网站调用视频公司门户网站制作需要多少钱
目录
1.树形结构
1.1 树的概念
1.2 树的相关概念
1.3 树的表示
1.4 树在实际中的应用—表示文件系统的目录树结构
编辑2.二叉树
2.1 概念
2.2 特殊二叉树
2.3 二叉树的性质
2.4 二叉树的存储结构
2.4.1 顺序存储结构(数组存储结构)
2.4.2 链式存储结构
2.5 二叉树的基本操作
2.5.1 二叉树的深度优先遍历
2.5.2 二叉树的广度优先遍历
2.5.3 二叉树的结点统计
2.5.4 二叉树的叶子结点统计
2.5.5 二叉树第K层结点统计
2.5.6 获取二叉树的高度
2.5.7 检测值为value的元素是否存在
2.5.8 判断一棵树是否为完全二叉树
2.6 二叉树的非递归方法
2.6.1 非递归实现前序遍历
2.6.2 非递归实现中序遍历
2.6.3 非递归实现后序遍历
1.树形结构
1.1 树的概念
树是一种非线性数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合,把它称为树是因为它看起来像一棵倒挂的树,根在上,枝叶在下。
① 根节点是一个没有前驱结点的特殊结点;
② 除根节点外,其余结点被分为M(M>0)个互不相交的集合T1,T2,T3...Tm,其中每一个集合Ti(1<=i<=m)又是一棵结构与树类型相似的子树,每棵树的根节点有且仅有一个前驱,可以有0个或多个后继;
③ 因此,树是递归定义的;
PS:树形结构中,子树之间不能有交集,即除了根节点之外,每个结点有且仅有一个直接前驱;
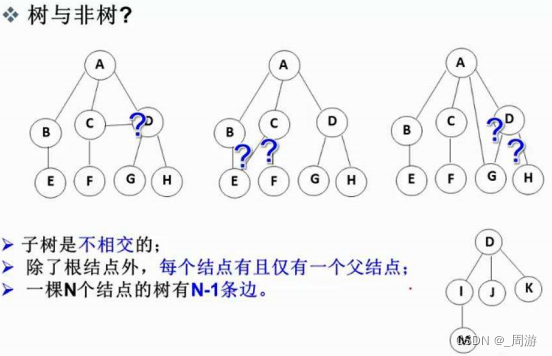
1.2 树的相关概念

(1)结点的度:一个结点含有的子树的个数,如A结点的度为6;
(2)叶结点或终端结点:度为0的结点,如H、I、P、Q、K、L、M、N;
(3)非终端结点或分支结点:度不为0的结点,如:D、E、F、G、J;
(4)双亲结点或父节点:含有子结点的结点,称该结点为其子结点的父结点,如A是B的父结点;
(5)孩子结点或子结点:一个结点含有的子树的根节点称为该结点的子结点,如B是A的子结点;
(6)兄弟结点:具有相同父结点的结点,如B和C是兄弟结点;
(7)数的度:一棵树中最大的结点的度称为数的度,如上图树的度为6;
(8)结点的层次:从根开始定义,根为第一层,根的子结点为第二层,以此类推;
(9)树的高度或深度:树中结点的最大层次,如上图树的高度或深度为4;
(10)堂兄弟结点:双亲在同一层的结点称为堂兄弟,如H和I互为堂兄弟结点;
(11)结点的祖先:从根到该结点所经分支上的所有结点,如A是所有结点的祖先;
(12)子孙:以某节点为根的子树中任一结点都成为该结点的子孙,如所有节点都是A的子孙;
(13)森林:由m(m>0)棵互不相交的树的集合称为森林;
1.3 树的表示
树的存储相较于线性表要复杂得多,既要存储值域,也要存储结点与结点之间的关系;
树有很多种表达方式,如双亲表示法、孩子表示法、孩子-双亲表示法。
最常用的是:左孩子-右兄弟表示法。
图示:

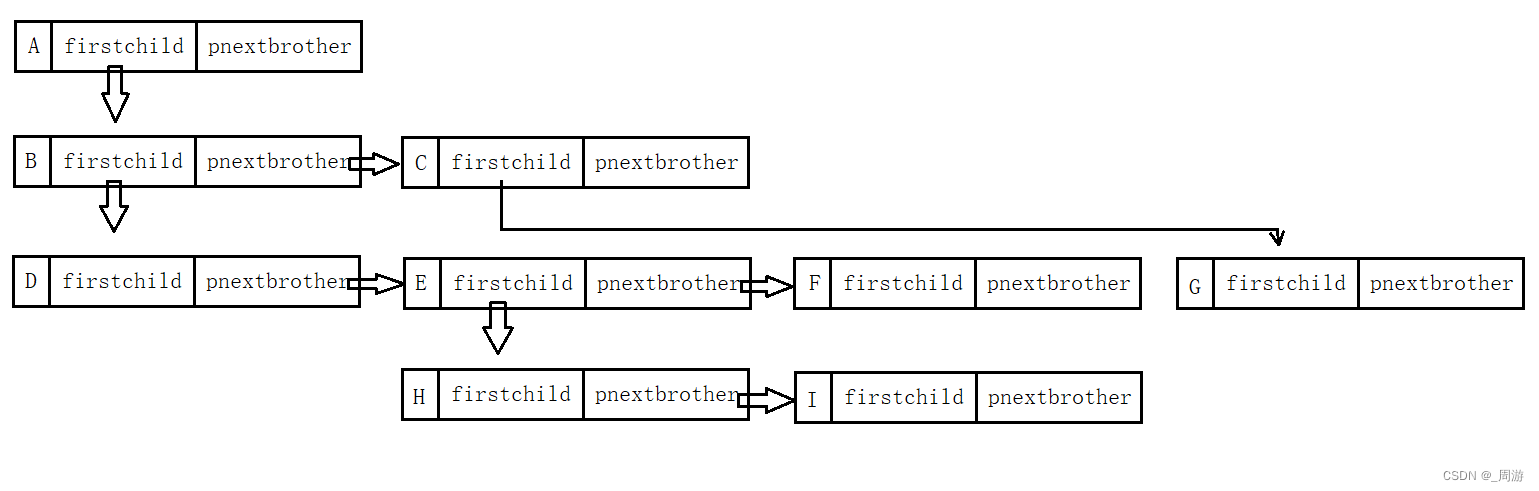
代码表示:
class Node{int val; // 数据域Node firstChild; // 第一个孩子引用Node nextBrother; // 下一个兄弟引用
}
//注意此处的兄弟指的是亲兄弟而非堂兄弟,即此处指向的兄弟有相同的祖先1.4 树在实际中的应用—表示文件系统的目录树结构

2.二叉树
2.1 概念
(1)一个二叉树的结点是一个有限集合,该集合:① 或者为空 ② 有一个根节点加上两个别称为左子树和右子树的二叉树组成;
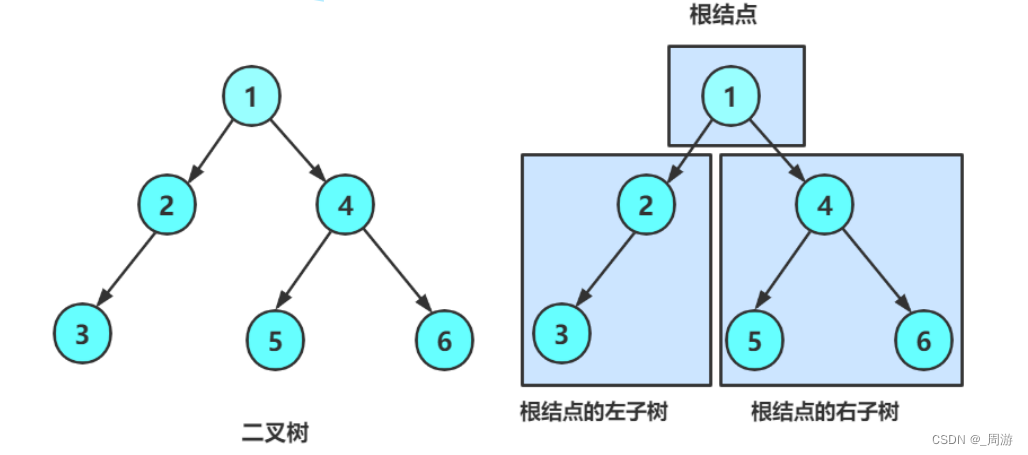
(2)特点:
① 不存在度大于2的结点;
② 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树;
(3)任意一种二叉树都是由①空树②只有根节点③只存在左子树④只存在右子树⑤左右子树均存在这五种情况复合而成;
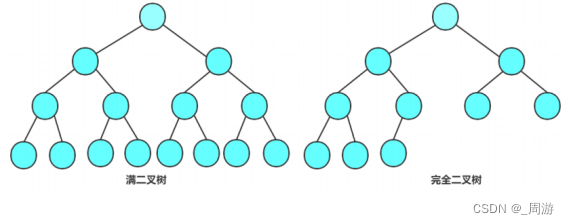
2.2 特殊二叉树
(1)满二叉树:
每层节点数都是最大值的二叉树,即满足层数为k,结点总数是2^k-1的二叉树就是完全二叉树。
(2)完全二叉树:
对于深度为k的二叉树,前k-1层的结点都是满的,最后一层不满但满足,存在的结点是从左向右是连续的。
2.3 二叉树的性质
(1)若规定根结点层数为1,则一棵非空二叉树的第i层上最多有2^(i-1)个结点;
(2)若规定根结点层数为1,则深度为h的二叉树的最大结点数是2^k-1;
(3)对任何一个二叉树,如果度为0的结点个数为n0,度为2的分支节点个数为n2,则有n0=n2+1;
(4)若规定根节点的层数为1,具有n个结点的满二叉树的深度,h=log2(n+1)(以2为底);
例1:某二叉树共有399个结点,其中199个度为2的结点,则该二叉树中的叶子节点数为(B)
A.不存在这样的二叉树 B.200 C.198 D. 199
解析:根据第三条性质,叶子结点数即度为0的结点数,根据第三条性质得答案。
例2:在具有2n个结点的完全二叉树中,叶子结点个数为(A)
A.n B.n+1 C. n-1 D.n/2
解析:度为0的结点记为n0,度为1的结点记为n1,度为2的结点记为n2,根据题意有:
n0+n1+n2=2n,结合第三条性质有:n2=n0-1,代入有2*n0-1+n1=2n,对于一个完全二叉树来
说,度为1的结点只能有0个或1个,此处若n1=0,则n0为小数,故而n1只能为1,所以度为0的结
点个数为n。
例3:一个完全二叉树结点数为531个,那么这棵树的高度为(B)
A.11 B. 10 C.8 D.12
解析:高度为h的完全二叉树,结点范围是[2^(h-1),2^h-1],代入选项进行上下限计算得答案。
例4:一个具有767个结点的完全二叉树,其叶子结点个数为(B)
A.383 B. 384 C.385 D.386
解析略,同例二思路
2.4 二叉树的存储结构
二叉树的存储有两种存储方式:
2.4.1 顺序存储结构(数组存储结构)
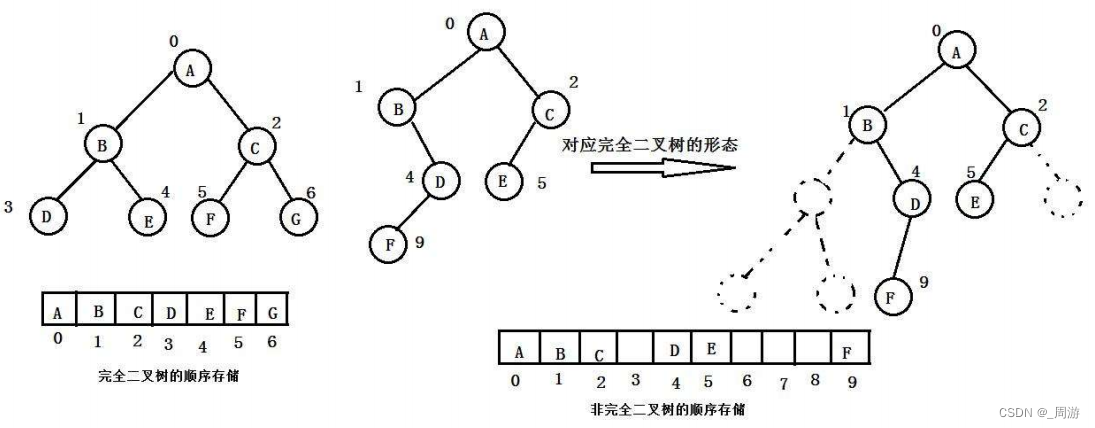
① 一般使用数组存储只适合表示完全二叉树或满二叉树,若是一般二叉树会存在很多空间浪费;
在现实使用中,只有对才会使用数组来存储;
② 二叉树的顺序存储在物理上是一个数组,在逻辑上是一个二叉树。
③ 同时顺序存储可以根据下标计算结点父子关系:
知父求子:leftchild=parent*2+1,leftchild=parent*2+2;
知子求父:(parent-1)/2;
2.4.2 链式存储结构
二叉树的链式存储是通过一个一个的结点引用起来的,常见的表示方式有:
(1)二叉表示法(孩子表示法):
class Node{int val; // 数据域Node left; // 左孩子引用(常代表以左孩子为根的整个左子树)Node right; // 右孩子引用(常代表以右孩子为根的整个右子树)
}(2)三叉表示法(孩子-双亲表示法):
class Node{int val; // 数据域Node left; // 左孩子引用(常代表以左孩子为根的整个左子树)Node right; // 右孩子引用(常代表以右孩子为根的整个右子树)Node parent; // 当前结点的根节点
}孩子-双亲表示法主要应用在平衡树,本文采取孩子表示法构建二叉树;
2.5 二叉树的基本操作
2.5.1 二叉树的深度优先遍历
深度优先遍历包括前序遍历、中序遍历与后序遍历;
前序遍历:访问根结点的操作发生在遍历其左右子树之前;(跟->左子树->右子树)
中序遍历:访问根结点的操作发生在遍历其左右子树之中;(左子树->根->右子树)
后序遍历:访问根结点的操作发生在遍历其左右子树之后;(左子树->右子树->根)

以#表示空:
前序遍历:1 2 3 # # # 4 5 # # 6 # #
中序遍历:# 3 # 2 # 1 # 5 # 4 # 6 #
后序遍历:# # 3 # 2 # # 5 # # 6 4 1
基于以下二叉树结构:
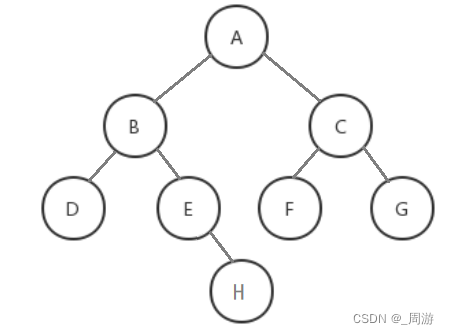
其递归实现代码如下:
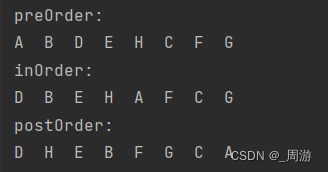
// 前序遍历:根 左子树 右子树 递归public void preOrder(TreeNode root){if(root == null){return;}System.out.print(root.val+" ");preOrder(root.left);preOrder(root.right);}// 中序public void inOrder(TreeNode root){if(root == null){return;}inOrder(root.left);System.out.print(root.val+" ");inOrder(root.right);}// 后序public void postOrder(TreeNode root){if(root == null){return;}postOrder(root.left);postOrder(root.right);System.out.print(root.val+" ");}创建对象后分别调用,输出结果为:
注:除过空返回值的写法外,也可以令深度优先遍历有返回值:
(1)遍历思路写法:
List<Character> ret = new ArrayList<>();public List<Character> preorderTraversal(TreeNode root){if(root == null){return ret;}ret.add(root.val);preorderTraversal(root.left);preorderTraversal(root.right);return ret;}(2)子问题思路写法:
public List<Character> preorderTraversal(TreeNode root){List<Character> ret = new ArrayList<>();if(root == null){return ret;}//System.out.print(root.val+" ");ret.add(root.val);List<Character> leftTree = preorderTraversal(root.left);ret.addAll(leftTree);List<Character> rightTree = preorderTraversal(root.right);ret.addAll(rightTree);return ret;}2.5.2 二叉树的广度优先遍历
创建一个队列,令cur从root开始遍历,在根节点不为空的条件下,将root入队列,依次判断root.left和root.right是否为空,非空则入队列,当队列不为空时,出栈对首元素并令root = cur;
public void levelOrder(TreeNode root){if(root == null){return;}Queue<TreeNode> queue = new LinkedList<>();queue.offer(root);while(!queue.isEmpty()){TreeNode cur = queue.poll();System.out.print(cur.val+" ");if(cur.left != null){queue.offer(cur.left);}if(cur.right != null){queue.offer(cur.right);}}}输出结果为:

2.5.3 二叉树的结点统计
(1)思路1:子问题思路:
public int size(TreeNode root){// 左树结点+右树结点+根节点// 写法1://return root == null? 0: size(root.left)+size(root.right)+1;// 写法2:if(root == null){return 0;}int leftSize = size(root.left);int rightSize = size(root.right);return leftSize + rightSize + 1;}(2)思路2:遍历思路:
public int nodeSize;public void size2(TreeNode root){if(root == null){return;}nodeSize++;size2(root.left);size2(root.right);}测试代码为:
System.out.println("子问题思路求二叉树结点:");System.out.println(binaryTree.size(binaryTree.root));System.out.println("遍历思路求二叉树结点:");binaryTree.size2(binaryTree.root);System.out.println(binaryTree.nodeSize);输出结果为:

2.5.4 二叉树的叶子结点统计
(1)思路1:子问题思路:
public int getLeafNodeCount(TreeNode root){if(root == null){return 0;}if(root.left==null && root.left == null){return 1;}int leftTreeNode = getLeafNodeCount(root.left);int rightTreeNode = getLeafNodeCount(root.right);return leftTreeNode+rightTreeNode;}(2)思路2:遍历思路:
public int leafNode = 0;public void getLeafNodeCount2(TreeNode root){if(root == null){return;}if(root.left == null && root.right == null){leafNode++;}getLeafNodeCount2(root.left);getLeafNodeCount2(root.right);}测试代码为:
System.out.println("子问题思路求叶子节点的个数为:");System.out.println(binaryTree.getLeafNodeCount(binaryTree.root));System.out.println("遍历思路求叶子结点个数为:");binaryTree.getLeafNodeCount2(binaryTree.root);System.out.println(binaryTree.leafNode);输出结果为:

2.5.5 二叉树第K层结点统计
(仅展示子问题思路)
public int getKLevelNodeCount(TreeNode root, int k){if(root == null){return 0;}if(k==1){return 1;}int leftTreeNode = getKLevelNodeCount(root.left,k-1);int rightTreeNode = getKLevelNodeCount(root.right,k-1);return leftTreeNode+rightTreeNode;}测试代码为:
TestBinaryTree binaryTree = new TestBinaryTree();binaryTree.root = binaryTree.createTree();System.out.println("请输入要查询结点的层数:");Scanner scanner = new Scanner(System.in);int k = scanner.nextInt();System.out.println("第"+k+"层结点数为:");System.out.println(binaryTree.getKLevelNodeCount(binaryTree.root,k));输出结果为:
2.5.6 获取二叉树的高度
public int getHeight(TreeNode root){// 二叉树高度是左右子树高度的较大值+1if(root==null){return 0;}int leftTreeHeight = getHeight(root.left);int rightTreeHeight = getHeight(root.right);return (leftTreeHeight>rightTreeHeight)?leftTreeHeight+1:rightTreeHeight+1;}测试代码为:
TestBinaryTree binaryTree = new TestBinaryTree();binaryTree.root = binaryTree.createTree();System.out.println("当前二叉树高度为:");System.out.println(binaryTree.getHeight(binaryTree.root));输出结果为:

2.5.7 检测值为value的元素是否存在
public TreeNode find(TreeNode root, char val){// 前序遍历二叉树if(root == null){return null;}if(root.val == val){return root;}TreeNode leftTree = find(root.left, val);if(leftTree != null){return leftTree;}TreeNode rightTree = find(root.right, val);if(rightTree != null){return rightTree;}return null;}测试代码为:
TestBinaryTree binaryTree = new TestBinaryTree();binaryTree.root = binaryTree.createTree();System.out.println("请输入要查询的value值:");char value = (char)System.in.read();TestBinaryTree.TreeNode ret = binaryTree.find(binaryTree.root, value);if(ret != null){System.out.println(ret.val);}else {System.out.println(ret);}输出结果为·:
2.5.8 判断一棵树是否为完全二叉树
创建一个队列,在根结点不为空的前提下,先将根结点入队列,然后每弹出一个队首元素,就将其左右孩子结点入队列,直到队首元素为空,若此时队列中元素全为空,则为完全二叉树,否则就不是完全二叉树;
代码:
public boolean isCompleteTree(TreeNode root){if(root == null){return true;}Queue<TreeNode> queue = new LinkedList<>();queue.offer(root); // 将根结点入队列while( !queue.isEmpty()) {// 每弹出一个队首元素,就将该元素的左右孩子入队列;TreeNode cur = queue.poll();if (cur != null) {queue.offer(cur.left);queue.offer(cur.right);} else {// 一直出队列队首元素直至队首元素为nullbreak;}}while(!queue.isEmpty()){TreeNode tmp = queue.poll();if(tmp != null){return false;}}return true;}测试代码为:
TestBinaryTree binaryTree = new TestBinaryTree();binaryTree.root = binaryTree.createTree();System.out.println("判断是否为完全二叉树:");System.out.println(binaryTree.isCompleteTree(binaryTree.root));System.out.println();输出结果为: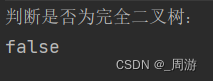
基于原二叉树,删除E结点的右孩子H结点,再次测试结果如下:
2.6 二叉树的非递归方法
2.6.1 非递归实现前序遍历
定义cur结点用于遍历二叉树,从根结点root开始,令cur依次遍历左子树,在结点左孩子不为空的前提下,将结点逐个入栈,每入栈一个结点,就打印一个结点,当遇到左孩子为空的结点后,弹出栈顶元素并令cur为其右孩子;
public void preOrderNor(TreeNode root){if(root == null){return;}TreeNode cur = root;Deque<TreeNode> stack = new ArrayDeque<>();while(cur != null || !stack.isEmpty()) {while (cur != null) {stack.push(cur);System.out.print(cur.val + " ");cur = cur.left;}// 此时为cur为空但栈不为空:// 令cur为栈顶元素的右孩子即可TreeNode top = stack.pop();cur = top.right;}}2.6.2 非递归实现中序遍历
public void inOrderNor(TreeNode root){if(root == null){return;}TreeNode cur = root;Deque<TreeNode> stack = new ArrayDeque<>();while(cur != null || !stack.isEmpty()){while(cur != null){stack.push(cur);cur = cur.left;}TreeNode top = stack.pop();System.out.print(top.val+" ");cur = top.right;}}2.6.3 非递归实现后序遍历
public void postOrderNor(TreeNode root){if(root == null){return;}TreeNode cur = root;TreeNode prev = null;Deque<TreeNode> stack = new ArrayDeque<>();while(cur != null || !stack.isEmpty()){while(cur != null){stack.push(cur);cur = cur.left;}TreeNode top = stack.peek();if(top.right == null || top.right == prev){// 栈顶元素没有右孩子,根据左->右->根,可以直接打印根结点的值System.out.print(top.val+" ");stack.pop();prev = top;}else {// 栈顶元素有右孩子,还需遍历当前栈顶元素结点的右子树cur = top.right;}}}非递归实现前中后序遍历的测试代码如下:
TestBinaryTree binaryTree = new TestBinaryTree();binaryTree.root = binaryTree.createTree();System.out.println("非递归实现前序遍历:");binaryTree.preOrderNor(binaryTree.root);System.out.println();System.out.println("非递归实现中序遍历:");binaryTree.inOrderNor(binaryTree.root);System.out.println();System.out.println("非递归实现后序遍历:");binaryTree.postOrderNor(binaryTree.root);System.out.println();输出结果如下:
