做透明头像的网站深圳公司网站建设哪里专业

今天给大家介绍一款自动化测试框架Poco,其脚本写法非常简洁、高效,其元素定位器效率更快,其本质基于python的第三方库,调试起来也会非常方便,能够很好的提升自动化测试效率,节省时间。
(一)背景
1. Poco介绍
Poco是一款跨平台的自动化测试框架,基于UI控件识别原理,适用于Android、iOS原生和各种主流的游戏引擎应用,由于Airtest是基于图像识别原理,所以Poco+Airtest结合使用更适合混合应用。尤其是针对flutter app部分元素控件无法识别情况,采用airtest框架,针对元素控件的部分,采用Poco框架进行自动化测试。
2. Poco本质
Poco和Airtest框架一样,Poco实际上也是Python的一个第三方库,如果需要本地编写Poco脚本,需要先安装Pocoui库即可
pip install pocoui
3. 官方文档
https://airtest.doc.io.netease.com/IDEdocs/poco_framework/1_poco_info/
(二)使用Poco框架
1. 查看控件元素
在AirtestIDE连接待测设备后,然后在Poco辅助窗口选择对应的设备进行查看

备注:选择模式时,脚本编辑窗口顶部会让我们选择是否插入对应的初始化代码,我们选择Yes即可
2. 查看控件的方式
第一种:冻结模式
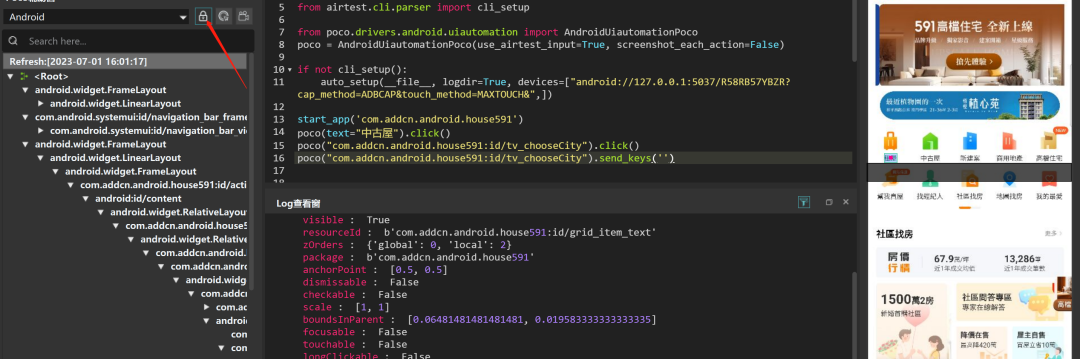
进入模式:点击下图冻结按钮
说明:单击下图箭头区域,则会进入冻结模式查看元素控件,光标移至右侧的元素位置,并点击相应元素控件,则自动会定位到页面层级,log窗口可以查看当前层面的元素属性。即使实际连接的被测设备已经离开当前页面,冻结模式也不会受影响,相当于一直冻结在这个页面,便于查看元素
退出方式:再次点击冻结按钮
第二种:检视模式
进入模式:点击下图检视按钮
说明:单击下图箭头区域,则会进入检视模式查看元素控件,与刚才的冻结模式最大的区别是,此时查看控件,如我们对控件进行操作,设备画面也会跟着变化
退出方式:再次点击检视按钮
3. 定位元素的方式
基本定位器
由于AirtestIDE内置Poco,直接导入即可使用,基本定位器就是poco(节点名或节点属性)
# -*- encoding=utf8 -*-
__author__ = "86150"
from poco.drivers.android.uiautomation import AndroidUiautomationPoco
poco = AndroidUiautomationPoco(use_airtest_input=True, screenshot_each_action=False)# 单个条件
poco(text="中古屋")# 多个条件
poco('com.addcn.android.house591:id/grid_item_text',text="中古屋")
相对选择器
就是通过元素之间的层级关系进行选择,例如父子关系、兄弟关系、祖先后代关系等等,Poco控件给我们提供了利用树的层级关系来定位的各种方法:
- 子节点:child
- 所有子节点:children
- 子孙节点:offspring
- 父节点:parent
- 兄弟节点:sibling
poco("plays").child("playBasic").offspring("star_single")
说明:这种方式较为繁琐,一般是通过属性和节点无法定位的时候,可以选择使用这种方式
正则表达式
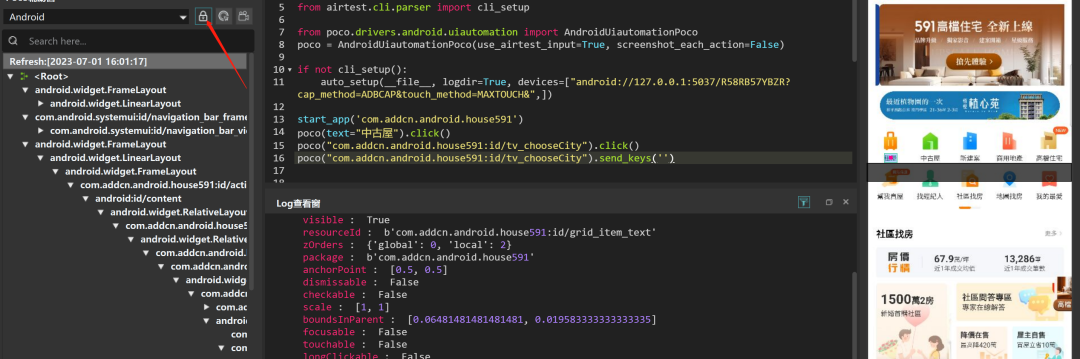
正则表达式匹配时一种少见的方式,但也是非常好用的方式,按照下图通过属性定位的方式为:
# 1.text属性方式定位
poco(text="中古屋")
# 换成正则表达式定位
poco(textMatches="正则表达式")
poco(textMatches=".*中古屋")# 2.name属性方式定位
poco(name='com.addcn.android.house591:id/grid_item_text')
# 换成正则表达式定位
poco(nameMatches="正则表达式")
poco(nameMatches=".*grid_item_text")
说明:只要能够用 poco(xx=预期属性值) 来选择的控件,就可以用 poco(xxMatches=预期属性值的正则表达式) 来进行匹配定位,官方推荐优先使用属性或正则表达式定位,会更加简介高效
4. 操作元素的方式
点击
# 单击元素poco(text="中古屋").click()# 长按元素poco(text="中古屋").long_click()
滑动
Poco支持对控件进行滑动操作,我们需要先定位到这个控件,然后指定它按照某个方向滑动即可
# 向下滑动0.2个单位距离
poco("com.addcn.android.house591:id/grid_item_text").swipe([0,0.2])# 向上滑动0.2个单位距离
poco("com.addcn.android.house591:id/grid_item_text").swipe([0,-0.2])# 向下滑动0.1个单位距离
poco("com.addcn.android.house591:id/grid_item_text").swipe("down")# 向上滑动0.1个单位距离
poco("Handle").swipe("up")
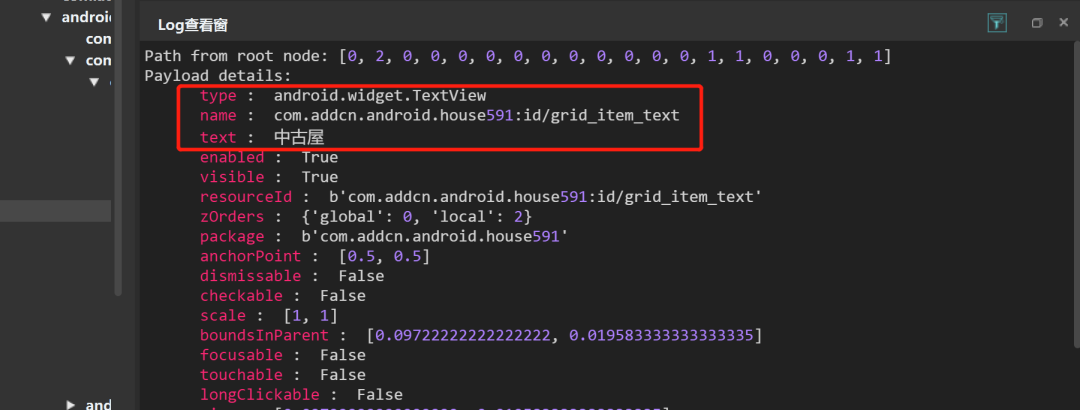
获取元素的属性值
在IDE的poco辅助窗检索出来的控件属性,基本上都可以通过 attr 接口读取出来
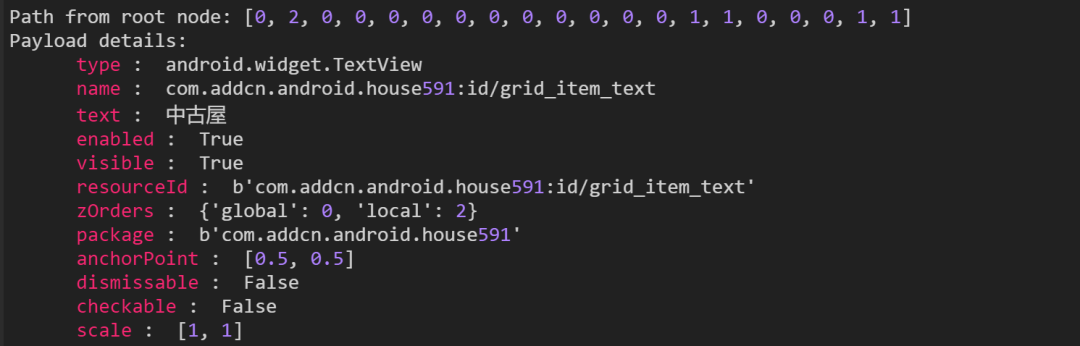
print("name:"+poco(text="中古屋").attr("name"))
print("type:"+poco(text="中古屋").attr("type"))
print("texture:"+poco(text="中古屋").attr("text"))
print("texture:"+poco(text="中古屋").attr("texture"))# log日志输出
name:com.addcn.android.house591:id/grid_item_text
type:android.widget.TextView
texture:中古屋
[Finished]
设置元素的属性值
通常情况需要给定位的元素输入文本内容,可以使用set_text()方法或setatrr()方法
from airtest.core.api import *
auto_setup(__file__)
from poco.drivers.android.uiautomation import AndroidUiautomationPoco
poco = AndroidUiautomationPoco(use_airtest_input=True, screenshot_each_action=False)# 先激活输入光标
poco("com.addcn.android.house591:id/et_edittext").click()# 再执行输入动作
poco("com.addcn.android.house591:id/et_edittext").set_text("123")poco("com.addcn.android.house591:id/et_edittext").setattr('text',"456")
Poco脚本相较于Appium脚本更加简洁、高效,使用起来更加方便,尤其是针对混合应用、Flutter APP 等应用能够结合Airtest框架一起使用,能够很好解决部分元素控件无法定位的问题。目前来说,我觉得是挺好用,下期可以出一篇两个测试框架结合的应用~
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!