免费自做网站公司推广文案
目录
HTTPS
公钥和密钥
加密解密方式:
https搭建步骤
强调一下
1、准备环境
2、配置文件
3、制作证书
4、进行设置
HTTPS
啥是https,根据百度:HTTPS (全称:Hypertext Transfer Protocol Secure),是以安全为目标的 HTTP 通道,在HTTP的基础上通过传输加密和身份保证保证了传输过程的安全性。HTTPS 在HTTP 的基础下加入SSL,HTTPS 的安全基础是 SSL,因此加密的详细内容就需要 SSL。HTTPS 存在不同于 HTTP 的默认端口及一个加密/身份验证层(在 HTTP与 TCP 之间)。这个系统提供了身份验证与加密通讯方法。它被广泛用于万维网上安全敏感的通讯,例如交易支付等方面。所以可以说https是一个在网站上的加密方法
之前我们拿nginx搭的网站用的协议是http的,所以之前的网站的保密性不是特别高 那现在就用nginx来搭建一个https网站
那现在就用nginx来搭建一个https网站
公钥和密钥
公钥:公共密钥 开放
密钥:私有密钥 保密
加密解密方式:
jack发信息给marry
1、 jack用自己的公钥对信息进行加密传送给marry,marry用jack的私钥进行解密
公(j)➡️私(j) 不可行:因为用公钥进行加密,公钥一般可以在网站上下载,但私钥在自己的电脑上,如果对方离得远无法进行拷贝,那就不可行
2、jack用marry的公钥进行加密发给marry,marry用自己的私钥解密
公(m)➡️私(m) 可行 很私密:因为对方的公钥可以下载,对方的私钥下载不了,,用对方的公钥进行加密,则对方要用自己的私钥进行解密,相当私密
3、jack用自己的私钥进行加密发给marry,marry用jack的公钥进行解密
私(j)➡️公(j) 不可行 毫无私密性:因为拿自己的私钥进行加密后,解密需要公钥,而公钥都可以在互联网上下载到,所以所有人都可以解密信息
4、jack用marry的私钥进行加密,marry用自己的公钥进行解密
不可行,jack无法获得对方的私钥,无法进行加密
所以根据以上可以得到最好的加密方法就是第二种2(对公加密,对私解密)
那么https的大致分为三个阶段
(1)认证服务器:浏览器内置一个受信任的CA机构列表,并保存了这些CA机构的证书。第一阶段服务器会提供经CA机构认证颁发的服务器证书,如果认证该服务器证书的CA机构,存在于浏览器的受信任CA机构列表中,并且服务器证书中的信息与当前正在访问的网站(域名等)一致,那么浏览器就认为服务端是可信的,并从服务器证书中取得服务器公钥,用于后续流程。否则,浏览器将提示用户,根据用户的选择,决定是否继续。当然,我们可以管理这个受信任CA机构列表,添加我们想要信任的CA机构,或者移除我们不信任的CA机构。
(2)协商会话密钥:客户端在认证完服务器,获得服务器的公钥之后,利用该公钥与服务器进行加密通信,协商出两个会话密钥,分别是用于加密客户端往服务端发送数据的客户端会话密钥,用于加密服务端往客户端发送数据的服务端会话密钥。在已有服务器公钥,可以加密通讯的前提下,还要协商两个对称密钥的原因,是因为非对称加密相对复杂度更高,在数据传输过程中,使用对称加密,可以节省计算资源。另外,会话密钥是随机生成,每次协商都会有不一样的结果,所以安全性也比较高。
(3)加密通讯:此时客户端服务器双方都有了本次通讯的会话密钥,之后传输的所有Http数据,都通过会话密钥加密。这样网路上的其它用户,将很难窃取和篡改客户端和服务端之间传输的数据,从而保证了数据的私密性和完整性
https搭建步骤
强调一下
key是私钥文件
csr是证书签名请求文件,用于提交给证书颁发机构(CA)对证书签名
crt是由证书颁发机构(CA)签名后的证书,或者是开发者自签名的证书,包含证书持有人的信息,持有人的公钥,以及签署者的签名等信息
1、准备环境
还是之前的nginx,在linux上下好nginx后(记得启动nginx,以及开机自启动,关闭防火墙),输入指令nginx -V,注意是大写的V,小写的v只能显示版本啥的,大写的还会显示其编译器以及带有的模块
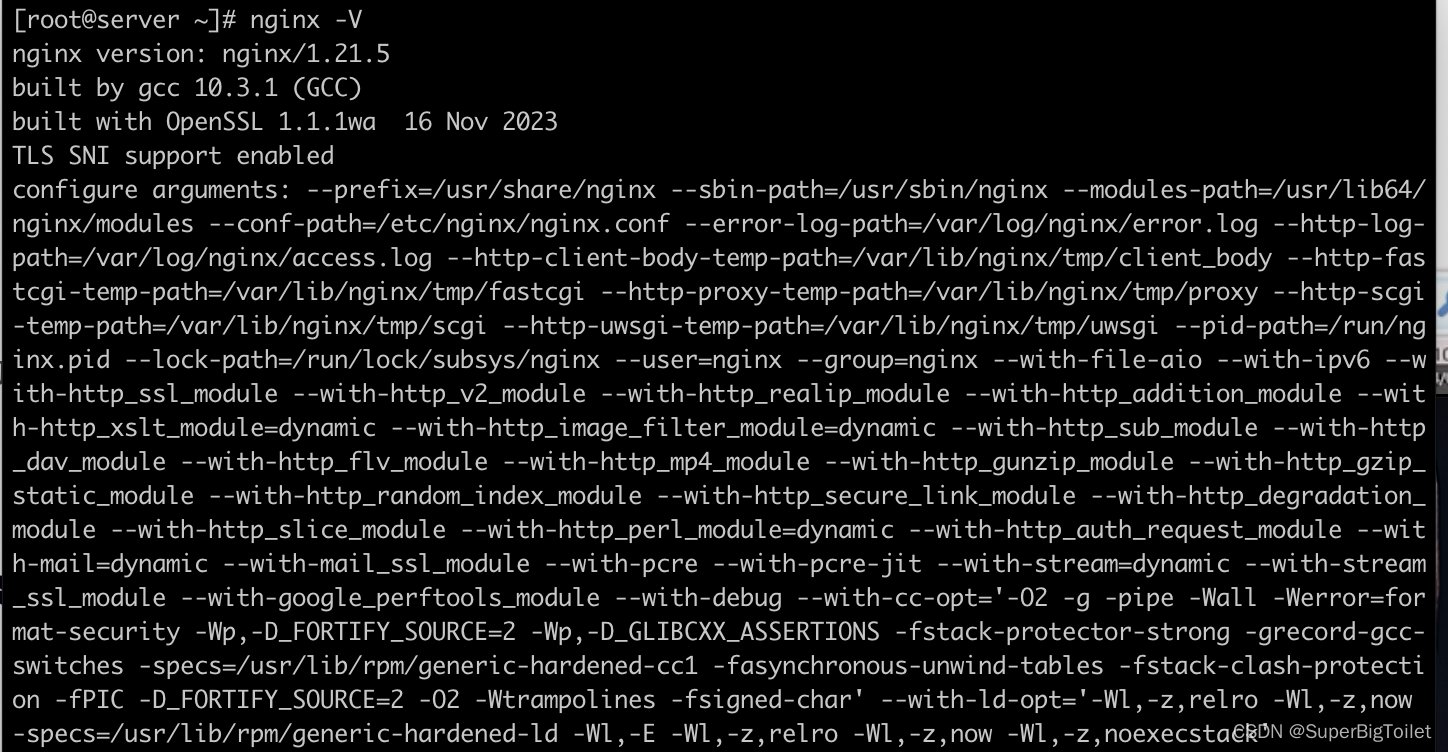
在显示出来的模块里寻找是否有一个“--with-http_ssl_module”若没有则需要安装ssl模块,则需要输入yum install mod_ssl即可
2、配置文件
证书文件:/.../xxxx.crt结尾——公钥
私钥文件:/.../xxxx.key结尾——私钥
(证crt,私key)
进入nginx的配置文件里“ vim etc/nginx/nginx.conf " 找到server板块,你可以在里面看到http的设置和https的设置(https,没设置的话是被注释掉的)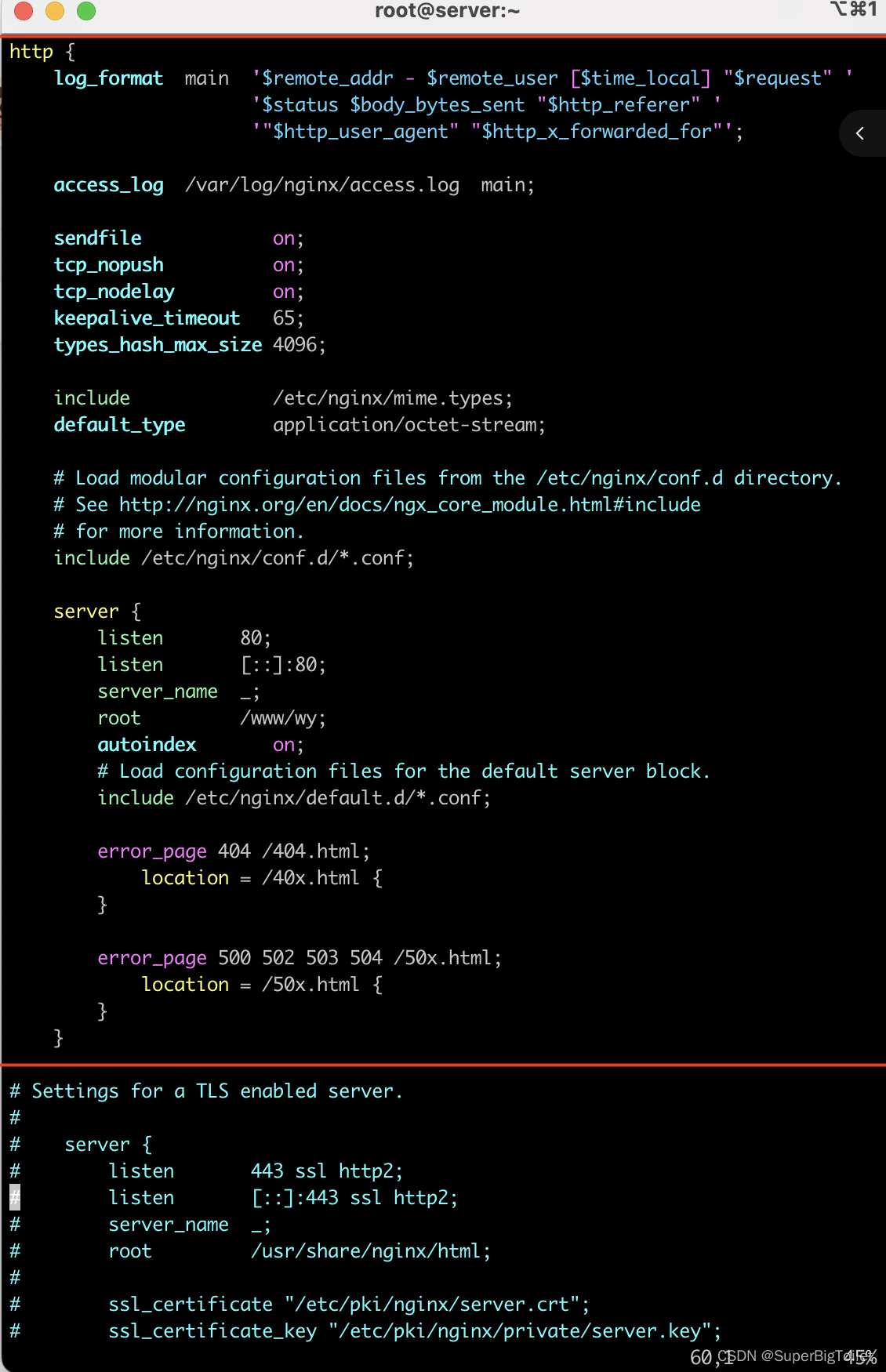
红线前的为之前所设置的http网站的内容,红线下的则是还未设置的https的内容,设置前需要知道非对称加密算法
Settings for a TLS enabled server.
#
# server {
# listen 443 ssl http2; #监听端口号
# listen [::]:443 ssl http2;
# server_name _; #域名
# root /usr/share/nginx/html; #网页的位置
#
# ssl_certificate "/etc/pki/nginx/server.crt"; #crt结尾就是证书的路径
# ssl_certificate_key "/etc/pki/nginx/private/server.key"; #key结尾就是私钥的路径
# ssl_session_cache shared:SSL:1m;
# ssl_session_timeout 10m;
# ssl_ciphers PROFILE=SYSTEM;
# ssl_prefer_server_ciphers on;
#
# # Load configuration files for the default server block.
# include /etc/nginx/default.d/*.conf;
#
# error_page 404 /404.html;
# location = /40x.html {
# }
#
# error_page 500 502 503 504 /50x.html;
# location = /50x.html {
# }
# }}首先在根目录下“/”创建一个目录及文件:mkdir -p /www/wy 然后往这个wy的文件里传输html文件
3、制作证书
将证书制作到etc目录下的nginx里
制作私钥使用命令:openssl genrsa -aes128 2048 > /etc/nginx/wy.key
openssl genrsa -aes128 2048 > /etc/nginx/wy.key
openssl——安装的模块里的指令
genrsa——rsa 算法
-aes128——加密位数
2048——设置
>——输出
/etc/nginx/wy.key——输出的位置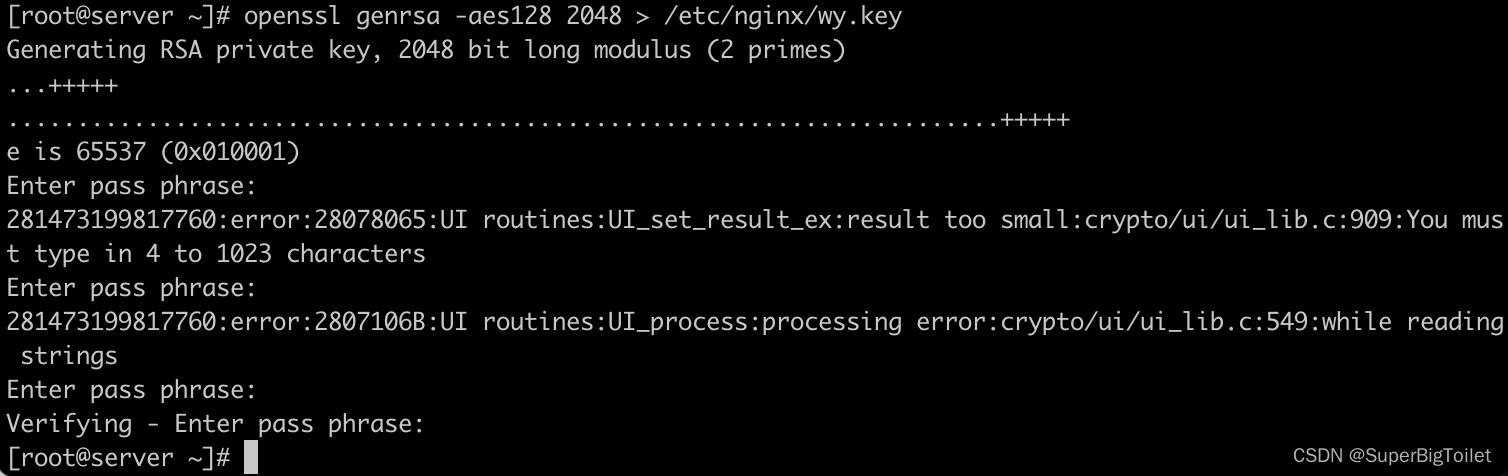
制作好后,需要对私钥加密,就需要输入密码,制作好的私钥就在/etc/nginx里,可以用cat来查看

制作证书使用的命令:
openssl req -utf8 -new -key /etc/nginx/wy.key -×509 -days 365 -out /etc/nginx/wy.crt
openssl req -utf8 -new -key /etc/nginx/wy.key -x509 -days 365 -out /etc/nginx/wy.crtopenssl——调用的命令
req——需要
-utf8——用到的字符集
-new——新的
-key /etc/nginx/wy.key——该证书所匹配的私钥位置
-x509——证书的协议
-days 365——证书的有效期
-out /etc/nginx/wy.crt——将证书输出的位置 扩展名为crt证书的信息还需要录入:
[root@server ~]# openssl req -utf8 -new -key /etc/nginx/wy.key -x509 -days 365 -out /etc/nginx/wy.crt
Enter pass phrase for /etc/nginx/wy.key: #对应的私钥的验证密码“为之前创建私钥时的密码”
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [AU]:86 #国家的编号,中国为86
State or Province Name (full name) [Some-State]:shan'xi #所在的省份
Locality Name (eg, city) []:xi'an #所在省份的城市
Organization Name (eg, company) [Internet Widgits Pty Ltd]:bewbew #公司名
Organizational Unit Name (eg, section) []:rhce #部门名字
Common Name (e.g. server FQDN or YOUR name) []:server #你的主机名
Email Address []:66666@qq.co #你的邮箱然后即可,现在私钥,证书都有了
但nginx有个特殊项:要将私钥的密钥给去掉
cd到etc里的nginx,复制一份密钥,

然后即可
4、进行设置
输入vim /etc/nginx/nginx.conf 找到server模块,将下面被注释掉的https给修改了
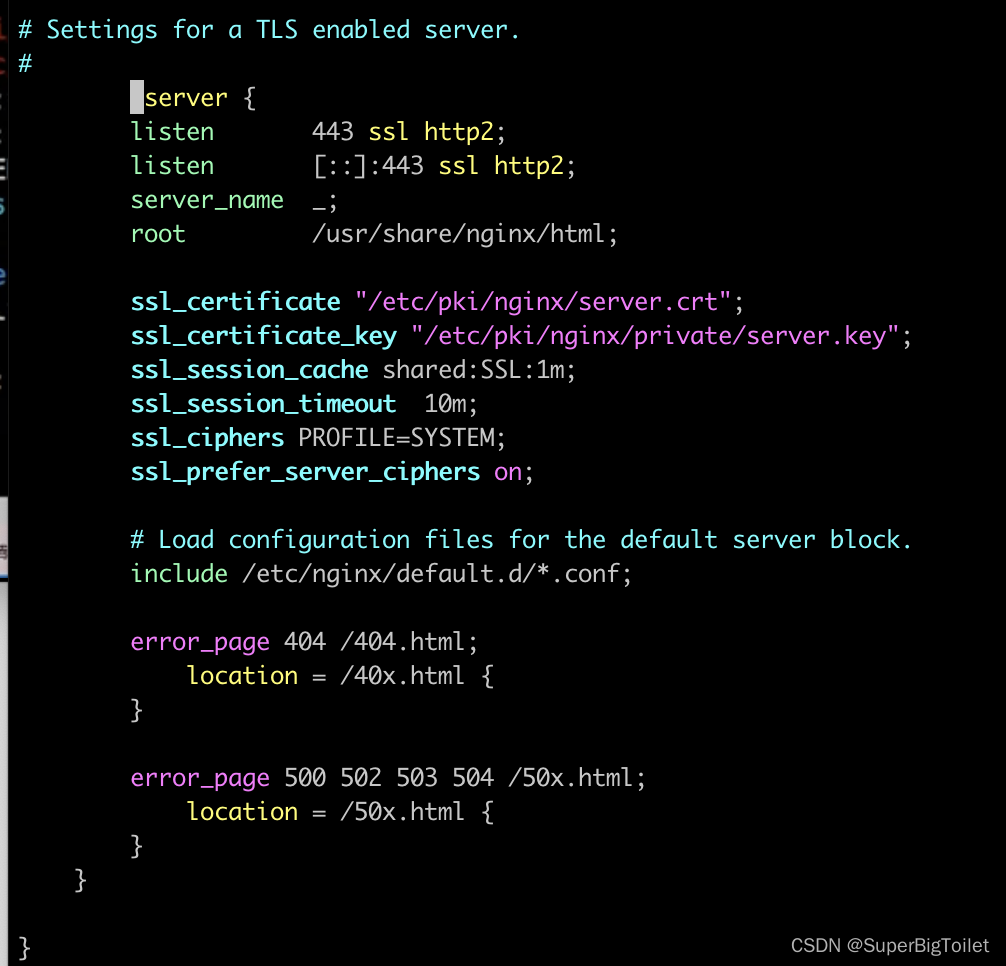
可以将ipv6那行删除掉
# Settings for a TLS enabled server.
#server {listen 443 ssl http2; #监听端口server_name 10.211.55.10; #设成ip,不设置也可以 root /www/wy; #网页所在的位置ssl_certificate "/etc/nginx/wy.crt"; #证书所在的位置ssl_certificate_key "/etc/nginx/wy.key"; #私钥所在的位置# Load configuration files for the default server block.include /etc/nginx/default.d/*.conf;error_page 404 /404.html;location = /40x.html {}error_page 500 502 503 504 /50x.html;location = /50x.html {}}}最重要的就是有注释的那几行,其他的不用进行修改,也可以将其删除,检查没问题后将其保存退出即可,退出后检查一下nginx是否有问题“nginx -t”没问题后重启nginx即可

最后在浏览器里输全网址https://xxxx
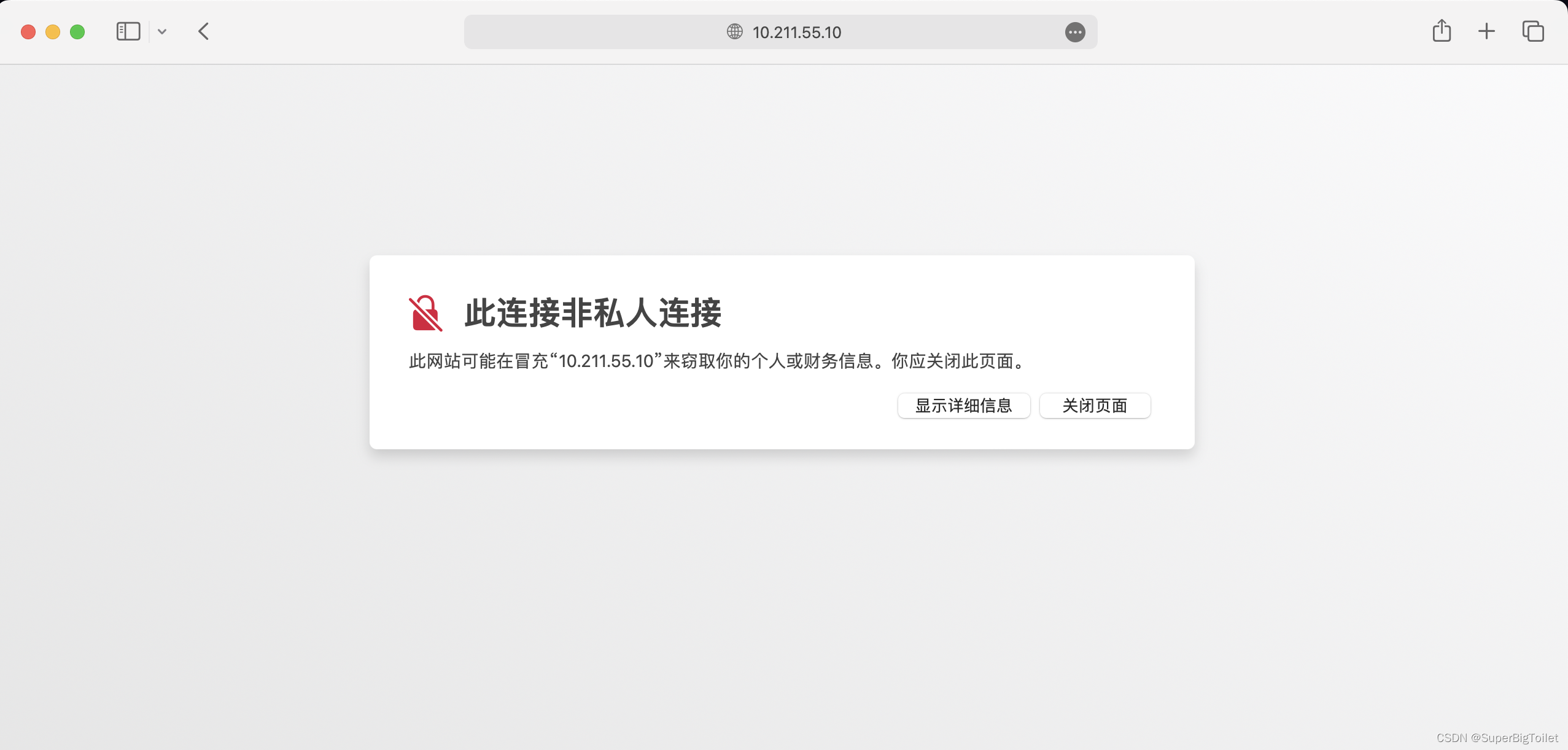
由于是我自己做的证书,不具备公信力,就会显示警告若要进入进行访问就可以点击“显示详细信息”或者“高级”里面

为了使访问更加方便,即将http自动转换成https,照样打开nginx的配置文件,将http进行配置
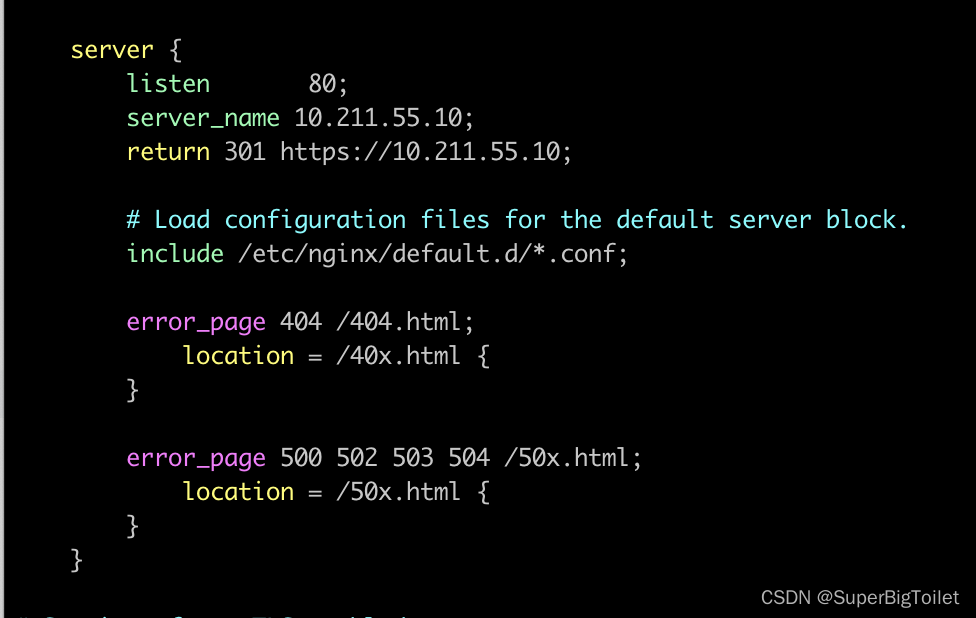
配置好ip地址后,删除文件所在位置,输入“return 301 https://10.211.55.10”意思是该网址已永久更换至https://10.211.55.10,最后进行重启nginx