网站开发毕业任务书在阿里云上建立网站的步骤
🔒 保护您的iOS应用免受恶意攻击!在本篇博客中,我们将介绍如何使用HTTPCORE DES加密来加固您的应用程序,并优化其安全性。通过以下步骤,您可以确保您的应用在运行过程中不会遭受数据泄露和未授权访问的风险。

摘要
本文将指导您如何通过改变编译方式、处理静态库、解决C++头文件引用问题以及进行IPA重签名等步骤来加固您的iOS Swift应用程序。这些方法将帮助您提高应用程序的安全性,防止黑客攻击和数据泄露。
引言
为了保护您的应用程序免受潜在的攻击,您需要采取适当的安全措施。HTTPCORE DES加密算法是一种强大的加密技术,可以有效地保护您的数据免受未授权访问。在本文中,我们将介绍如何将HTTPCORE DES加密集成到您的iOS Swift应用程序中,并通过其他优化步骤来加固您的应用。
正文
步骤1:改变编译方式
由于cmake使用ar打出的静态库不支持iOS系统,我们需要改为使用Xcode命令生成可执行文件及Xcode工程项目,然后再打包静态库。您可以按照以下命令进行操作:
cmake .. -G Xcode -T buildsystem=1 \
-DCMAKE_SYSTEM_NAME=iOS \
"-DCMAKE_OSX_ARCHITECTURES=armv7;armv7s;arm64;i386;x86_64" \
-DCMAKE_OSX_DEPLOYMENT_TARGET=9.0 \
-DCMAKE_INSTALL_PREFIX=`pwd`/_install \
-DCMAKE_XCODE_ATTRIBUTE_ONLY_ACTIVE_ARCH=NO \
-DCMAKE_IOS_INSTALL_COMBINED=YES
步骤2:解决Xcode构建系统兼容性问题
在Xcode命令生成可执行文件后,如果遇到打包静态库时报错的情况,可能是由于Xcode的新构建系统与cmake不兼容所致。您可以通过添加以下命令来解决这个问题:
-T buildsystem=1
步骤3:解决C++头文件引用问题
当Swift类引用C++库时,可能会出现头文件不存在的错误。这是因为Swift不具备C++特性,所以我们需要使用Objective-C++来解决这个问题。您可以通过创建.mm文件,并在其中转换C++代码为Objective-C++代码,然后在OC和Swift类中使用该文件。
步骤4:将白名单检测逻辑放入静态库
如果您希望将启动执行包名白名单检测的逻辑放入静态库中,您可以通过在.mm文件中调用C++方法来实现。在OC的+load方法中调用C++的包名白名单检测,并在C++方法中调用OC的获取bundleId的方法。这样可以缩短操作路径,并符合Android与iOS通用逻辑。
步骤5:合并多个静态库
当需要合并多个静态库时,使用ar解包可能会遇到报错的情况,因为静态库包含多个架构,无法直接使用ar解包。为了解决这个问题,您可以指定单个架构解包,然后再进行合并。然而,这种方法比较复杂,我们建议改为使用Xcode libtool来合并多个静态库,并将其放入cmakelist文件中,最后使用cmake命令进行打包。
加固混淆
为了保护IOS SWIFT应用程序不被攻击者攻击,我们需要进行代码混淆和加固操作。以下是一些常见的加固混淆方法:
-
使用iPAGuard等工具进行IPA重签名
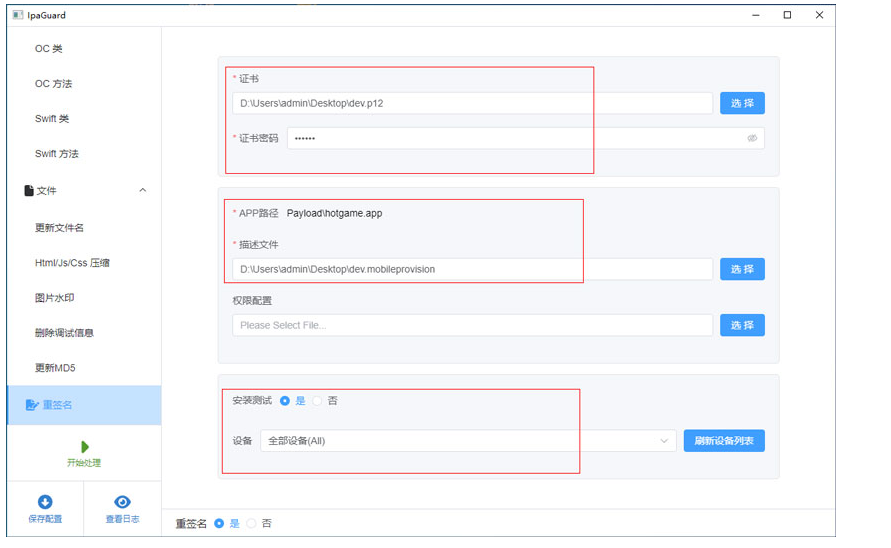
-
使用iPAGuardr对JavaScript代码进行混淆,只要是ipa都可以,不限制OC,Swift,Flutter,React Native,H5类app。可对IOS ipa 文件的代码,代码库,资源文件等进行混淆保护。 可以根据设置对函数名、变量名、类名等关键代码进行重命名和混淆处理,降低代码的可读性,增加ipa破解反编译难度。可以对图片,资源,配置等进行修改名称,修改md5。
以上是一些常见的加固混淆方法,我们可以根据实际情况选择合适的方法来加固我们的React Native应用程序。
总结
通过采取一系列加固措施,您可以保护您的iOS Swift应用免受恶意攻击。本文介绍了使用HTTPCORE DES加密来加固您的应用程序,并优化其安全性的方法。遵循上述步骤,您可以提高您的应用程序的安全性,减少数据泄露和未授权访问的风险。
参考资料
- ipaguard官方文档
- ipaguard重签名与加固混淆文档