手机端网站的区别wordpress中文网站优化
因为这个项目license问题无法开源,更多技术支持与服务请加入我的知识星球。
接下来讲待办的流程处理
1、根据这个vue3新的框架,按钮代码如下:
/*** 操作栏*/function getTableAction(record) {return [{label: '处理',onClick: handleProcess.bind(null, record),},{label: '委派',onClick: SelectUser.bind(null,record, '1'),}, {label: '转办',onClick: SelectUser.bind(null,record, '2'),}];}2、其中handleProcess代码,跳转到处理界面进行流程的处理
// 跳转到处理页面function handleProcess(record: Recordable){router.push({ path: '/flowable/task/record/index',query: {procInsId: record.procInsId,deployId: record.deployId,taskId: record.taskId,businessKey: record.businessKey,nodeType: record.nodeType,appType: record.appType,finished: true}})}3、这里正常审批的界面如下:
<!--审批正常流程--><a-modal:z-index="100":title="completeTitle"@cancel="completeOpen = false"v-model:open="completeOpen":width="checkSendUser ? '60%' : '40%'"append-to-body><el-form ref="refTaskForm" :model="taskForm" label-width="160px"><el-form-item v-if="checkSendUser" prop="targetKey" style="max-height: 300px; overflow-y: scroll"><el-row :gutter="20"><el-col :span="12" :xs="24"><h6>待选人员</h6><el-table ref="singleTable" :data="userDataList" border style="width: 100%" @selection-change="handleSelectionChange"><el-table-column type="selection" width="50" align="center" /><el-table-column label="用户名" align="center" prop="realname" /><el-table-column label="部门" align="center" prop="orgCodeTxt" /></el-table></el-col><el-col :span="8" :xs="24"><h6>已选人员</h6><el-tag v-for="(tag, index) in userData" :key="index" closable @close="handleClose(tag)">{{ tag.realname }} {{ tag.orgCodeTxt }}</el-tag></el-col></el-row></el-form-item><el-form-item label="处理意见" prop="comment" :rules="[{ required: true, message: '请输入处理意见', trigger: 'blur' }]"><el-input type="textarea" v-model="taskForm.comment" placeholder="请输入处理意见" /></el-form-item><el-form-item label="附件" prop="commentFileDto.fileurl"><j-upload v-model="taskForm.commentFileDto.fileurl" ></j-upload> </el-form-item><el-form-item label="选择抄送人" prop="ccUsers"><div style ="width:100%" ><j-select-user-by-dept v-model="taskForm.ccUsers" placeholder="请选择抄送人" /> </div></el-form-item><el-form-item label="选择下一审批人" prop="nextUsers" placeholder="请选择下一审批人"><div style ="width:100%" ><j-select-user-by-dept v-model="taskForm.nextUsers" /> </div><el-tag type="danger">注意: 多实例目前仅支持选择下一个审批人数要与原先设置的人数一致</el-tag></el-form-item></el-form><template #footer class="dialog-footer"><el-button @click="completeOpen = false">取 消</el-button><el-button type="primary" @click="taskComplete(true)">同 意</el-button><el-button type="primary" :disabled="!bapproved" @click="taskComplete(false)">拒 绝</el-button></template></a-modal>
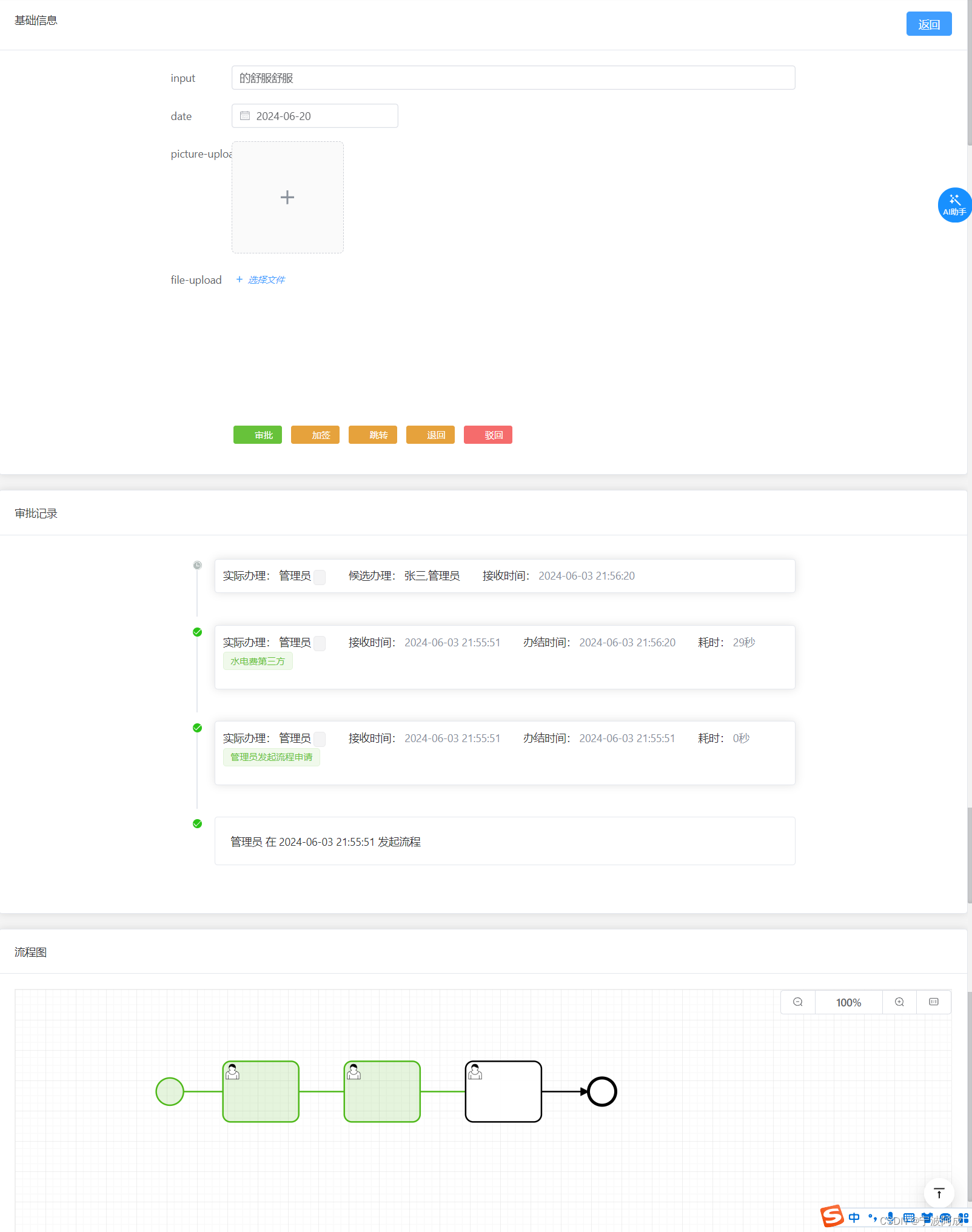
正常情况下,上面输入意见后就可以同意完成了。
但对于可能多人的情况下,需要选择一个人进行处理(这里不是多实例,只能单人处理)
如下面例子
4、总体审批这个节点后效果图如下: