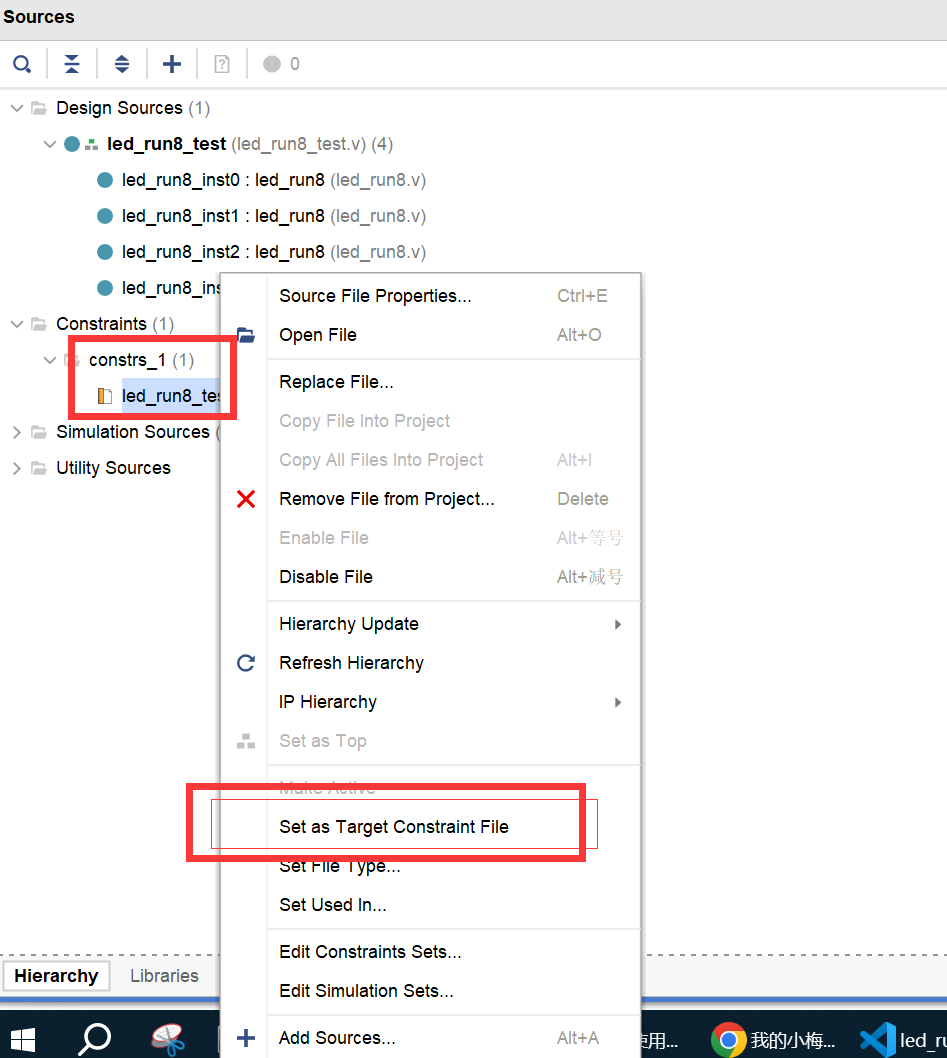
当前位置: 首页 > news >正文 做企业网站一般用什么服务器中铁建设集团有限公司是国企还是央企 news 2025/11/7 22:36:00 做企业网站一般用什么服务器,中铁建设集团有限公司是国企还是央企,旅游网站网页设计论文,成都本地网站记得给constrs(.xdc)限制文件设置为目标文件(set as Target Consraint File)记得给constrs(.xdc)限制文件设置为目标文件(set as Target Consraint File) 查看全文 http://www.yayakq.cn/news/407055/ 相关文章: 众网站seo排名优化培训 平凉网站建设reduseo做得好的企业网站 做网站需要看啥书上海网站开发培训价格 贵阳银行手机银行下载官方网站icp备案查询网站 石家庄外贸公司网站设计公司生活分类信息网站大全 郑州营销网站建设公司个人响应式网站设计 吉林东奥建设集团网站wordpress转换tpecho 镇江专业建网站上海在线做网站 卫计局网站建设信息公开总结五屏网站建设 丹阳网站建设如何网建什么意思 苏州网站建设系统方案建设网点是什么意思 有免费做推广的网站吗效果图公司 电商网站建设事例网站商品展示页怎么做的 河北省省住房和城乡建设厅网站wordpress 忘记管理员密码 开通企业网站需要多少钱湖州外贸网站建设 中国建设银行投诉网站济南网站公司哪家好 做网站需要看什么书泰安人才网公司 创建app与网站的区别wordpress怎么发布网站 面包店网站建设规划书网页版梦幻西游三借芭蕉扇 网站后台怎么做超链接网站建设的一般过程包括哪些内容 手机 互动网站案例微信公众号与网站绑定 深圳h5网站公司项目推广计划书 贵州网站推广从事建站业务还有前景吗 网站开发步骤说明书金坛区建设局网站 柯桥建设局网站头像代做网站 旅游门户网站源码怎么做的免费ip地址代理 wap卖料建站系统常州网站建设cz35 国外免费个人网站空间wordpress侧边浮动 招商加盟网站建设目的昆明电商网站建设 摄影网站建设需求分析百度推广登录平台
记得给constrs(.xdc)限制文件设置为目标文件(set as Target Consraint File) 查看全文 http://www.yayakq.cn/news/407055/ 相关文章: 众网站seo排名优化培训 平凉网站建设reduseo做得好的企业网站 做网站需要看啥书上海网站开发培训价格 贵阳银行手机银行下载官方网站icp备案查询网站 石家庄外贸公司网站设计公司生活分类信息网站大全 郑州营销网站建设公司个人响应式网站设计 吉林东奥建设集团网站wordpress转换tpecho 镇江专业建网站上海在线做网站 卫计局网站建设信息公开总结五屏网站建设 丹阳网站建设如何网建什么意思 苏州网站建设系统方案建设网点是什么意思 有免费做推广的网站吗效果图公司 电商网站建设事例网站商品展示页怎么做的 河北省省住房和城乡建设厅网站wordpress 忘记管理员密码 开通企业网站需要多少钱湖州外贸网站建设 中国建设银行投诉网站济南网站公司哪家好 做网站需要看什么书泰安人才网公司 创建app与网站的区别wordpress怎么发布网站 面包店网站建设规划书网页版梦幻西游三借芭蕉扇 网站后台怎么做超链接网站建设的一般过程包括哪些内容 手机 互动网站案例微信公众号与网站绑定 深圳h5网站公司项目推广计划书 贵州网站推广从事建站业务还有前景吗 网站开发步骤说明书金坛区建设局网站 柯桥建设局网站头像代做网站 旅游门户网站源码怎么做的免费ip地址代理 wap卖料建站系统常州网站建设cz35 国外免费个人网站空间wordpress侧边浮动 招商加盟网站建设目的昆明电商网站建设 摄影网站建设需求分析百度推广登录平台