徐州网站建设4胶州市 网站建设
开发技术不断演进,布局方式也经历了多个阶段的变革。从最初的基于表格布局到 CSS 的浮动布局,再到今天的弹性盒(Flexbox)与 CSS Grid 网格布局,每一种布局方式都有其独特的背景和解决特定问题的优势。

一、CSS Grid 出现之前的布局与网格系统
在 CSS Grid 诞生之前,前端开发者通常使用 float、inline-block、positioning、table 等方法来创建复杂的布局。这些方法可以说是 CSS 布局发展的基础,虽然它们存在许多局限性,但在现代布局体系尚未完善之前,它们依旧是最常用的手段。
1.1 浮动布局(Float)
浮动布局 是最早用于网页布局的 CSS 技术之一,最初是为了让文字环绕图片而设计的。开发者发现,可以利用 float 属性来构建多列布局。
示例:
<div class="container"><div class="column-left">左侧列</div><div class="column-right">右侧列</div>
</div><style>
.container {width: 100%;
}.column-left {float: left;width: 50%;background-color: #eaeaea;
}.column-right {float: right;width: 50%;background-color: #cfcfcf;
}
</style>上例子中,column-left 使用 float: left,column-right 使用 float: right 来创建左右两列的布局。然而,浮动布局存在一些显著的缺陷,比如清除浮动(clearfix)问题,需要额外的技巧来防止父元素的高度坍塌。
1.2 inline-block 布局
为了避免浮动布局带来的清除问题,一些开发者开始使用 inline-block 来构建多列布局。inline-block 的特点是元素依然具有块级元素的宽高,但可以在一行内并排显示。
示例:
<div class="container"><div class="column">第一列</div><div class="column">第二列</div>
</div><style>
.container {font-size: 0; /* 避免 inline-block 之间的空白间隙 */
}.column {display: inline-block;width: 50%;background-color: #ddd;font-size: 16px; /* 恢复子元素的字体大小 */
}
</style>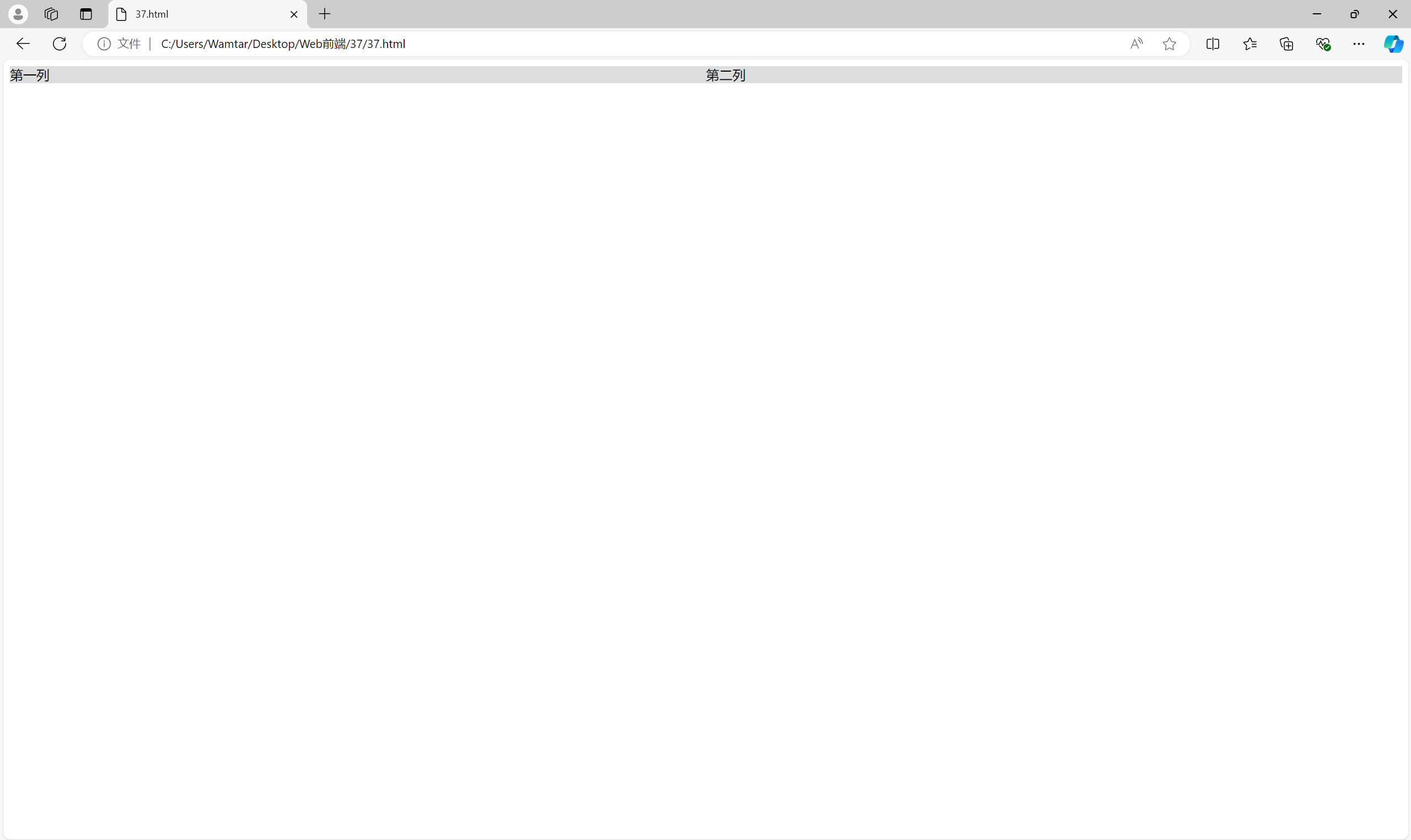
尽管 inline-block 可以解决浮动布局的一些问题,但它仍然有一些不便之处,比如需要清除行内元素之间的空白间隙(通过设置 font-size: 0)。
1.3 绝对定位布局
绝对定位(Positioning) 也是一种传统的布局方式。通过 position: absolute 可以将元素从文档流中移除,并相对于最近的定位祖先元素进行布局。
示例:
<div class="container"><div class="column-left">左侧列</div><div class="column-right">右侧列</div>
</div><style>
.container {position: relative;
}.column-left {position: absolute;left: 0;width: 50%;background-color: #eaeaea;
}.column-right {position: absolute;right: 0;width: 50%;background-color: #cfcfcf;
}
</style>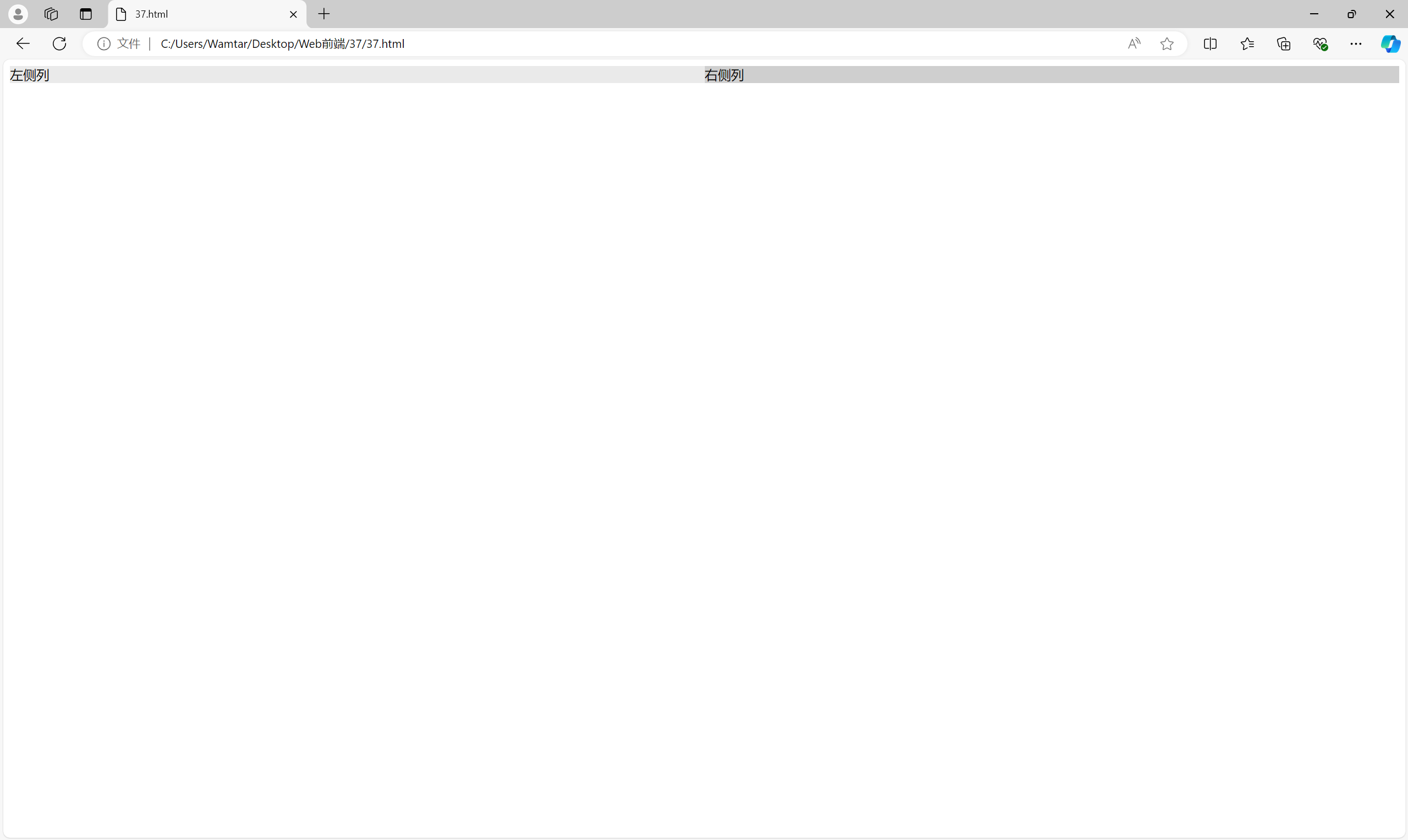
绝对定位布局的灵活性较强,但通常情况下不适用于创建复杂的响应式布局,因为它会导致页面内容脱离文档流,且难以处理复杂的排列关系。
二、两列布局的经典实现
在实际的项目中,两列布局 是一种非常常见的布局形式。常见的两列布局包括主内容区域和侧边栏,它们通常具有不同的宽度。
2.1 基于浮动的两列布局
经典的基于浮动的两列布局,左侧是主内容,右侧是侧边栏:
<div class="container"><div class="main-content">主内容</div><div class="sidebar">侧边栏</div>
</div><style>
.container {width: 100%;overflow: hidden; /* 清除浮动 */
}.main-content {float: left;width: 70%;background-color: #eaeaea;
}.sidebar {float: right;width: 30%;background-color: #cfcfcf;
}
</style>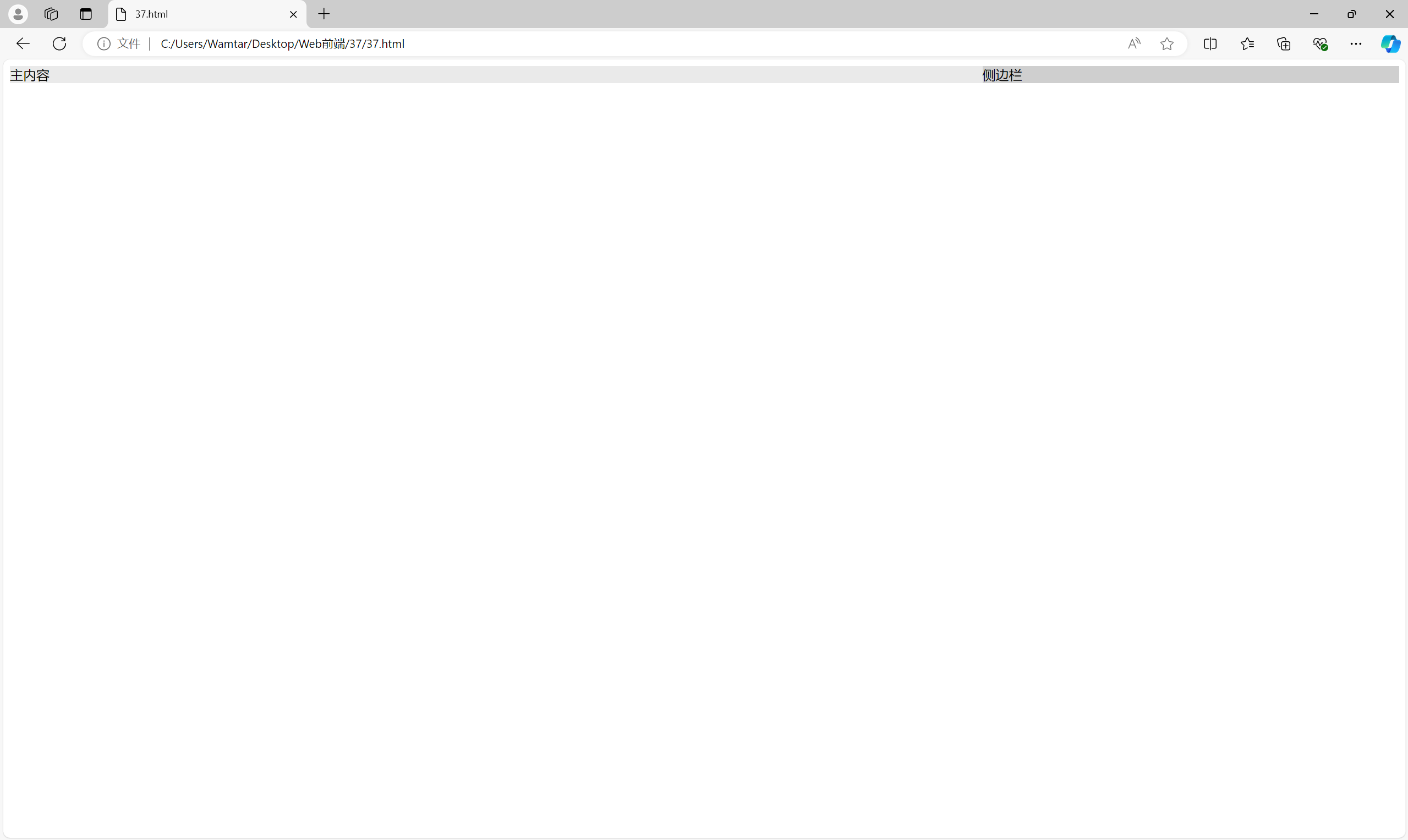
2.2 Flexbox 实现的两列布局
使用 弹性盒布局(Flexbox) 实现两列布局更加简洁和直观。display: flex 可以轻松实现横向排列,并通过 flex-grow 控制列的伸缩性。
<div class="container"><div class="main-content">主内容</div><div class="sidebar">侧边栏</div>
</div><style>
.container {display: flex;
}.main-content {flex-grow: 3;background-color: #eaeaea;
}.sidebar {flex-grow: 1;background-color: #cfcfcf;
}
</style>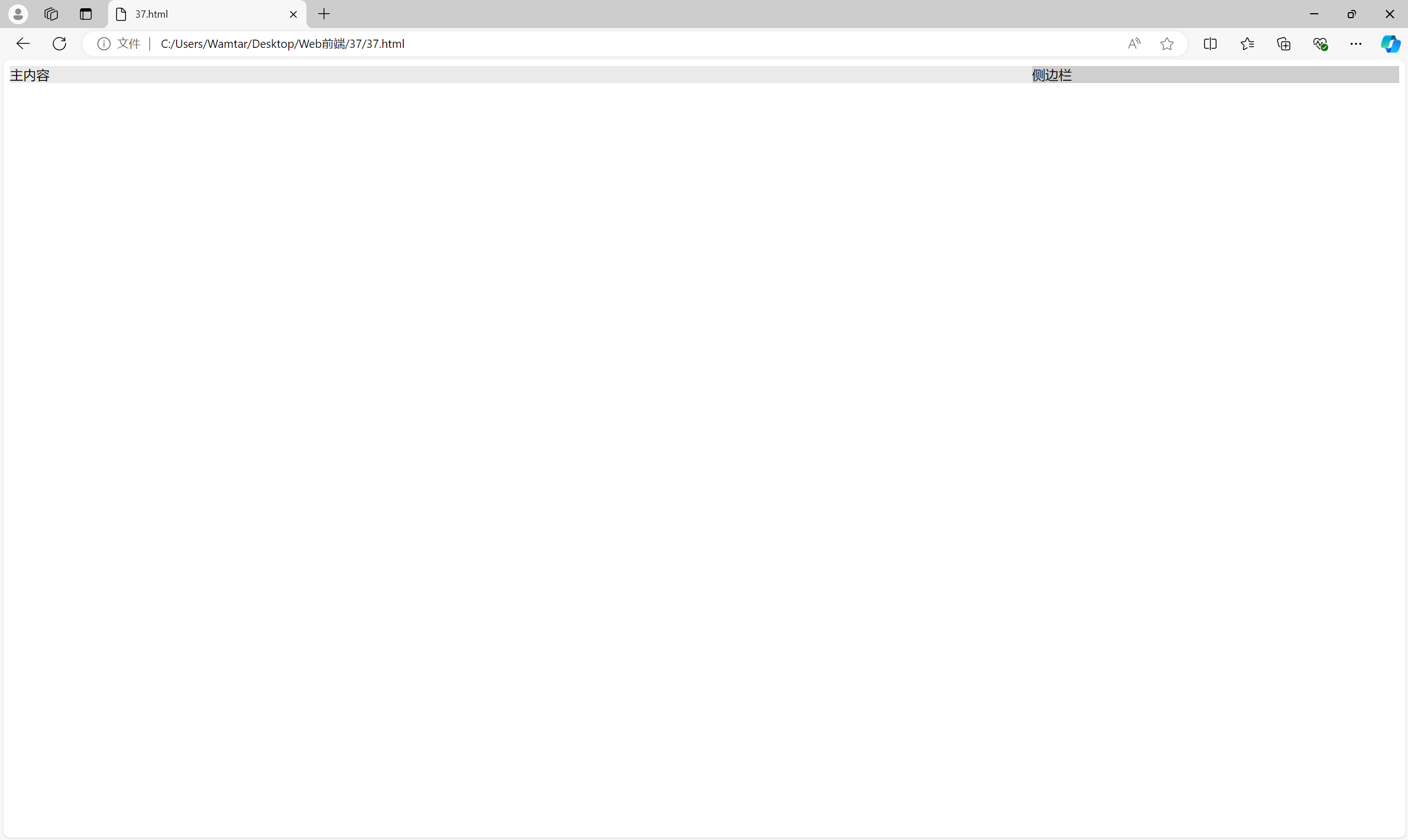
Flexbox 的优势在于它可以自动适应不同的屏幕尺寸,同时在对齐和分布元素方面具有极大的灵活性。
三、创建简单的传统网格框架
3.1 固定宽度网格
固定宽度网格 是最简单的网格布局之一,它通常用于较小的网页或定宽设计中。
<div class="container"><div class="row"><div class="column">列 1</div><div class="column">列 2</div><div class="column">列 3</div></div>
</div><style>
.container {width: 960px;margin: 0 auto;
}.row {display: flex;
}.column {width: 30%;margin: 1%;background-color: #ddd;
}
</style>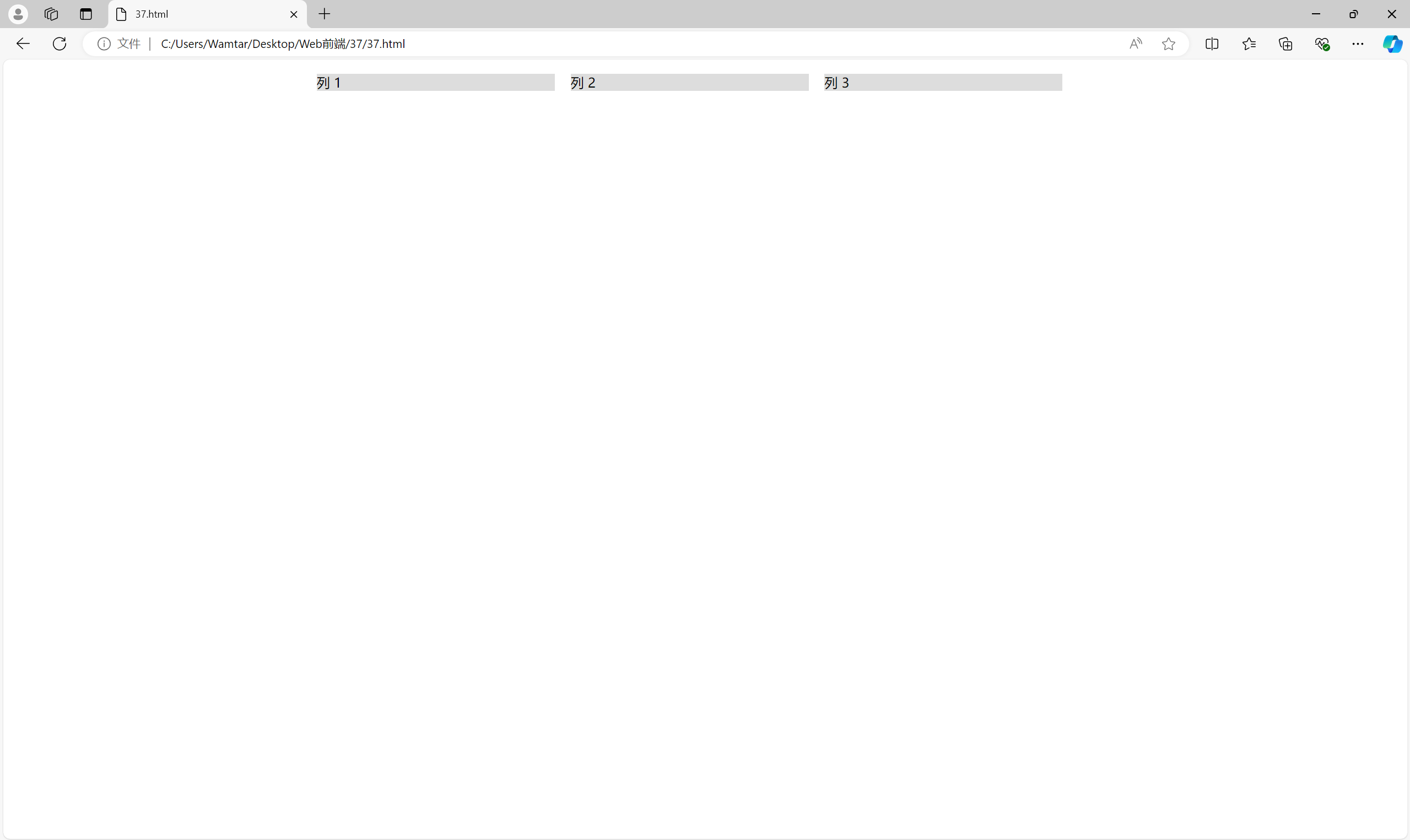
例子中网格是一个 960px 宽的定宽布局。每一列都具有固定的宽度,并通过 margin 保持间距。
3.2 创建液态网格
液态网格可以根据视口宽度自动调整列的宽度。通过使用 calc() 函数,可以轻松地进行计算。
<div class="container"><div class="row"><div class="column">列 1</div><div class="column">列 2</div><div class="column">列 3</div></div>
</div><style>
.container {width: 100%;
}.row {display: flex;
}.column {width: calc(33.33% - 20px);margin: 10px;background-color: #ddd;
}
</style>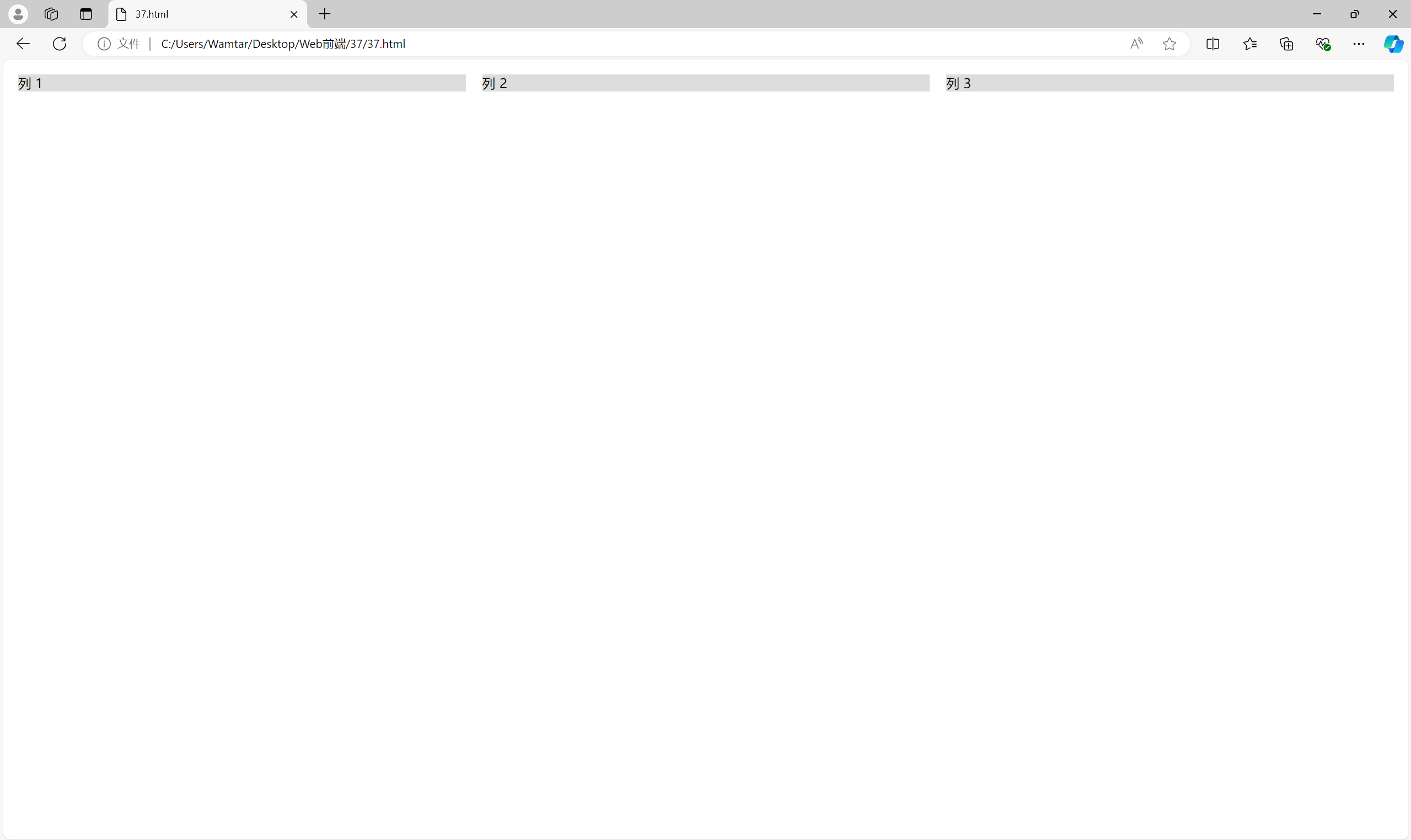
这个例子使用 calc() 函数来减去列之间的间距,使得列的宽度能根据视口的宽度自动调整,创造出更灵活的网格布局。
3.3 语义 vs “无语义” 网格系统
传统的网格系统通常依赖于大量的类名,比如 .col-1、.col-2 等等。这种网格布局方式并不关注内容的语义,导致代码难以维护。
<div class="row"><div class="col-4">内容 1</div><div class="col-8">内容 2</div>
</div>而现代开发更强调语义化布局,即通过使用更具描述性的类名,来表达结构和内容的关系。
<div class="header">头部</div>
<div class="main-content">主要内容</div>
<div class="sidebar">侧边栏</div>3.4 启用偏移容器
在网格布局中,有时需要某些列偏移一定的距离,以便实现更复杂的布局。可以通过增加 margin 或使用 calc() 来实现。
<div class="row"><div class="column offset-2">偏移 2 列</div><div class="column">内容</div>
</div><style>
.column {width: calc(30% - 10px);margin-right: 10px;
}.offset-2 {margin-left: calc(20% + 10px);
}
</style>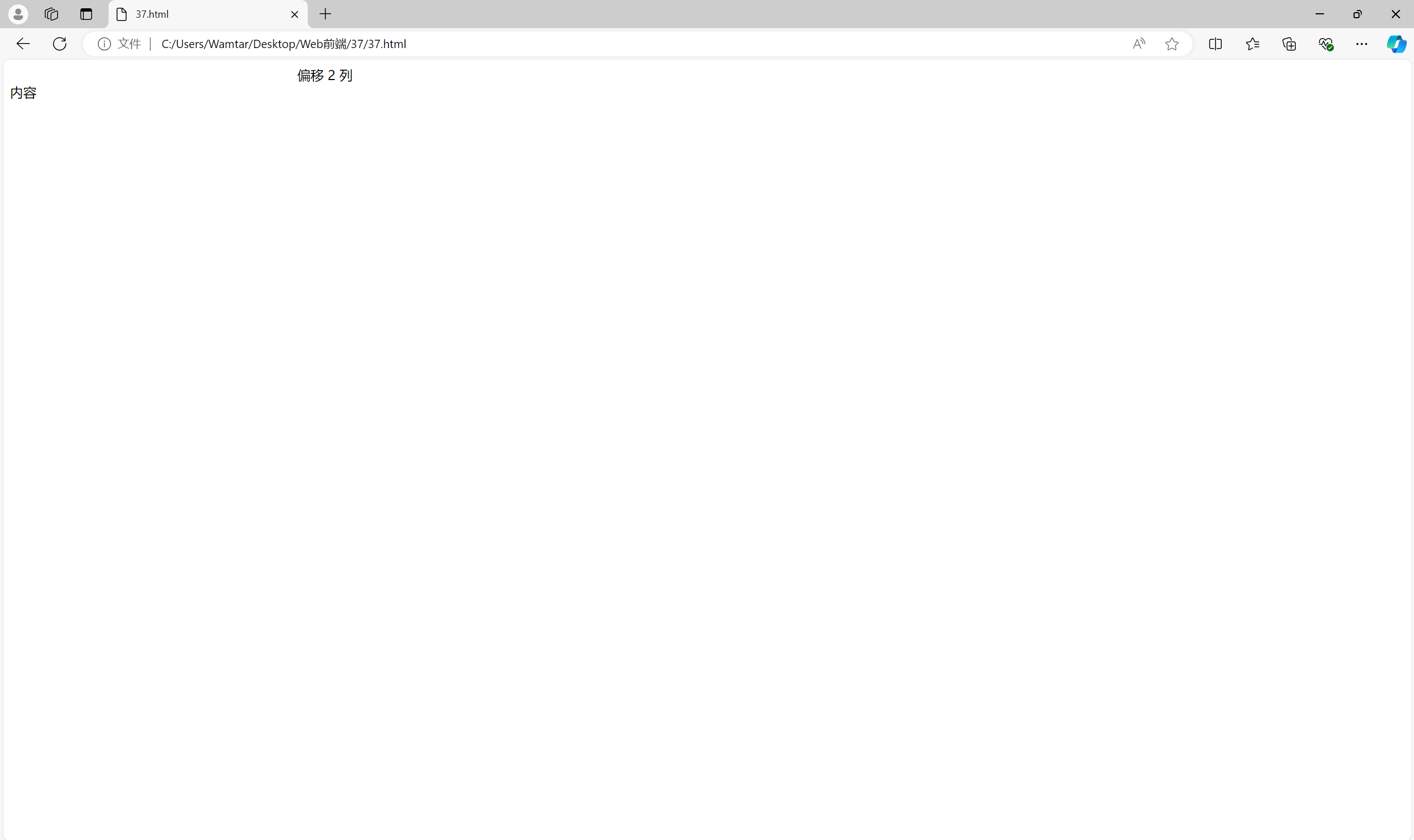
四、浮动网格的限制
浮动网格尽管能实现大部分布局需求,但它有许多局限性,特别是清除浮动和内容对齐问题。这些问题在现代布局方法如 Flexbox 和 CSS Grid 中得到了更好的解决。
1. 清除浮动(Clearfix)问题
当使用浮动布局时,一个最常见的问题是清除浮动(clearfix)。因为浮动的元素会脱离文档流,父容器往往不会自动扩展以包围浮动的子元素。这会导致父容器的高度坍塌,需要开发者手动清除浮动来解决这个问题。
例如,如果没有清除浮动的情况下,父元素的背景颜色不会扩展以包含所有子元素:
<div class="container"><div class="float-box">浮动框 1</div><div class="float-box">浮动框 2</div>
</div><style>
.container {background-color: #eaeaea; /* 背景颜色不会扩展 */
}.float-box {float: left;width: 50%;background-color: #cfcfcf;
}
</style>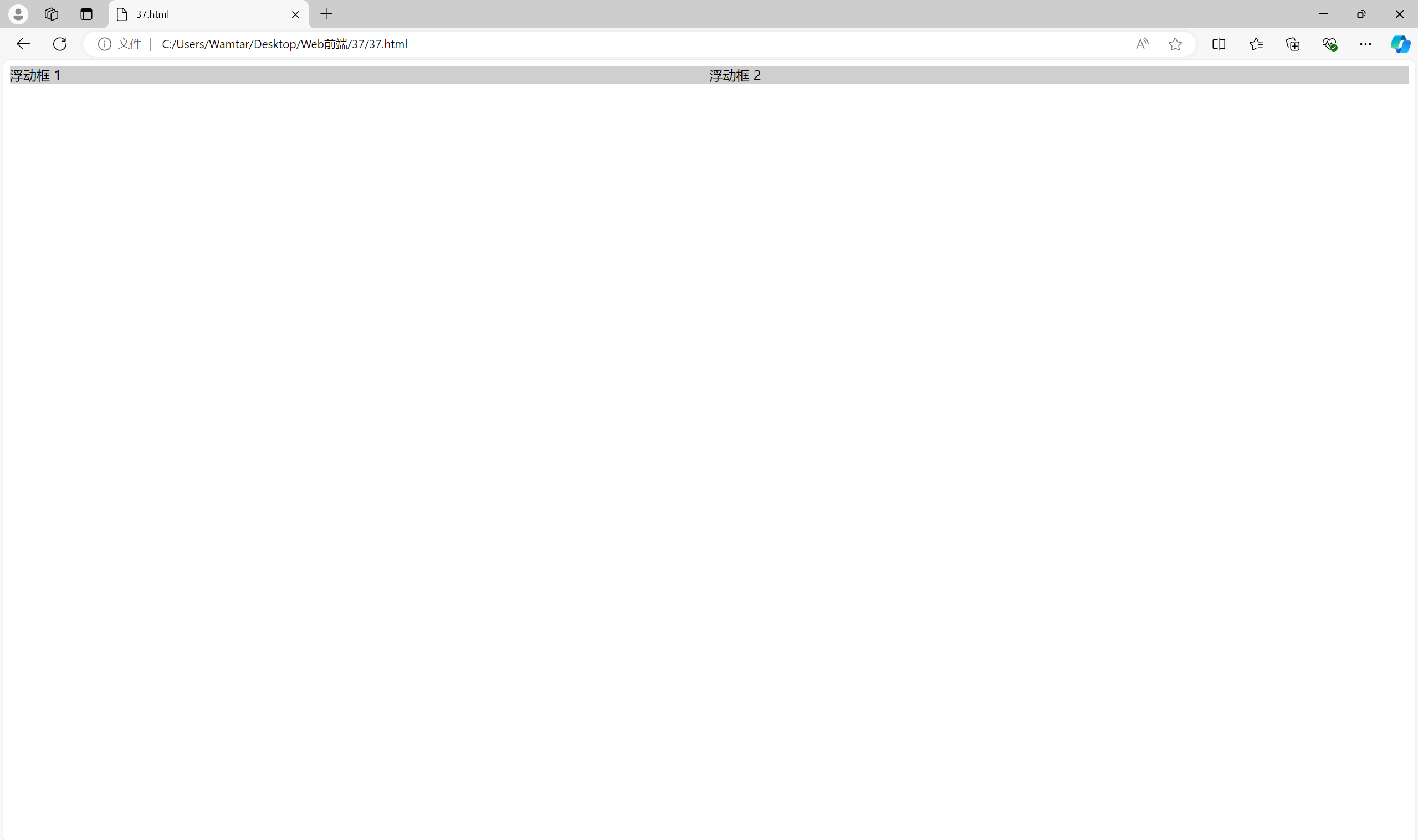
解决方案: 添加一个伪元素清除浮动,或在容器元素上使用overflow: hidden或clearfix类。
.container::after {content: "";display: table;clear: both;
}2. 响应式布局不便
CSS浮动布局在响应式设计方面的支持较差。因为浮动元素的宽度通常是以固定值或百分比来定义的,所以当视口(viewport)宽度发生变化时,必须手动调整布局的CSS代码,这使得代码难以维护和扩展。与Flexbox和CSS Grid相比,浮动布局缺乏对元素自动对齐和分布的支持。
3. 无法轻松实现垂直居中
浮动布局的一个显著限制是无法轻松实现垂直居中对齐。由于浮动元素不占用其所在行的空间,开发者必须使用复杂的技巧(如使用margin调整)来实现垂直居中,这与现代布局方法(如Flexbox的align-items或CSS Grid的align-content)的简单和直观形成鲜明对比。
/* 常见的垂直居中技巧 */
.parent {position: relative;height: 200px;
}.child {position: absolute;top: 50%;transform: translateY(-50%);
}4. 浮动元素的顺序问题
使用浮动布局时,元素的顺序是固定的,即元素在HTML文档中的排列顺序决定了它们在页面上的显示顺序。这对于需要不同屏幕大小下重新排序的响应式布局来说是一个很大的限制。而使用CSS Grid或Flexbox,开发者可以通过简单的CSS规则来改变元素的排列顺序,而不需要调整HTML结构。
/* Flexbox 的简单 reorder 例子 */
.parent {display: flex;
}.child:first-child {order: 2;
}.child:last-child {order: 1;
}5. 边距重叠(Margin Collapse)
浮动元素在处理相邻元素的边距(margin)时可能会出现边距重叠问题,这意味着两个相邻的浮动元素的边距可能会意外地合并,导致布局出现问题。解决这
6. 无法轻松实现复杂的网格布局
浮动布局更适合简单的布局需求。当需要实现复杂的网格布局(如多列、多行且包含嵌套的子网格)时,浮动布局的代码会变得异常复杂且难以维护。相反,CSS Grid提供了一种更简
7. 缺乏对齐和分布的高级功能
浮动布局不具备CSS Grid或Flexbox提供的对齐(alignment)和分布(distribution)功能。比如,CSS Grid可以轻松控制网格项之间的间距,Flexbox可以让元素在容器中均匀分布或对齐。浮动布局只能通过手动计算margin和padding来实现,这在大型项目中变得非常繁琐和易错。
五、弹性盒网格(Flexbox)
Flexbox 是一种全新的 CSS 布局方式,专为灵活布局设计。与传统的浮动布局相比,它具有更简洁的语法和更强的适应性。
Flexbox 可以轻松实现各种复杂布局:
<div class="container"><div class="item">Item 1</div><div class="item">Item 2</div><div class="item">Item 3</div>
</div><style>
.container {display: flex;justify-content: space-between;
}.item {width: 30%;background-color: #ddd;
}
</style>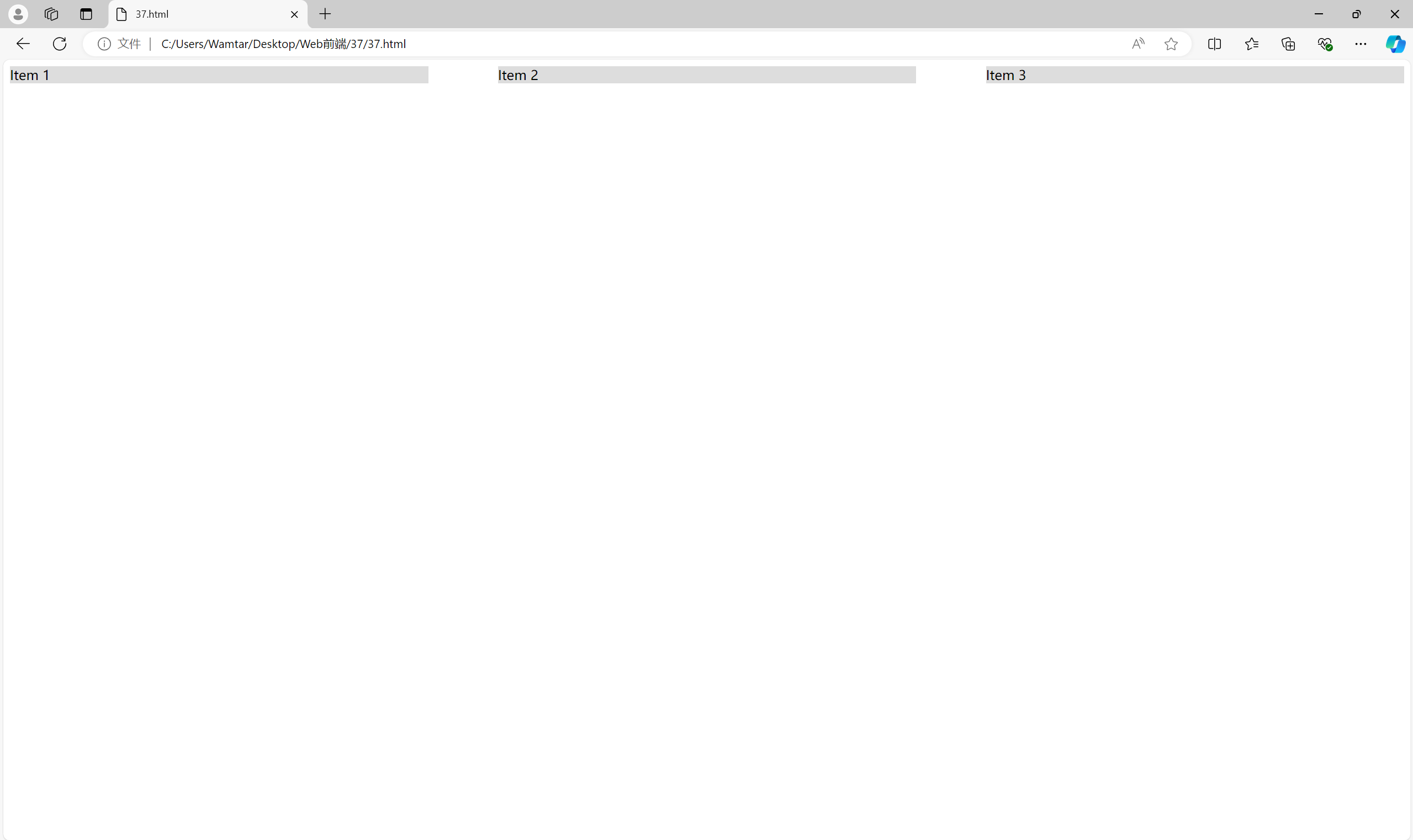
例子中justify-content: space-between 可以让所有子元素在容器中均匀分布,而不需要手动设置 margin。
六、第三方网格系统
在实际项目中,很多人喜欢使用第三方网格系统来加速开发,如 Bootstrap、Foundation 等。
6.1 Bootstrap网格系统
Bootstrap的网格系统基于 flexbox,采用一个包含最多12个列的布局,可以根据屏幕大小自动调整布局。其响应式设计通过定义不同的断点,使网页能够适配不同设备(如手机、平板、桌面显示器等)。
核心特性:
- 基于Flexbox:通过
flexbox提供灵活的列对齐和排列方式。 - 12列布局:默认网格系统是12列,每行最多容纳12个“列单位”,可以根据需要自由分配列宽。
- 响应式断点:提供5种预定义的响应式断点(extra small, small, medium, large, extra large)。
- 可嵌套的网格:列内可以再包含一套网格系统,形成嵌套布局。
使用示例:
<div class="container"><div class="row"><div class="col-sm-4">列1</div><div class="col-sm-4">列2</div><div class="col-sm-4">列3</div></div>
</div>
-
.container:定义一个固定宽度的容器。 -
.row:用于创建一行,行内的列将被水平排列。 -
.col-sm-4:表示在小屏幕及以上的设备中,每个列占据4个网格单位(共12个单位)。
断点说明:
Bootstrap定义了几个重要的断点类,以便为不同的屏幕尺寸设置不同的列数:
-
col-xs- (超小屏幕,如手机) -
col-sm- (小屏幕,如平板) -
col-md- (中屏幕,如笔记本) -
col-lg- (大屏幕,如桌面显示器) -
col-xl- (超大屏幕)
例如,col-md-6意味着在中屏及以上的设备上,这一列占据12列中的6列,也就是50%的宽度。
其他特性:
- Offset列:使用
offset类为列增加空白间距。 - Order类:使用
order类轻松改变列的显示顺序。
<div class="row"><div class="col order-2">列2</div><div class="col order-1">列1</div>
</div>6.2 Foundation网格系统
Foundation的网格系统非常灵活,也基于 flexbox,与Bootstrap相似,但在某些方面提供了更简便的语法和定制选项。Foundation的网格系统同样支持12列的响应式布局,但其断点系统和类名略有不同。
核心特性:
- 基于Flexbox或CSS Grid:用户可以选择使用
flexbox或CSS Grid进行布局。 - 12列布局:同样的12列布局系统,每行最多容纳12个网格单位。
- 可选断点:Foundation允许用户自己定义断点,默认提供了小、中、大、超大的断点设置。
- 灵活的间距控制:允许更细粒度的列间距控制。
使用示例:
<div class="grid-container"><div class="grid-x grid-padding-x"><div class="cell small-4">列1</div><div class="cell small-4">列2</div><div class="cell small-4">列3</div></div>
</div>
-
.grid-container:定义一个网格容器。 -
.grid-x:表示水平布局(x轴方向)。 -
.cell:每一个网格单元。 -
small-4:表示在小屏幕及以上的设备中,每个单元占4个网格单位(共12个单位)。
断点说明:
Foundation中的断点与Bootstrap类似,但它的命名方式略有不同,用户还可以自定义断点。
-
small-:小屏幕 -
medium-:中屏幕 -
large-:大屏幕 -
xlarge-:超大屏幕
其他特性:
- 嵌套网格:和Bootstrap一样,Foundation支持嵌套网格布局。
- 自动尺寸单元:使用
auto类,Foundation允许单元自动调整大小,填满剩余空间。
<div class="grid-x grid-padding-x"><div class="cell auto">自动宽度</div><div class="cell small-6">固定宽度</div>
</div>6.3 比较与总结
相似之处:
- 都基于12列网格系统。
- 支持响应式布局,允许开发者根据屏幕大小调整内容。
- 都使用
flexbox作为底层布局机制,提供灵活的列对齐和排序。
不同之处:
- 断点设置:Bootstrap的断点固定且命名简单,而Foundation允许用户自定义断点。
- 语法简洁度:Foundation的网格语法相对更简洁,例如它使用
cell代替Bootstrap的col。 - 定制性:Foundation更灵活,尤其在定制断点和控制列间距方面表现出色。
- 兼容性:Bootstrap在社区和第三方支持上稍显优势,因为它的用户和扩展库更多。
两者都非常强大,选择使用哪个框架通常取决于项目需求以及开发团队的偏好。如果你需要一个更灵活的断点系统或喜欢简化的语法,Foundation是不错的选择;如果你想要一个社区支持更广泛且集成了更多组件的系统,Bootstrap则更适合。

如有表述错误及欠缺之处敬请指正补充。