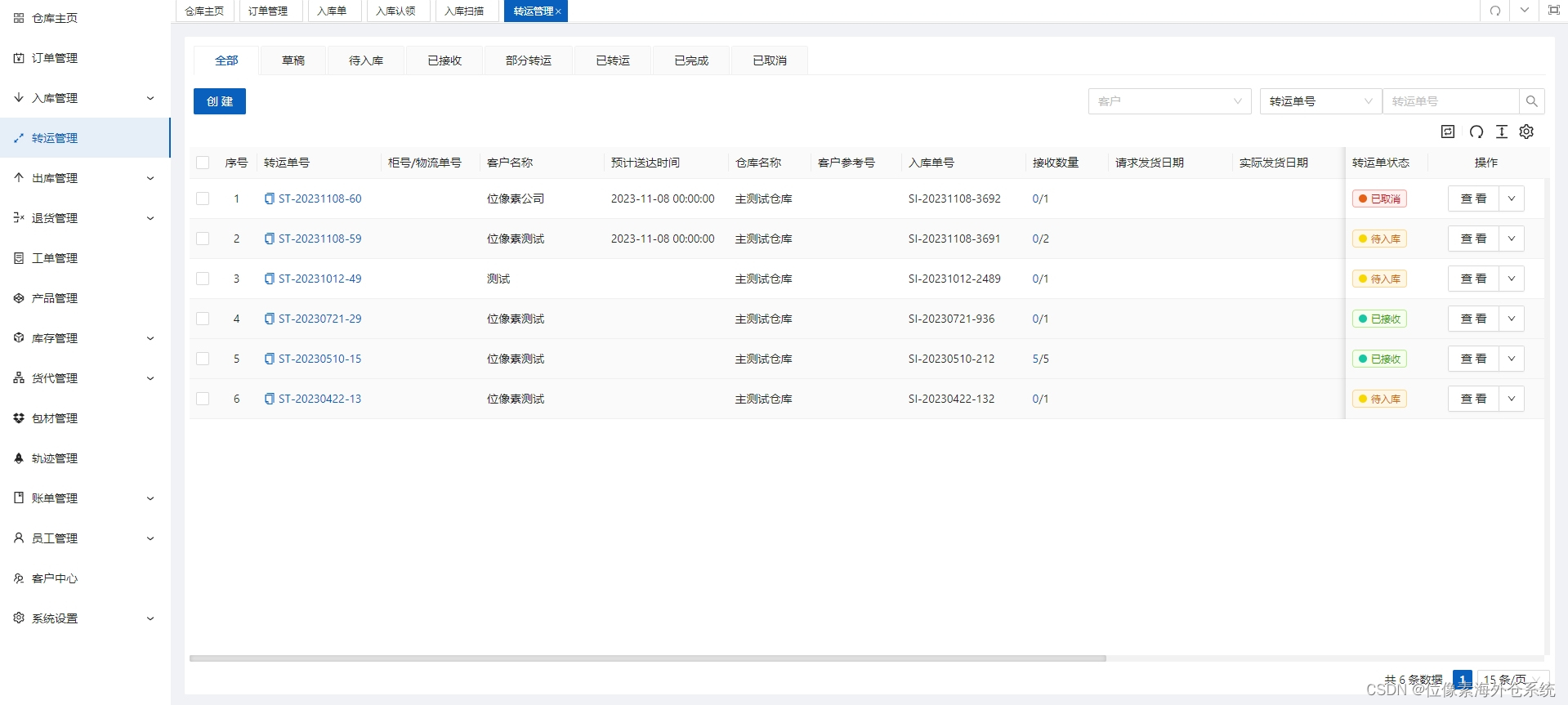
在基础的仓储管理方面,可以提供比较完善的仓库物理空间管理,一件代发的订单管理和物流快递的跟踪等功能。
同时,在数据方面,也可以为海外仓带来更加标准化的管理模式。比如可以做到海外仓库存的实时监控,自动设置调整库存策略等,这就能降低海外仓库存积压,货物周转率低等问题。
同时,高度自动化的算法还能将订单处理,拣货,发货,退货等工作的自动化程度变得更高。这就能最大程度上减少人工的干预,降低出错频率,提升海外仓整体上业务的流畅程度。
2、wms第三方海外仓系统如何让中小型海外仓运营更简单
这主要是体现在三个方面:成本、效益和客户体验。
首先说成本,现在海外仓的成本有两个大类,一个是仓储空间的租赁成本,一个就是高昂的人工成本支出。
wms第三方海外仓系统通过精准化库存管理,科学规划海外仓空间,货架的使用。在很大程度上可以提升海外仓货物周转率,提升海外仓物理空间的利用率,也就变相的降低了仓库的成本。
同时,高度自动化的操作降低了人力的使用,节省了宝贵的人工成本。两个方面的功能可以说帮仓库节省了很大一笔不必要的开支。

其次就是效益的提升,现在的中小型海外仓为什么会遇到收益瓶颈?很大的原因就是业务流程不够顺畅,导致在固定时间内的边际成本过高。
而优化海外仓业务流程,降低边际成本,正是wms第三方海外仓系统擅长的事情。通过实时更新库存信息,自动化处理一件代发订单,物流自动处理等功能,完全可以实现订单的批量处理,自动处理推荐贴标等任务。
这就能极大的提升海外仓业务的流畅程度,降低海外仓运作的边际成本。虽然物理上的仓储空间没变,但是原来的空间盈利能力提升了。
最后就是客户体验方面,做海外仓的都知道,现在跨境电商平台对跨境电商店主的要求越来越严格。那在这种情况下要怎么让这些店主满意,就是海外仓提升客户体验最重要的事情。

通过wms第三方海外仓系统,大幅度提升发货的速度和准确率,避免出现错发,漏发等情况,就能提升客户的满意度,让客户更加忠诚。
最后,对于wms海外仓系统的选择,还是应该充分考虑自己海外仓的规模和业务特点的。现在市场上一些wms海外仓系统动辄几万十几万的费用,对中小型海外仓来说还是偏高的。
所以还是应该尽量选择合作比较灵活的wms系统,降低投入风险。另外,也应该注重仓库工作人员的培训,让wms系统真正的充分被使用,才能将系统的作用发挥到最大。