个人空间备案网站名称wordpress首页文章图片
- Nginx可以作为静态web服务器来部署静态资源,这个静态资源是指在服务端真实存在,并且能够直接展示的一些文件数据,比如常见的静态资源有html页面、css文件、js文件、图片、视频、音频等资源
- 相对于Tomcat服务器来说,Nginx处理静态资源的能力更加高效,所以在生产环境下,我们一般都会将静态资源部署到Nginx下,以提供给用户进行访问
- 简单的部署静态资源,我们可以直接使用nginx默认的存放静态html的目录,将静态资源直接拷贝到当前目录中即可
-
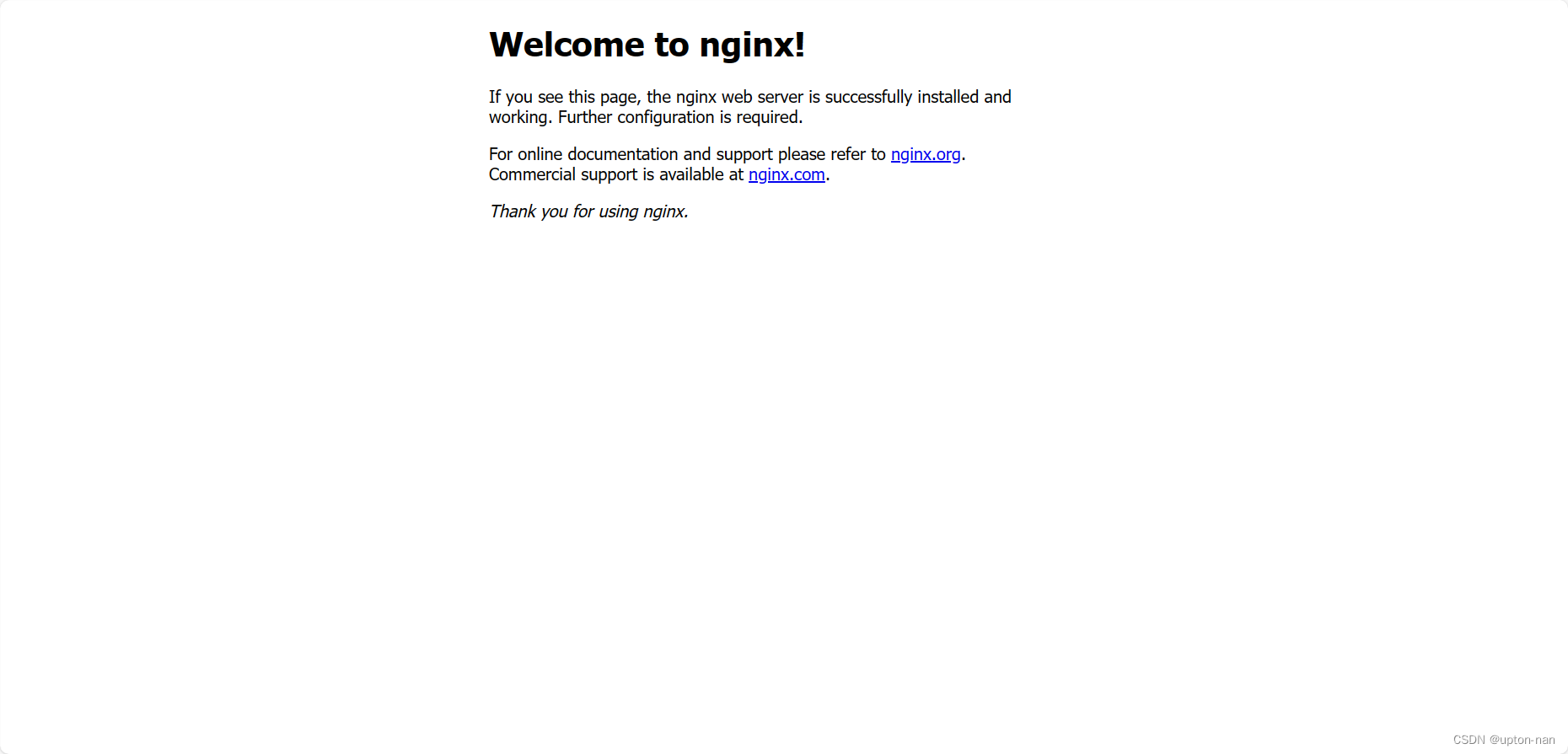
server {# 服务器监听的端口listen 80;# 服务器的名称server_name localhost;#charset koi8-r;#access_log logs/host.access.log main;# 匹配客户端请求的urllocation / {# 指定静态资源的根目录,root后可设置相对路径,也可以设置绝对路径,根据需求设定root html;# 指定静态资源的默认首页index index.html index.htm;}} - 因为当前工作目录下的html目录下存在index.html文件,则我们使用浏览器访问,默认不加端口则是默认使用80端口访问:http://服务器ip地址/
-