网站建设买服务器还是数据库响应式布局网站实例
在本文中,您将学习基本的关键概念,这些概念将帮助您掌握身份验证和授权的工作原理。
您将首先了解什么是身份验证和授权,然后了解如何使用 Supabase auth 在应用程序中实现身份验证。
(本文内容参考:java567.com)
目录
- 先决条件
- 什么是认证和授权?
- 身份验证如何进行?
- 使用令牌、秘密和 Cookie 进行会话管理
- 认证因素的类型
- 常见的身份验证策略
- 基于密码的身份验证
- 无密码身份验证
- 双因素身份验证 (2FA)
- 多重身份验证 (MFA)
- OAuth 2.0 和社交身份验证
- 单点登录和 SAML
- 身份验证和安全
- Supabase 和 Supabase 身份验证服务
- 如何使用 Supabase 身份验证
- 应用程序编程接口
- 软件开发工具包
- 身份验证 UI 助手
- 概括
- 资源
先决条件
您需要满足以下条件才能充分利用本文:
- 基础编程知识。
- 后续的Supabase 项目。
- 以及一个文本编辑器来尝试示例代码片段。
什么是认证和授权?
简单来说,身份验证是用户向系统标识自己的过程,系统确认该用户就是他们所声称的身份。
另一方面,授权是系统确定允许用户查看或交互应用程序的哪些部分以及不允许用户访问应用程序的哪些部分的过程。
身份验证如何进行?
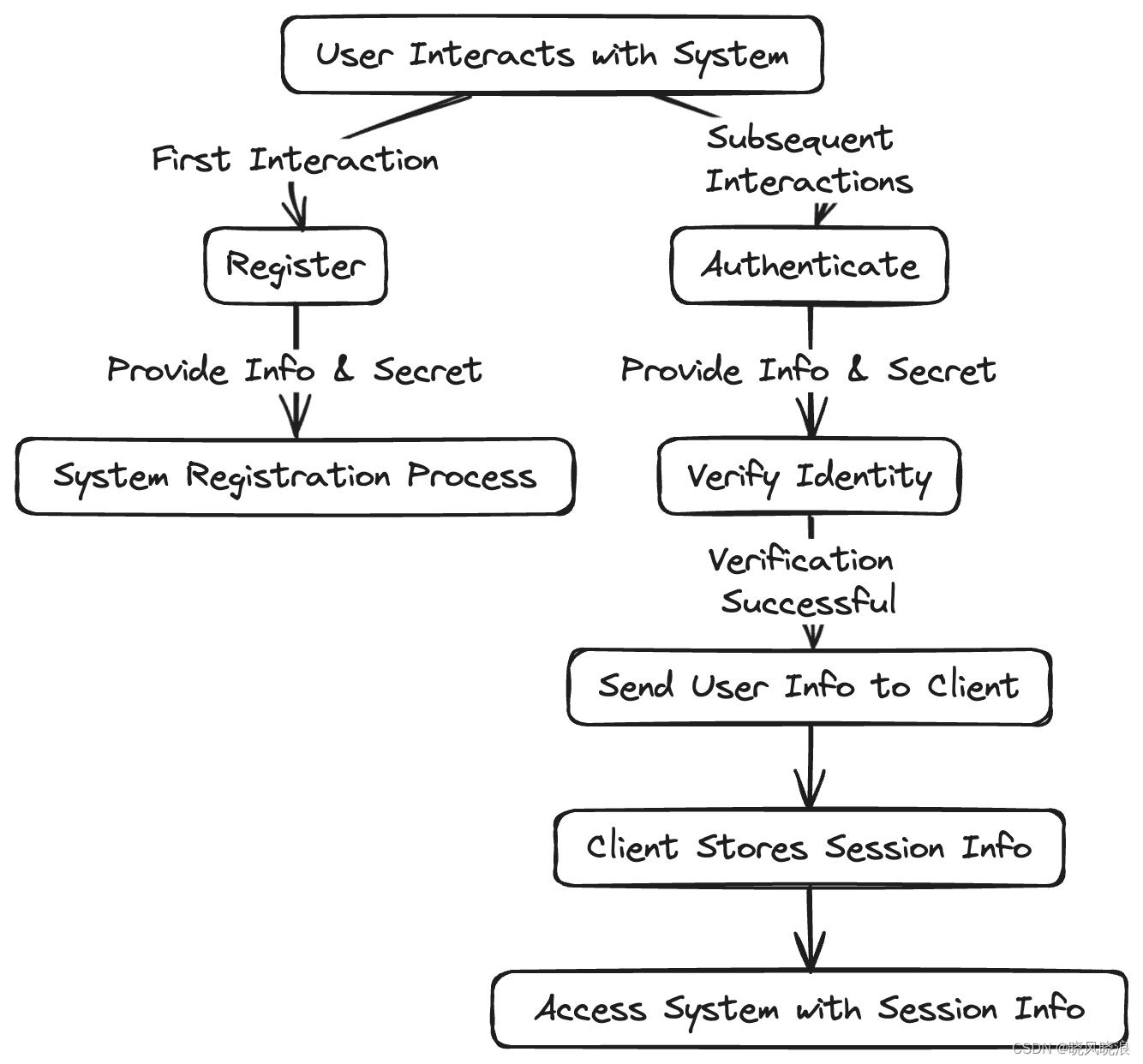
描述用户身份验证过程的流程图
用户第一次与系统交互时,系统会要求他们注册。通常,用户将提供一条信息和一个只有他们和系统知道的秘密。这是身份验证过程的注册部分。
下次用户与同一系统交互时,他们将需要提供识别信息以及先前定义的秘密,以验证其身份。
用户发起交互的设备是客户端,系统是服务器。一旦系统验证了用户,它就会向客户端发送有关该用户的一些信息。
由于此过程需要时间并且需要用户执行某些操作,因此客户端将存储此信息并在用户需要访问系统时将其发送回系统。这不需要用户每次都主动重新进行身份验证,从而减少了摩擦。这将创建一个用户会话。
使用令牌、秘密和 Cookie 进行会话管理
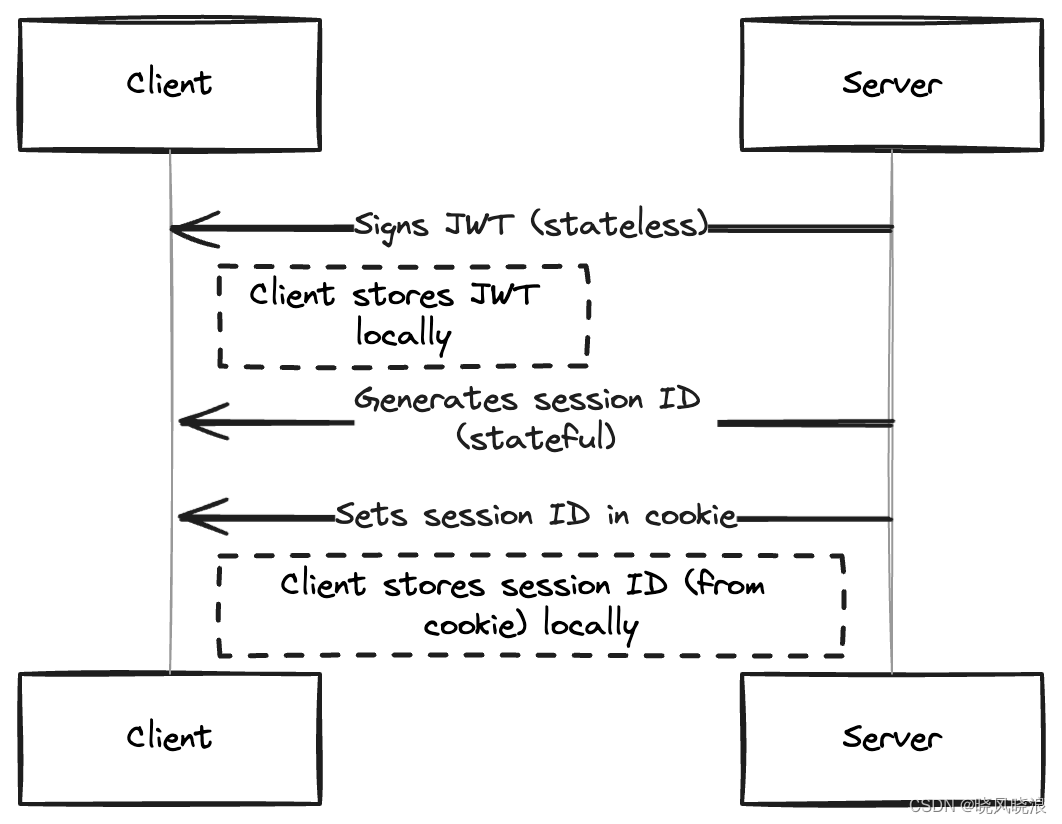
显示客户端-服务器架构中的会话管理的序列图
服务器可以通过两种方式将用户信息传递给客户端:通过令牌或会话 ID。
对于令牌,服务器生成签名令牌并将其传递给客户端。该令牌通常是 JWT,可能包含有关用户的信息。客户端将存储此令牌,并在每次用户发出请求时将其发送回服务器。
服务器能够验证令牌的完整性,因为它对其进行了签名。这称为无状态身份验证,因为令牌是自包含的,并且服务器不需要将会话数据存储在数据库或缓存中。
对于 cookie,服务器会在数据库或缓存中创建用户会话记录,其中包含会话 ID。服务器将此会话 ID 发送给客户端。
客户端将此会话 ID 存储在 cookie 中,并在用户发出请求时将其发送回服务器。会话 ID 是一个随机字符串,充当指向数据库中实际用户记录的指针。
当服务器收到此 cookie 时,会将其包含的会话 ID 与其会话记录进行匹配,然后将该记录与数据库中的用户数据进行匹配。这称为状态身份验证,因为需要数据库查找。
认证因素的类型
身份验证因素是指可用于验证用户身份的凭证类型。身份验证过程中通常使用 3 个因素,它们是:
- 您知道的事情:示例是密码。
- 您拥有的东西:例如发送到您手机的令牌。
- 你是谁:一个例子就是你的指纹。
常见的身份验证策略
身份验证策略是指用于验证用户的过程。不同类型的身份验证策略包括:
基于密码的身份验证
这是指用户通过提供用户定义的基于文本的秘密来识别自己的传统方式。通常,系统在其服务器上处理整个过程,并负责安全性和可靠性。
无密码身份验证
在这种方法中,系统验证用户的身份而不需要用户定义的密码。相反,系统将生成一次性密码 (OTP) 并发送给用户。然后使用该 OTP 代替密码来访问系统。示例包括魔术链接,系统将代码发送到用户的电子邮件。
双因素身份验证 (2FA)
在主要身份验证完成后,系统会通过要求额外的信息来尝试验证用户的身份。
这可以是通过电子邮件或短信发送给用户的 OTP,也可以是在系统授予访问权限之前要求用户提供生物识别信息。
多重身份验证 (MFA)
这与 2FA 类似,只不过系统将使用不止一种额外方法来验证用户的身份。MFA 和 2FA 中使用的额外方法或因素通常是系统外部的,例如需要电话的 SMS。
OAuth 2.0 和社交身份验证
OAuth 是一个授权框架,允许客户端代表用户从外部服务器访问信息。外部服务器提示用户是否允许与客户端共享所请求的资源。
用户允许该操作后,外部服务器向客户端发出访问令牌。
然后,客户端将此访问令牌提供给原始服务器,原始服务器验证令牌的有效性并管理对所请求资源的访问。OAuth 2.0 是 OAuth 的最新版本,也是使用更广泛的框架。
OAuth 2.0 扩展了对基于非浏览器的系统的支持。社交身份验证基于 OAuth 2.0,但在这种情况下,客户端将用户重定向到的外部服务器通常是社交媒体平台。这是每当您在身份验证页面上看到“继续使用 Twitter/X”按钮时执行的身份验证过程类型。
单点登录和 SAML
SAML 代表安全断言标记语言。它是在系统之间传递身份验证和授权信息的标准。一个系统充当请求系统或服务提供商 (SP),另一个系统保存所请求的信息或充当身份提供商 (IdP)。
收到此请求后,身份提供者将生成一些 SAML 形式的语句,其中包含一些用户信息。然后,服务提供商使用该信息来决定如何处理与其受保护资源相关的用户。
SSO 指单点登录。这是一种身份验证策略,允许用户通过一个系统/应用程序登录,然后让他们访问同一网络中的多个应用程序。
这不需要用户登录不同的相关应用程序,从而改善了用户体验。Google Workspace 就是一个例子。如果您已经登录 Gmail 帐户,则无需单独登录文档。SAML 促进了 SSO,因为 SAML 提供了标准身份验证机制并允许不同的系统相互信任。
身份验证和安全
身份验证涉及处理、移动和存储与受保护服务器资源相关的敏感用户信息。这使得安全性和最佳实践成为身份验证系统的一个重要方面。
您可以采取一些基本步骤来大大提高身份验证系统的安全性。这些包括:
- 强制使用更强的密码。
- 要求用户注册额外因素才能启用 2FA。
- 在通过 HTTPS 传输敏感数据时对其进行加密。
- 以加密方式存储密码。
- 使用 OAuth 2.0 等标准身份验证框架。
在处理特定身份验证信息之外的敏感用户数据时,您的系统应考虑某些合规性。如果在某些国家/地区运营或处理企业应用程序,情况更是如此。这些合规性包括:
- GDPR:此合规性强制执行有关数据处理的标准,包括机密性和完整性。
- HIPAA:此合规性适用于医疗数据。它期望高水平的诚信。
- SOC:这是云技术更普遍需要的框架。它以美国注册会计师协会为基础,涵盖隐私、安全、可用性、完整性和保密性等方面。
记住所有这些,您会发现为您的应用程序使用专用的身份验证服务通常比推出您自己的身份验证更容易。
为此有很多选择,包括专用身份验证服务(例如 Clerk 和 Auth0)以及后端即服务(例如 Supabase 和 Firebase)。在这种情况下,我们来看看 Supabase 身份验证产品。
Supabase 和 Supabase 身份验证服务
Supabase 是一个开源后端即服务 (BaaS) 平台,使您的应用程序后端开发变得非常简单、快速。它基于开源技术并积极支持开源生态系统。
Supabase 提供大多数后端应用程序所需的通用服务。这些服务是:
- 数据库:这是一个功能齐全的 Postgres 数据库。
- 身份验证:这是一项企业级身份验证服务,基于 goTrue 服务器的分支。
- 实时:这是一个 API,增加了在应用程序中使用实时功能的能力。
- 存储:这是一个存储服务,是 s3 包装器。
- 边缘功能:这些是在边缘运行的无服务器功能。由 Deno 运行时提供支持。
- Vector:这是一个矢量数据库,可以更轻松地在 AI 应用程序中使用嵌入。
Supabase 符合 SOC2、HIPAA 和 GDPR 标准、可自托管且开源。此外,他们的身份验证服务公开了许多策略,使您可以完全控制自己的数据,并且可以独立于其他产品使用。这个及其自动记录 API 使其成为您的应用程序的一个非常好的选择。
如何使用 Supabase 身份验证
第一步是设置Supabase 项目的身份验证设置。您可以通过设置启用您想要使用的确切身份验证方法。您可以通过三种方式开始在项目中使用 Supabase auth:
应用程序编程接口
您可以通过调用 auth 端点并将用户信息传递给它来直接在应用程序中使用身份验证服务。您还可以获取、更新和删除您的用户。
当您通过 Supabase 控制台创建项目时,该 API 会自动可用,并且可以像这样调用:
//This will return an object containing an access token, the newly created user data and other metadata
const res = await fetch("https://<your-project-ref>/auth/v1/signup", {method: "POST",headers: {authorization: "Bearer YOUR_SUPABASE_KEY","content-type": "application/json",},body: JSON.stringify({email: "user-email",password: "user-password",}),
});
软件开发工具包
Supabase 提供了一些采用不同编程语言的 SDK(软件开发套件),旨在使与 Supabase 项目的交互变得简单。官方支持的语言包括 Dart 和 JavaScript,Python 和其他语言拥有强大的社区支持。
入门过程包括添加 SDK 作为依赖项,然后将您的应用程序连接到 Supabase 项目。
对于 JavaScript SDK,这看起来像这样:
//Install via npm:
npm install @supabase/supabase-js// or add cdn links:
<script src="https://cdn.jsdelivr.net/npm/@supabase/supabase-js@2"></script>
//Then initialize
Supabaseimport { createClient } from '@supabase/supabase-js'const supabaseUrl = 'https://<your-project-ref>.supabase.co'
const supabaseKey = process.env.SUPABASE_ANON_KEY
const supabase = createClient(supabaseUrl, supabaseKey)
然后您可以访问 auth 命名空间下的身份验证方法,如下所示:
const { data, error } = await supabase.auth.signUp({email: 'user email',password: 'user password',
})
身份验证 UI 助手
Supabase 提供帮助程序库,使使用其服务进行身份验证变得更加容易。这些库提供可定制的登录屏幕,支持魔术链接、基于密码和社交登录策略。
目前,这些库可用于 JavaScript 和 Flutter。Supabase 还为使用服务器端框架并需要 Supabase 访问令牌的应用程序提供单独的 SSR(服务器端渲染)包。
作为示例,要开始使用 React Auth UI,首先需要安装依赖项,如下所示:
npm install @supabase/supabase-js @supabase/auth-ui-react
@supabase/auth-ui-shared
然后,您可以在初始化 Supabase 后开始使用该库,如上面的 SDK 示例所示。以下是一些示例代码,展示了如何在 React 应用程序中使用 auth UI 库:
import { useEffect } from "react";
import { useNavigate } from "react-router-dom";
import { Auth } from "@supabase/auth-ui-react";
import { ThemeSupa } from "@supabase/auth-ui-shared";
import { supa } from "../constants";const AuthUi = () => {const navigate = useNavigate();useEffect(() => {const {data: { subscription },} = supa.auth.onAuthStateChange((event) => {if (event === "SIGNED_IN") {navigate("/authenticated");}});return () => subscription.unsubscribe();}, [navigate]);return (<AuthsupabaseClient={supa}providers={["google", "github", "apple", "discord"]}// controls whether to display only social providers// onlyThirdPartyProvidersredirectTo="http://localhost:3000/authenticated"// comes with preconfigured themes, can add custom themesappearance={{ theme: ThemeSupa }}// controls how to display the social provider iconssocialLayout="horizontal"/>);
};export default AuthUi;
这将在屏幕上显示以下表单:
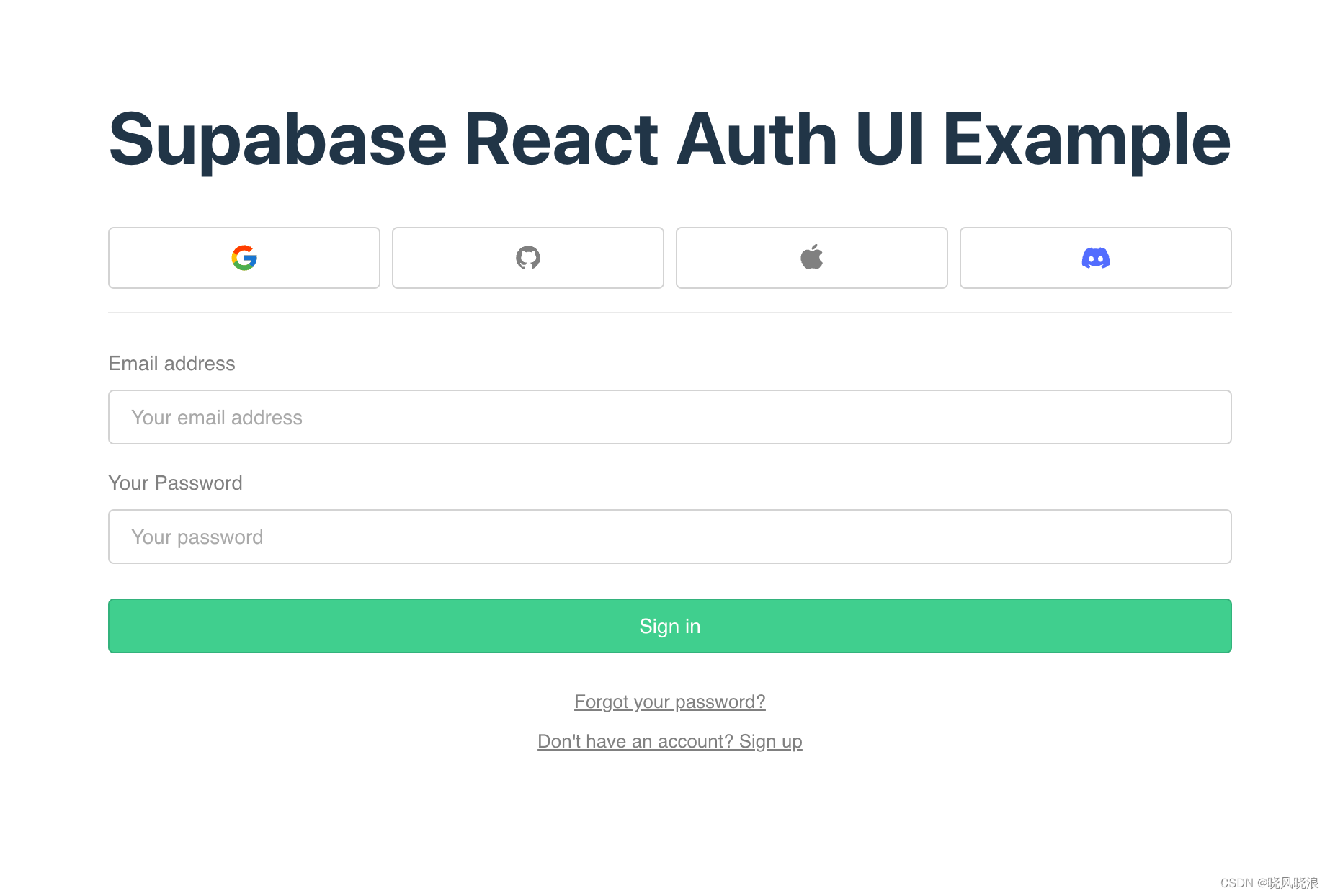
概括
身份验证是用户识别自己的过程,服务器验证此身份,而授权是系统确定用户对资源应具有的访问权限并相应地限制用户。
服务器对用户进行身份验证后,将以 cookie 中的令牌或会话 ID 的形式传递用户信息。
每当用户需要某些访问权限时,信息就会在客户端和服务器之间来回传递,直到它们过期或用户通过注销或删除其帐户来终止周期。
用户验证过程是通过采用某些身份验证因素来实现的。例如,一个系统可能只需要密码,而另一个系统则需要密码和发送到用户电话号码的代码。
您的身份验证系统可以允许使用三个身份验证因素中的任何一个进行多种身份验证策略。
如果您选择不处理自己的身份验证,Supabase 是一个很好的选择。
Supabase auth 可以通过 API、SDK 和 Auth 库进行访问。Supabase 维护服务器端框架的 SSR 包。
(本文内容参考:java567.com)