上海闵行做网站网站宣传册怎么做
本站下载的 macOS 软件包,既可以拖拽到 Applications(应用程序)下直接安装,也可以制作启动 U 盘安装,或者在虚拟机中启动安装。另外也支持在 Windows 和 Linux 中创建可引导介质。
macOS Ventura 13.3.1 为 Mac 提供下列重要的错误修复和安全性更新(2023 年 4 月 7 日):
- 推手表情符号无法显示肤色选择
- 通过 Apple Watch 自动解锁 Mac 可能无法运行
请访问原文链接:https://sysin.org/blog/macOS-Ventura-boot-iso/,查看最新版。原创作品,转载请保留出处。
作者主页:sysin.org
台前调度等新功能帮助 Mac 用户保持专注、提高生产力
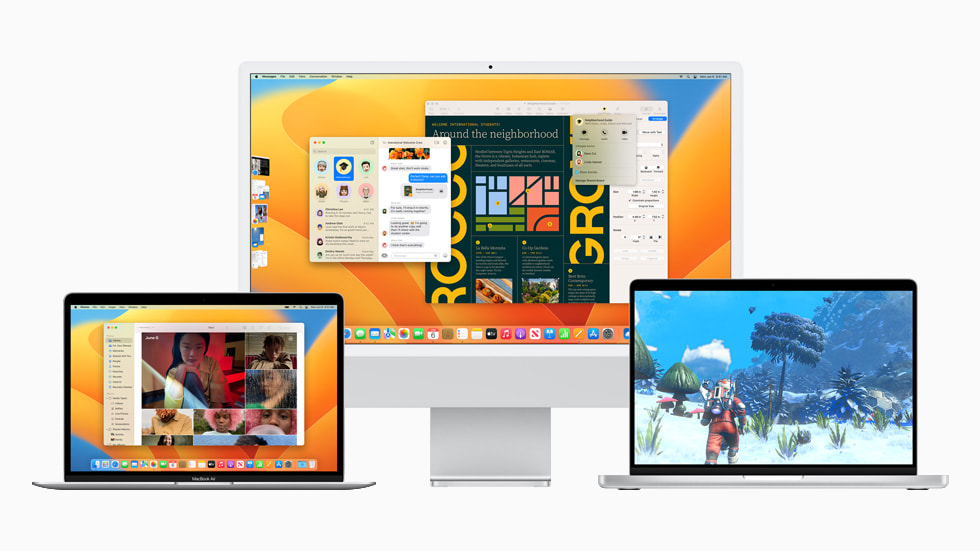
在 WWDC22 上面世的 macOS Ventura 让 Mac 体验更胜以往。
加利福尼亚州,库比提诺,Tim Cook 领导的 Apple 今日发布了 macOS Ventura,这是全球领先的桌面操作系统 macOS 的最新版本,将把 Mac 体验带入全新境界。台前调度为 Mac 用户提供一种全新方式,让用户在专注于眼前工作的同时,也能在各类 app 与窗口之间无缝切换。连续互通相机将 iPhone 用作为 Mac 的网络摄像头,可实现更多前所未有的操作 (sysin)。FaceTime 通话迎来接力功能,用户可在 iPhone 或 iPad 上开始 FaceTime 通话,然后无缝转移到 Mac 上。邮件 app 与信息 app 双双新增重大功能,用途更强大。Mac 上速度领先的 Safari 浏览器 (sysin)引入通行密钥,就此开启无密码时代。强大 Apple 芯片的广泛应用与 Metal 3 内置的新款开发者工具,让 Mac 的游戏体验更进一步。
“macOS Ventura 带来强大功能与锐意创新,让 Mac 体验更胜以往。台前调度等新工具让用户专注投入任务,并能更加简捷地在各类 app 与窗口之间切换;连续互通相机为所有 Mac 机型带来全新视频会议功能,包括桌面视图、摄影室灯光等等。”Apple 软件工程高级副总裁 Craig Federighi 表示,“凭借信息 app 的实用新功能,邮件 app 的先进搜索技术,以及聚焦搜索的最新设计,Ventura 潜力无穷,将可极大地丰富用户使用 Mac 的方式。”
应用场景
macOS Ventura 13 可启动 ISO 镜像,基于 Apple 原版 App 制作,可以用于虚机安装,可以拖拽到 Applications(应用程序)下直接双击安装,也可以制作启动 U 盘安装。
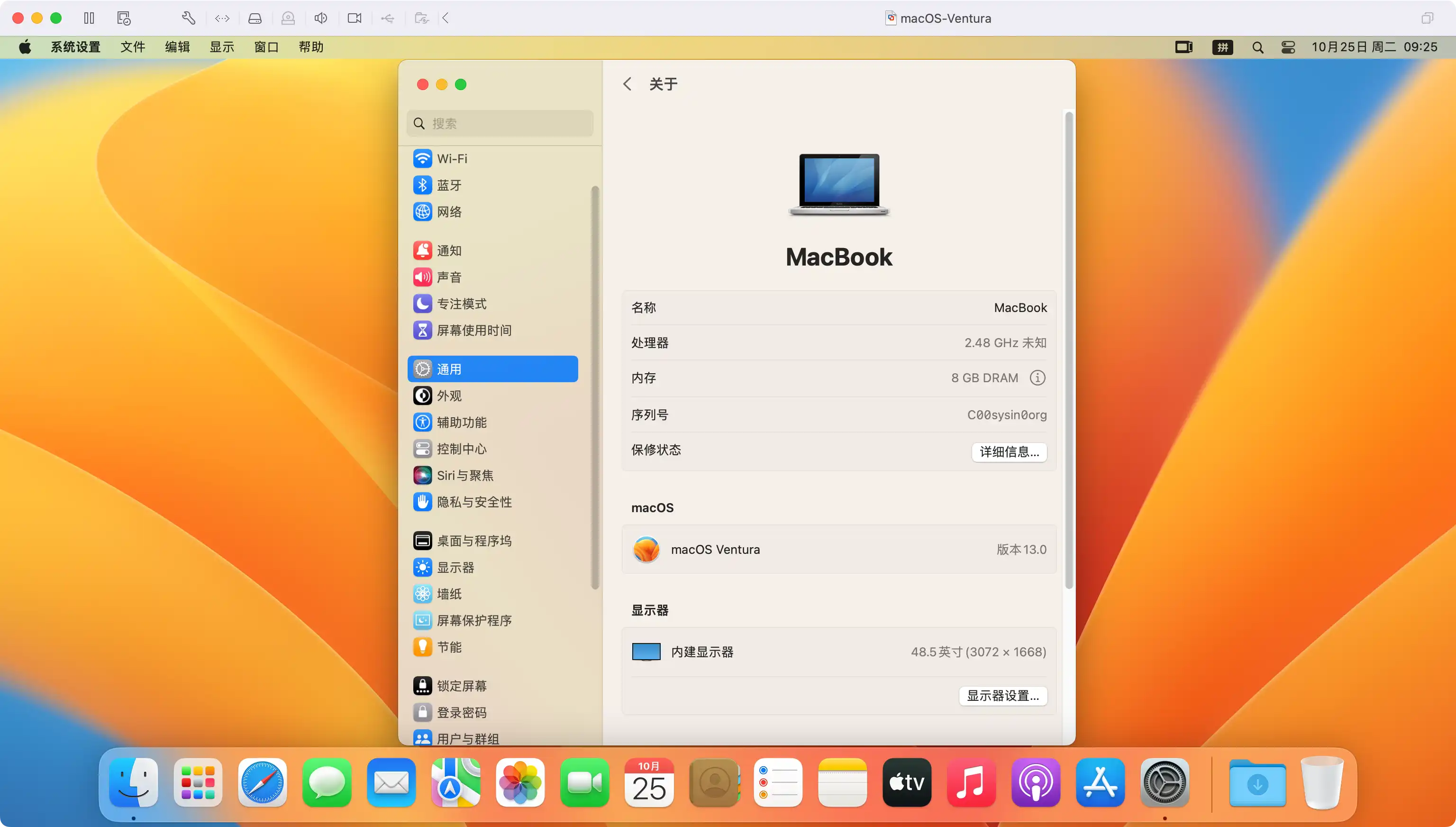
图:macOS Ventura 运行在 Fusion 12 中,并启用了 Metal GPU 加速。
适用的 VMware 软件下载链接
建议在以下版本的 VMware 软件中运行:
- Server:VMware ESXi 8.0 or with driver & vCenter Server 8.0,ESXi 7.0 or with driver & vCenter Server 7.0
- macOS:VMware Fusion 13
- Linux:VMware Workstation 17 for Linux
- Windows:VMware Workstation 17 for Windows
macOS Ventura 虚拟化解决方案,请参看:macOS 13 Blank OVF - 在 ESXi 8.0 中运行 macOS Ventura 的简单方式
ISO 镜像的优势
相对于官方发布 pkg 镜像(另有 ipsw 镜像,但仅适用于 Apple 芯片),以及第三方制作的 dmg 镜像,ISO 格式具有以下优势:
- 可以直接拖拽到 Applications(应用程序)目录下,进行升级安装,无需管理员权限
- 可以直接双击挂载,执行命令写入 USB 存储设备或者其他卷,然后启动全新安装(无需拖拽到“应用程序”目录下)
- 可以直接启动虚拟机安装,介质本身为可引导镜像
- 可以在 Windows 和 Linux 下写入 USB 存储设备,创建 USB 引导安装介质
下载 macOS Ventura
如何校验本站下载的文件的完整性

这里列出 ISO 启动镜像下载链接,更多格式请访问以下地址:
- macOS Ventura 13 正式版 ISO、IPSW、PKG 下载
可引导镜像,可以直接安装或者升级,也可以启动虚机安装。
百度网盘链接:https://sysin.org/blog/macOS-Ventura-boot-iso/
- macOS Ventura 13.3.1 (22E261)
- macOS Ventura 13.3 (22E252)
- macOS Ventura 13.2.1 (22D68)
- macOS Ventura 13.2 (22D49)
- macOS Ventura 13.1 (22C65)
- macOS Ventura 13.0.1 (22A400)
- macOS Ventura 13.0 (22A380)
参看:如何在 Mac 和虚拟机上安装 macOS Big Sur、Monterey 和 Ventura
如何创建可引导的 macOS 安装器
请访问:如何创建可引导的 macOS 安装介质
更多:macOS 下载汇总(系统、应用和文档)