营销型 展示类网站模板wordpress 登录信息
在日益激烈的市场竞争中,对产品质量严格把关,是制造企业提高核心竞争力与品牌价值的关键因素。那如何高效、高质地完成产品质检工作?这就需要企业在工业质检中引进数字化技术加以辅助,进而推动智能制造高质量发展。
蓝库云QMS质量检验管理系统,涵盖来料检验、工序检验、产品检验、发/退货检验、库存检验、样品管理等多个层面,可有效解决产品送检及验收流程卡顿、质检执行不到位、统计效率低等难题,确保产品质量的稳定性和可控性。

质量检验管理-严格管理质量检验各环节,提高产品质量按照制造业所涉及的产品生产线,对来料、工序、产品、发退货、库存进行精细检验,严格审核每一环节,提高产品质量。
自定义设置材料、半成品、成品品质标准和检验规范,统一抽样标准,确保来料及成品的质量稳定、良好。
送检、检验、审批等全流程自动流转,有效地提高各个部门的合作效率。在检验单中,质检员需要选择已经设置好的质检方案,严格按照质检方案标准去执行。
不良品处理-在线发起不良品处理,规范不良品处理操作当出现不合格品时,质检员可填写不良明细,明确不良原因,在线发起不良品处理。流程自动流转至不良品处理意见人或者质量主管,对不良品进行返工、返修、降级、拒收、报废、退货等处理操作。

样品管理取样、销毁、留样记录在线留存检验过程中,可实时登记取样记录、样品销毁记录以及留样观察记录。在对样品进行周期性观察时,系统会根据观察周期,自动计算观察日期,并在下个观察日前进行提醒,确保观察的准时性。
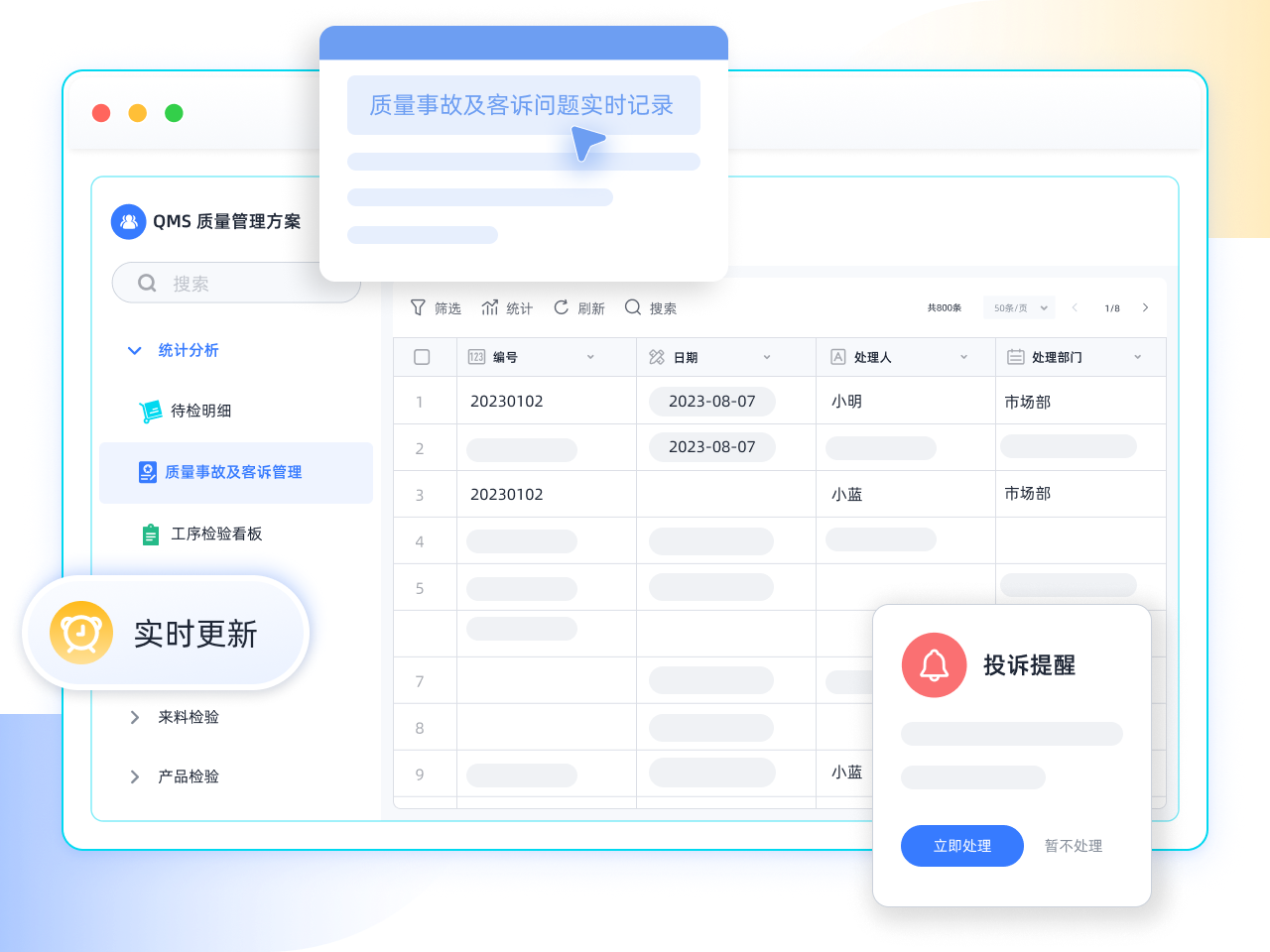
质量事故及客诉管理-实时记录,避免质量问题重复发生
实时记录客户投诉和质量事故。针对调查结果,提出改进或预防措施,避免质量问题重复发生。
质检看板-质检数据实时更新,已检、待检一目了然
质检大量流转数据自动进行统计,形成可视化图表,大幅减少人力处理数据的工作量。
质检数据实时更新,主管可以查看已检,待检数量以及质检明细,确保质检管理的高效性。