vs网站制作教程正能量视频素材免费下载网站
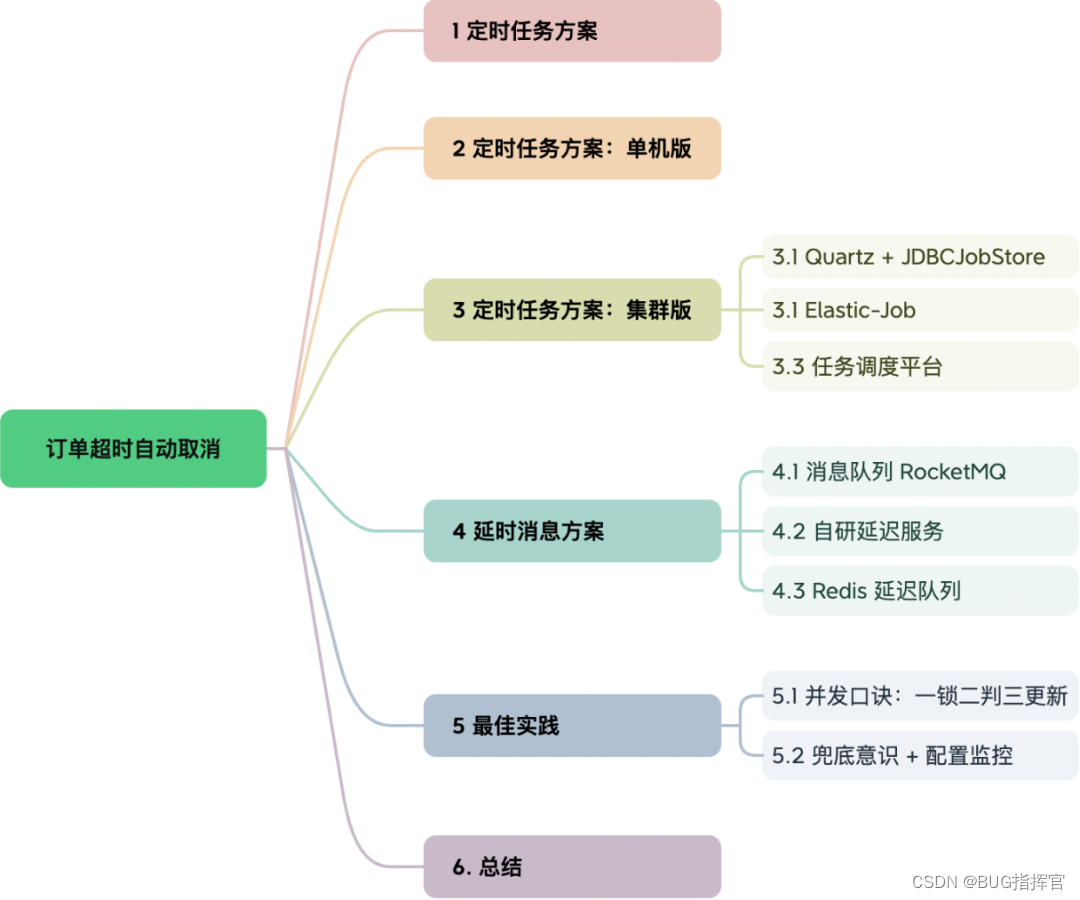
1、定时任务方案
方案流程:
-
每隔 30 秒查询数据库,取出最近的 N 条未支付的订单。
-
遍历查询出来的订单列表,判断当前时间减去订单的创建时间是否超过了支付超时时间,如果超时则对该订单执行取消操作。
定时任务方案工程实现相对简单,但这种方案会间隔对数据库造成一定的 IO 压力。特别是当订单量数据量非常高时,高频次的查询对数据库的性能是个不小的考验。
定时任务方案从功能模块角度来讲,包含调度层和业务逻辑层两部分。
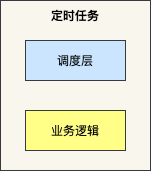
网上有很多的定时任务实现策略,我们可以简单划分为单机版和集群版。
2、定时任务方案:单机版
我们可以使用 Timer 、ScheduledEexcutorService、Quartz 非常容易的实现定时任务。
但笔者并不推荐使用单机版的方案,举个简单的例子:
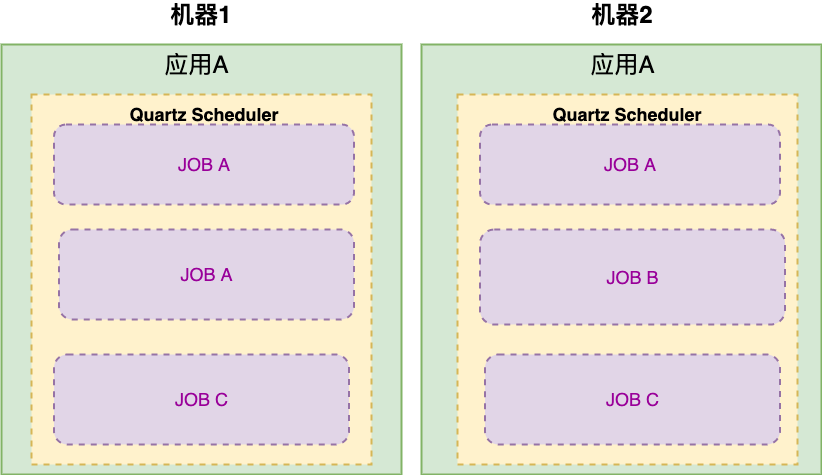
假设我们应用 A 通过 Quartz 调度三个定时任务 A、B、C ,当集群部署时,可能出现多台不同机器实例同时执行任务的风险。
此时,我们可以通过加锁的方式适当规避,见下图:
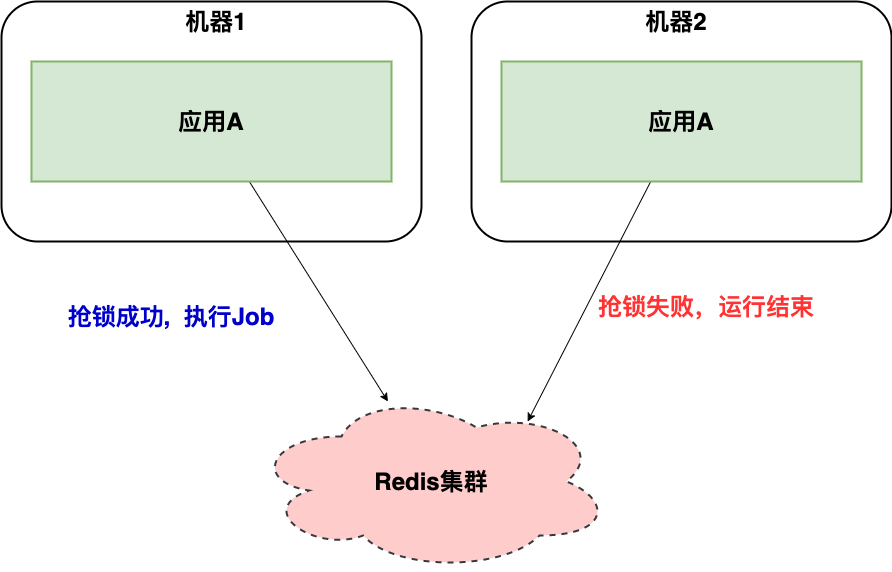
但这种方式并不优雅,同时定时任务应用内调度层会经常空跑,我们预期是希望三个定时任务 A、B、C 能均匀分布应用 A的不同实例内。
好,接下来,笔者会介绍亲身经历的三种集群定时任务。
3、定时任务方案:集群版
3.1 Quartz + JDBCJobStore
Quartz 可以支持集群模式,集群模式需要在数据库中添加11张表,对业务系统有一定的侵入性。
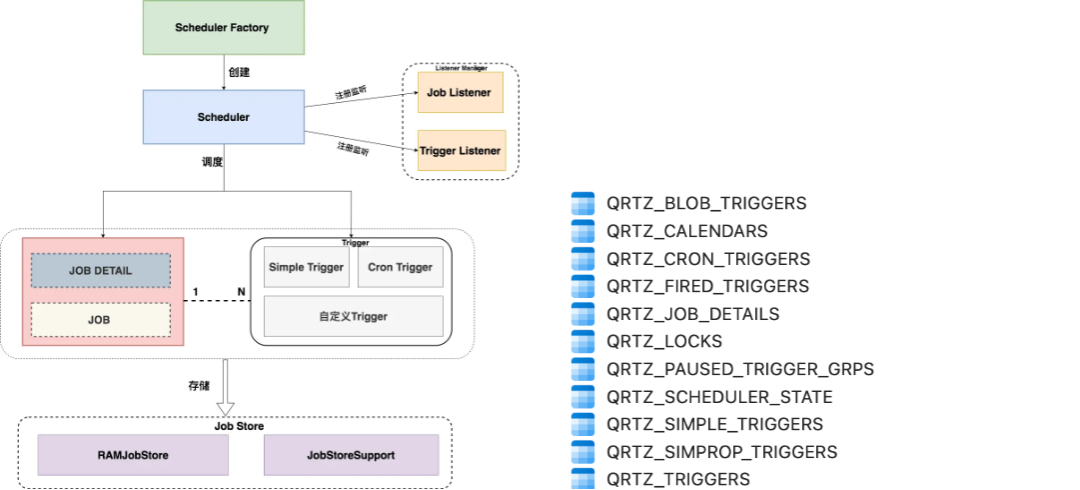
笔者曾经服务的一家彩票公司,订单调度中心就是使用 Quartz 的集群模式,实现日均百万订单的调度处理。
需要特别注意的是:
基于底层数据库悲观锁的机制,Quartz 的集群模式性能并不高,假如执行频率高的任务数超过达到一定数量,存在性能问题。
3.1 Elastic-Job
ElasticJob 定位为轻量级无中心化解决方案,使用 jar 的形式提供分布式任务的协调服务。
ElasticJob 从本质上来讲 ,底层任务调度还是通过 Quartz ,它的优势在于可以依赖 Zookeeper 这个大杀器 ,将任务通过负载均衡算法分配给应用内的 Quartz Scheduler 容器,
举例:应用A有五个任务需要执行,分别是 A,B,C,D,E。任务E需要分成四个子任务,应用部署在两台机器上。
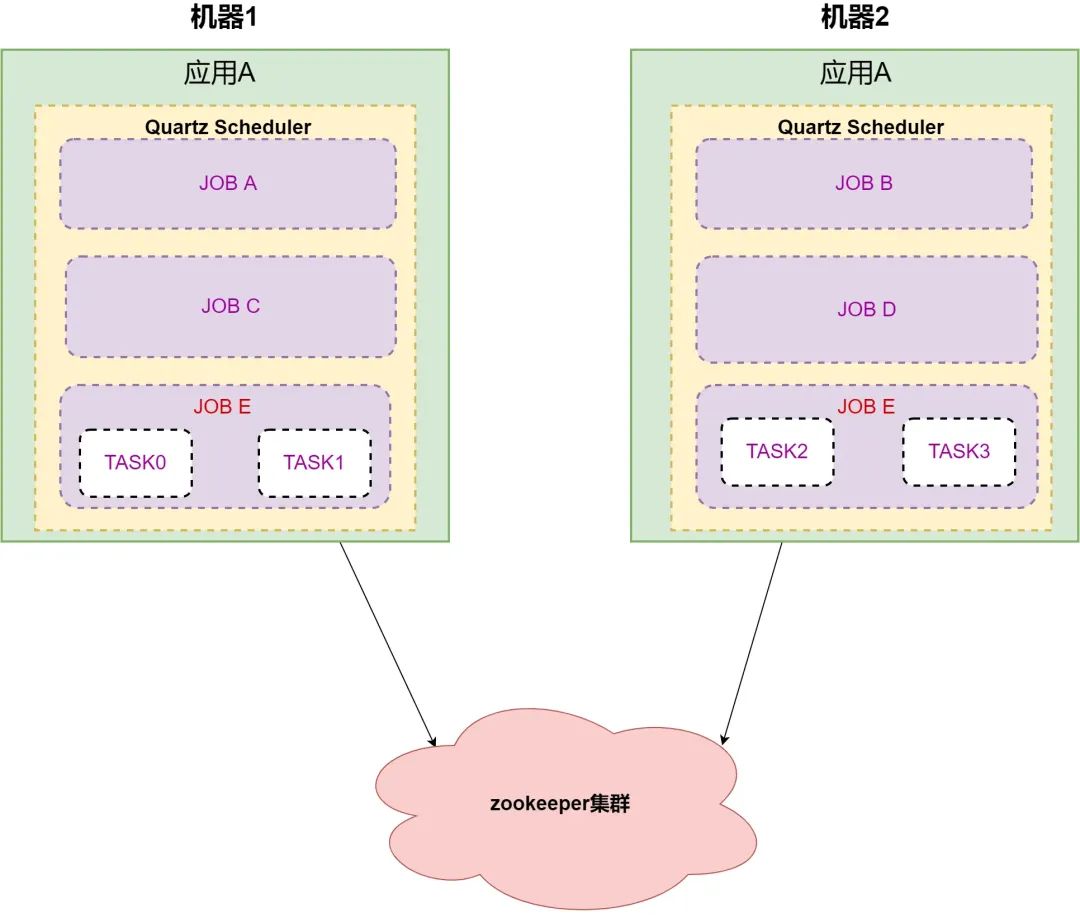
图中,应用 A 在启动后, 5个任务通过 Zookeeper 协调后被分配到两台机器上,通过 Quartz Scheduler 分开执行不同的任务。
相比 Quartz 集群模式,ElasticJob 的可扩展性更高,同时因为是本地内存存储 JOB,性能非常好。
但是 ElasticJob 的控制台非常粗糙,主要原因还是基于它的实现机制 (Quartz + zookeeper)。
通过控制 zookeeper 节点来间接操作应用内任务执行情况,但这样非常不灵活,所以笔者认为 ElasticJob 更多的还是定位于框架,而不是一个调度平台。
3.3 任务调度平台
笔者非常认可任务调度平台这种模式。XXL-JOB 是一个使用最广泛的分布式任务调度平台。
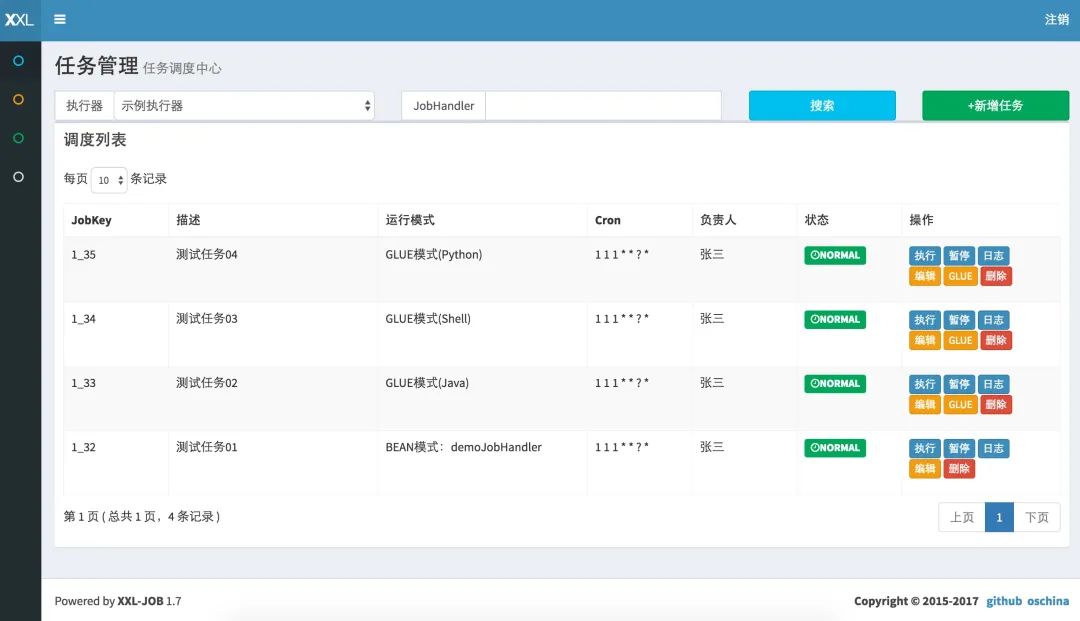
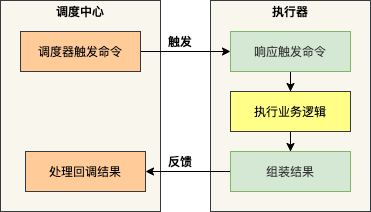
业务系统和调度平台分开部署,我们在调度中心上配置应用以及其定时任务,当任务需要执行时,调度平台会触发业务系统的任务,业务系统执行完任务之后,反馈给调度平台任务执行的结果。
业务系统和调度平台都可以水平扩展实现高可用,同时在调度平台可以配置灵活的调度策略(比如重试机制、广播模式等)。
XXL-JOB 并不完美,因为底层依然是基于数据库悲观锁的机制,虽然通过时间轮的方式做了一定程度的优化,但依然会有性能瓶颈。
很多公司比如神州专车、美团都有自己自研的任务调度平台。这种模式非常适合多团队协作,便于大规模调度任务的统一管理。
4、延时消息方案
延时消息是一种非常优雅的模式。订单服务生成订单后,发送一条延时消息到消息队列。消息队列在消息到达支付过期时间时,将消息投递给消费者,消费者收到消息之后,判断订单状态是否为已支付,假如未支付,则执行取消订单的逻辑。

4.1 消息队列 RocketMQ
RocketMQ 4.X 生产者发送延迟消息代码如下:
Message msg = new Message();
msg.setTopic("TopicA");
msg.setTags("Tag");
msg.setBody("this is a delay message".getBytes());
//设置延迟level为5,对应延迟1分钟
msg.setDelayTimeLevel(5);
producer.send(msg);
RocketMQ 4.X 版本默认支持 18 个 level 的延迟消息, 通过 broker 端的 messageDelayLevel 配置项确定的。

RocketMQ 5.X 版本支持任意时刻延迟消息,客户端在构造消息时提供了 3 个 API 来指定延迟时间或定时时间。
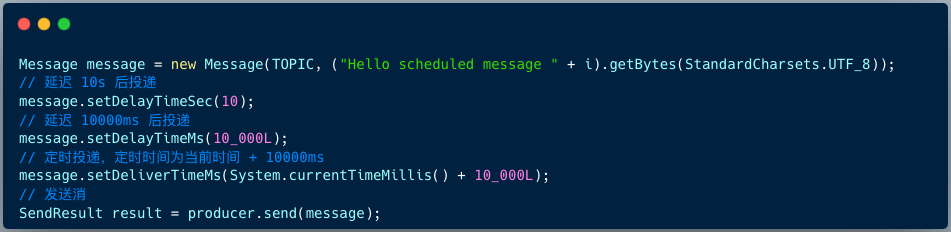
假如技术团队基础架构能力很强,笔者非常推荐使用 RocketMQ 5.X 的延迟消息功能。
4.2 自研延迟服务
基于 RocketMQ 4 内置的延迟消息只能支持几个固定的延迟级别,快手、滴滴开发了单独的 Delay Server 来调度延迟消息。
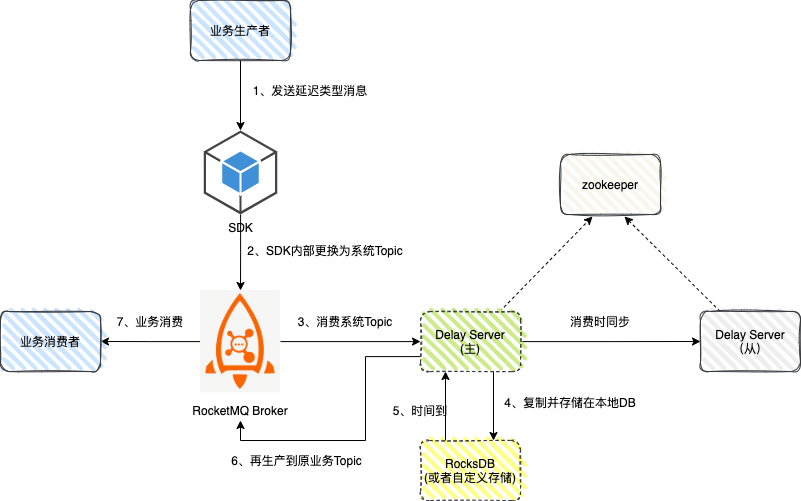
上图这个结构没有直接将延迟消息发到 Delay Server,而是更换 Topic 以后存入 RocketMQ。这样的好处是可以复用现有的消息发送接口(以及上面的所有扩展能力)。对业务来说,只需要在构造消息的时候额外指定一个延迟时间字段即可,其它用法都不变。
自研单独的 Delay Server 不仅可以适配 RocketMQ 4.X , 也可以适配 Kafka ,同时,也可以具有非常高的性能,说实话,这个是一个非常实用且灵活的方案。
4.3 Redis 延迟队列
Redis 延迟队列是一个轻量级的解决方案,开源成熟的实现是 Redission 。
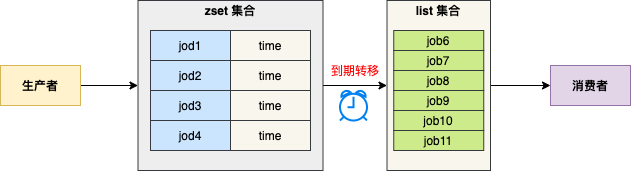
图中,我们定义两个集合:
1、zset 集合
生产者将任务信息发送到 zset 集合,value 是任务编号,score 是任务执行时间戳。
2、list 集合
守护线程检测 zset 集合中到期的任务,若任务到期,将任务编号转移到 list 集合 , 消费者从 list 集合弹出任务,并执行任务逻辑。
笔者需要强调的是:
Redis 虽然可以实现延迟消息的功能,但 Redis 并不是真正意义上的消息队列,在使用过程中还是有小概率会丢失消息。
5、最佳实践
5.1 并发口诀:一锁二判三更新
不管我们使用定时任务还是延迟消息时,不可避免的会遇到并发执行任务的情况 (比如重复消费、调度重试等)。
当我们执行任务时,我们可以按照一锁二判三更新这个口诀来处理。
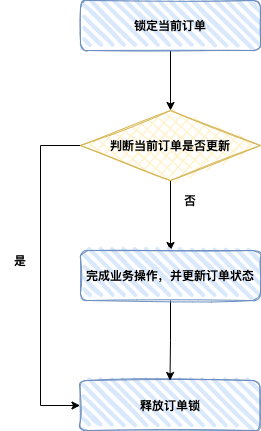
-
锁定当前需要处理的订单。
-
判断订单是否已经更新过对应状态了
-
如果订单之前没有更新过状态了,可以更新并完成相关业务逻辑,否则本次不能更新,也不能完成业务逻辑。
-
释放当前订单的锁。

伪代码
5.2 兜底意识 + 配置监控
虽然我们提到了很多的实现策略,现实实战时依然容易出现问题,比如不合理的操作导致消息丢失。
因此,我们应该具备兜底意识。
假如少量消息丢失,我们可以通过每天凌晨跑一次任务,批量将这些未处理的订单批量取消。这种兜底行为工程实现简单,同时对系统影响很小。
还有一点,就是配置监控。
笔者曾经自研过任务调度系统,应用 A 接入后,从控制台发现每隔 2 个小时调度应用 A 的任务时,经常发生超时,通过分析,发现应用 A 线程出现了死锁。
这种问题出现的几率非常高,因此配置监控特别要必要。
对业务系统来讲,监控分为两个层面:系统监控和业务监控。
-
系统监控
在条件允许的情况下,建议关注性能监控,方法可用性监控,方法调用次数监控这三大类。
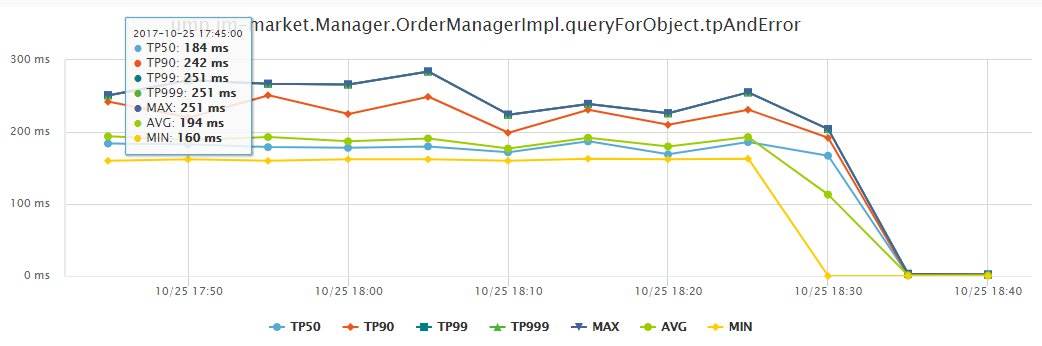
性能监控
上图是性能监控的示例图,性能监控不同时间段性能分布,实时统计 TP99、TP999 、AVG 、MAX 等维度指标,这也是性能调优的重点关注对象。
-
业务监控
业务监控功能是从业务角度出发,各个应用系统需要从业务层面进行哪些监控,以及提供怎样的业务层面的监控功能支持业务相关的应用系统。
具体就是对业务数据,业务功能进行监控,实时收集业务流程的数据,并根据设置的策略对业务流程中不符合预期的部分进行预警和报警,并对收集到业务监控数据进行集中统一的存储和各种方式进行展示。
比如订单系统中有一个定时结算的服务,每两分钟执行一次。我们可以在定时任务 JOB 中添加埋点,并配置业务监控,假如十分钟该定时任务没有执行,则发送邮件,短信给相关负责人。
6、总结
这篇文章,笔者总结了订单超时自动取消方案的两种流派:定时任务和延迟消息。
1、定时任务
定时任务实现策略,我们可以简单划分为单机版和集群版。
笔者并不认可单机版,背八股文当然可以,订单自动取消这个业务场景,生产环境还是要慎重。
集群版有三种方式:Quartz + JDBCJobStore、ElasticJob 、XXL-JOB 。
每种方式各有优缺点,笔者更倾向于任务调度平台 XXL-JOB 这种方式。
2、延迟消息
延时消息是一种非常优雅的模式。本文介绍了三种方式:消息队列 RocketMQ、自研延迟服务、Redis 延迟队列。
假如技术团队基础架构能力很强,笔者推荐使用 RocketMQ 或者自研延迟服务。
假如技术团队仅仅想用轻量级的实现,可以选择 Redis 延迟队列。
不管是使用定时任务还是延迟消息,架构的稳定性还需要注意如下两点:
1、并发口诀:一锁二判三更新 ;
2、兜底意识 + 配置监控。