自己做的网站怎么发布上成都旅游网站建设
第1章 数据仓库概念
数据仓库(Data Warehouse),是为企业制定决策,提供数据支持的。可以帮助企业改进业务流程、提高产品质量等。
数据仓库的输入数据通常包括:业务数据、用户行为数据和爬虫数据等
业务数据:就是各行业在处理事务过程中产生的数据。比如用户在电商网站中登录、下单、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据就是业务数据。
业务数据通常存储在 MySQL、Oracle 等数据库中。

用户行为数据:用户在使用产品过程中,通过埋点收集与客户端产品交互过程中产生的数据,并发往日志服务器进行保存。比如页面浏览、点击、停留、评论、点赞、收藏等。用户行为数据通常存储在日志文件中。

爬虫数据:通常事通过技术手段获取其他公司网站的数据。不建议同学们这样去做。
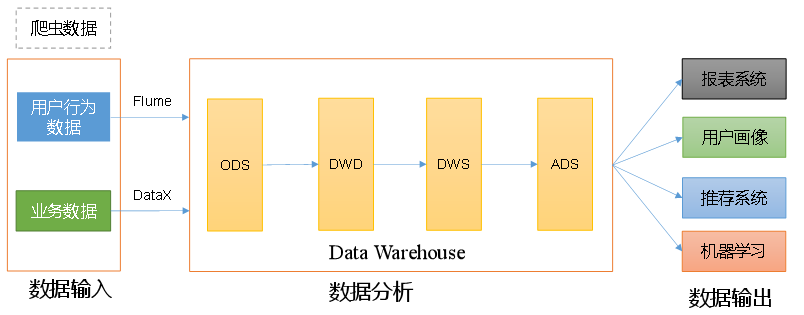
数据仓库,并不是数据的最终目的地,而是数据最终的目的地做好准备。这些准备包括对数据的:备份、清洗、聚合、统计等