购物网站功能模块设计中国美食网页设计
学习而来,代码是自己敲的。也有些自己的理解在里边,有问题希望大家指出。
个人理解:感觉像桥接模式 + 代理模式。不知道这么想对不对,还希望笔记在放出后,有大佬彻底了解了给我解解惑。
策略模式的定义与特点
策略(Strategy)模式的定义:该模式定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的变化不会影响使用算法的客户。策略模式属于对象行为模式,它通过对算法进行封装,把使用算法的责任和算法的实现分割开来,并委派给不同的对象对这些算法进行管理。
策略模式的主要优点如下。
- 多重条件语句不易维护,而使用策略模式可以避免使用多重条件语句,如 if...else 语句、switch...case 语句。
- 策略模式提供了一系列的可供重用的算法族,恰当使用继承可以把算法族的公共代码转移到父类里面,从而避免重复的代码。
- 策略模式可以提供相同行为的不同实现,客户可以根据不同时间或空间要求选择不同的。
- 策略模式提供了对开闭原则的完美支持,可以在不修改原代码的情况下,灵活增加新算法。
- 策略模式把算法的使用放到环境类中,而算法的实现移到具体策略类中,实现了二者的分离。
策略模式的主要缺点如下。
- 客户端必须理解所有策略算法的区别,以便适时选择恰当的算法类。
- 策略模式造成很多的策略类,增加维护难度。
策略模式的结构与实现
策略模式是准备一组算法,并将这组算法封装到一系列的策略类里面,作为一个抽象策略类的子类。策略模式的重心不是如何实现算法,而是如何组织这些算法,从而让程序结构更加灵活,具有更好的维护性和扩展性,现在我们来分析其基本结构和实现方法。
1. 模式的结构
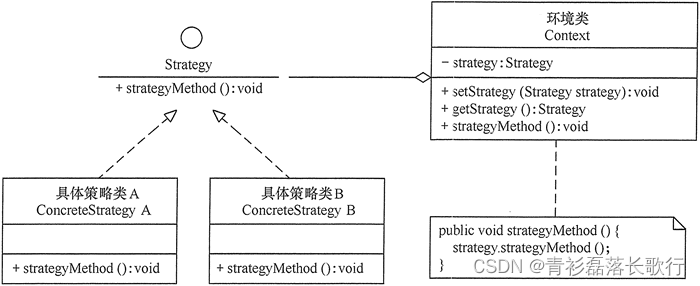
策略模式的主要角色如下。
- 抽象策略(Strategy)类:定义了一个公共接口,各种不同的算法以不同的方式实现这个接口,环境角色使用这个接口调用不同的算法,一般使用接口或抽象类实现。
- 具体策略(Concrete Strategy)类:实现了抽象策略定义的接口,提供具体的算法实现。
- 环境(Context)类:持有一个策略类的引用,最终给客户端调用。
其结构图如图 1 所示。
代码示例
using DesignPattern.StrategyPattern;
using System;namespace DesignPattern
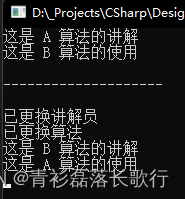
{internal class Program{static void Main(string[] args){StrategyHelper();}#region Pattern - Strategystatic void StrategyHelper(){AlgorithmExplain algorithmExplain = new AlgorithmExplain(new ExplainAlgorithmA(), new UseAlgorithmB());algorithmExplain.ExplainAlgorithm();algorithmExplain.UseAlgorithm();Console.WriteLine("\n--------------------\n");algorithmExplain.SetExplainer(new ExplainAlgorithmB());algorithmExplain.SetUser(new UseAlgorithmA());algorithmExplain.ExplainAlgorithm();algorithmExplain.UseAlgorithm();Console.ReadLine();}#endregion}
}//======================================================================================namespace DesignPattern.StrategyPattern
{public interface ExplainAlgorithm{ void Explain(); }public interface UseAlgorithm{ void Use(); }public class AlgorithmExplain{ExplainAlgorithm m_Explain;UseAlgorithm m_Use;public AlgorithmExplain(ExplainAlgorithm explain, UseAlgorithm use){m_Explain = explain;m_Use = use;}public void SetExplainer(ExplainAlgorithm explain){Console.WriteLine("已更换讲解员");m_Explain = explain; }public void SetUser(UseAlgorithm use){Console.WriteLine("已更换算法");m_Use = use; }public void ExplainAlgorithm(){//别的事情也可以写在这里m_Explain.Explain();}public void UseAlgorithm(){//别的事情也可以写在这里m_Use.Use();}}public class ExplainAlgorithmA : ExplainAlgorithm{public void Explain(){ Console.WriteLine("这是 A 算法的讲解"); }}public class UseAlgorithmA : UseAlgorithm{public void Use(){ Console.WriteLine("这是 A 算法的使用"); }}public class ExplainAlgorithmB : ExplainAlgorithm{public void Explain() { Console.WriteLine("这是 B 算法的讲解"); }}public class UseAlgorithmB : UseAlgorithm{public void Use() { Console.WriteLine("这是 B 算法的使用"); }}
}
希望大家:点赞,留言,关注咯~
😘😘😘😘
唠家常
今日分享结束啦,小伙伴们你们get到了么,你们有没有更好的办法呢,可以评论区留言分享,也可以加我QQ:841298494,大家一起进步。
- 客官,看完get之后记得点赞哟!
- 小伙伴你还想要别的知识?好的呀,分享给你们😄
今日推荐
- 博客杂货铺
- GoF23 种设计模式的分类和功能