长沙建设网站企业网站开发个人简介范文
博主介绍: ✌全网粉丝30W+,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战 ✌
🍅 文末获取源码联系 🍅
👇🏻 精彩专栏 推荐订阅 👇🏻 不然下次找不到哟
Java项目精品实战案例《100套》
Java微信小程序项目实战《100套》

系统介绍:
为了让系统的编码可以顺利进行,特意对本系统功能进行细分设计,管理员的功能在经过细分后,设计的功能结构见下图。管理员管理班级和课程的关系,管理奖惩类型,课程和专业信息。

图4.1 管理员功能结构图
老师的功能在经过细分后,设计的功能结构见下图。老师负责学生成绩和学生奖惩信息的管理,查询任课课程。

图4.2 老师功能结构图
学生的功能在经过细分后,设计的功能结构见下图。学生主要查询成绩,查询奖惩信息,查看班级和班级课程。
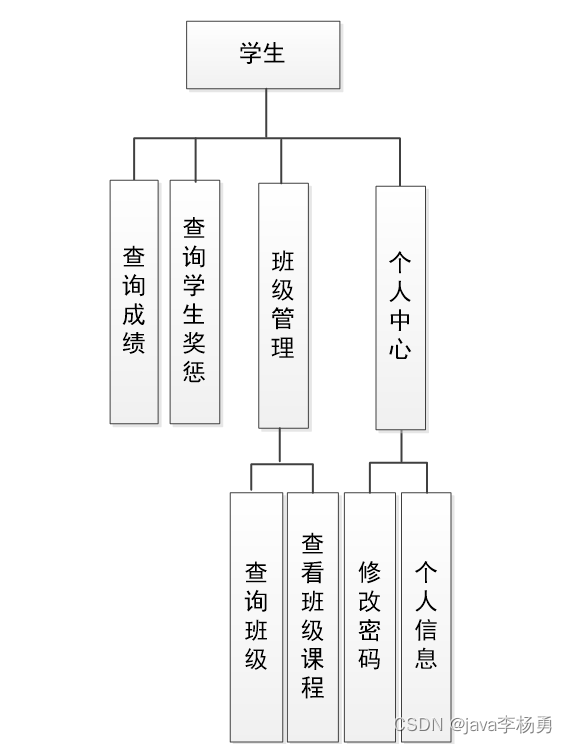
图4.3 学生功能结构图
程序上交给用户进行使用时,需要提供程序的操作流程图,这样便于用户容易理解程序的具体工作步骤,现如今程序的操作流程都有一个大致的标准,即先通过登录页面提交登录数据,通过程序验证正确之后,用户才能在程序功能操作区页面操作对应的功能。

程序操作流程图
功能截图:
5.1.1班级和课程关系管理
管理员管理班级和课程关系,其运行效果见下图。在本页面,每个班级对应的课程以及任课老师信息都会清楚的展示,管理员可修改,也能删除。

图5.1 班级和课程关系管理页面
5.1.2老师管理
管理员管理老师。其运行效果见下图。老师是本系统中的一个角色,其信息需要管理员管理。

图5.2 老师管理页面
5.1.3奖惩类型管理
管理员可以管理奖惩类型,其运行效果见下图。管理员修改奖惩类型名称,提交奖惩类型名字获取对应信息。

图5.3 奖惩类型管理页面
5.2 老师功能实现
5.2.1成绩管理
老师管理成绩。其运行效果见下图。老师登记各个学生的课程学习分数,可以根据分数段查询学生成绩。

图5.4 成绩管理页面
5.2.2学生奖惩管理
老师管理学生奖惩,其运行效果见下图。学生的奖励和惩罚信息需要教师添加和管理。
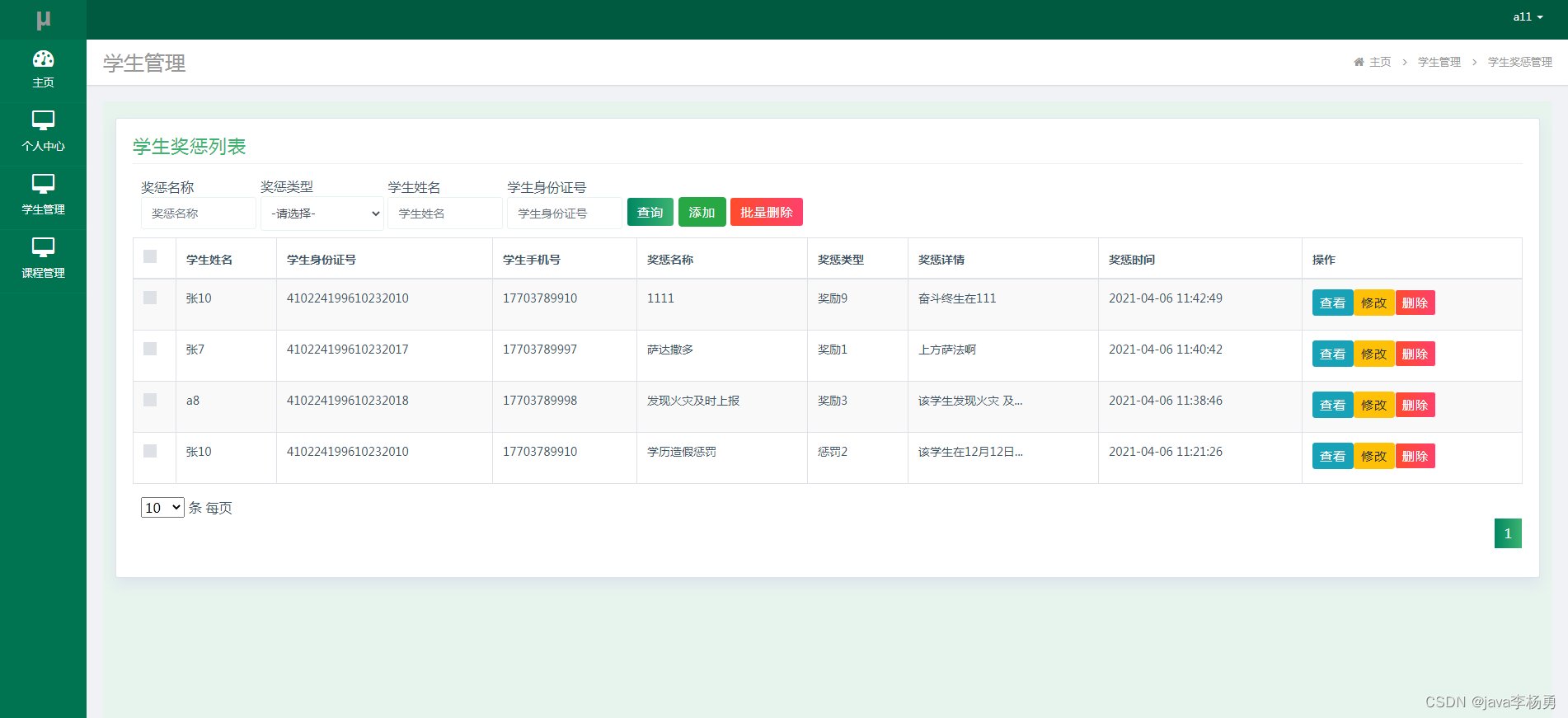
图5.5 学生奖惩管理页面
5.2.3课程管理
老师管理课程,其运行效果见下图。老师在当前页面查看课程,也能根据老师姓名查询对应课程信息。
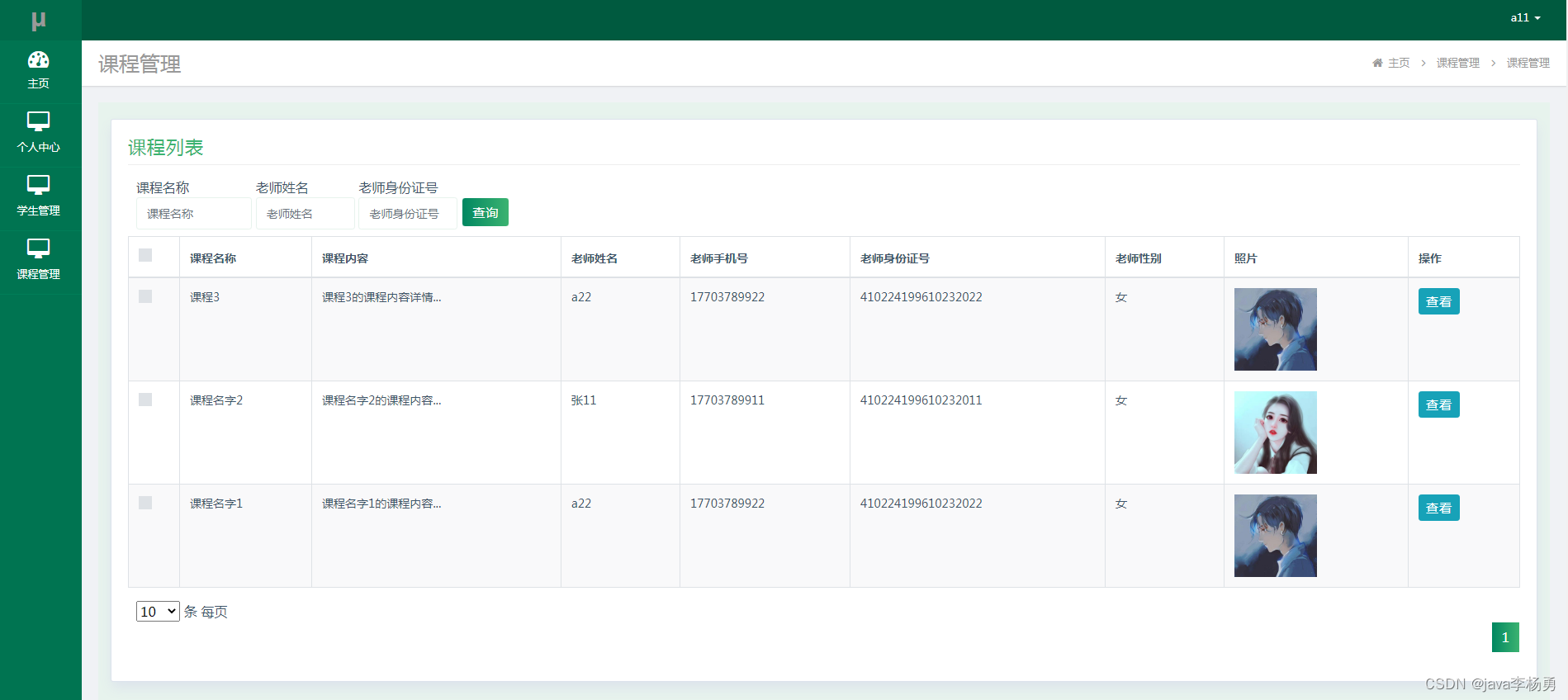
图5.6 课程管理页面
5.3 学生功能实现
5.3.1班级管理
学生管理班级。其运行效果见下图。学生除了可以查询班级信息之外,还可以查看该班级的课程信息。
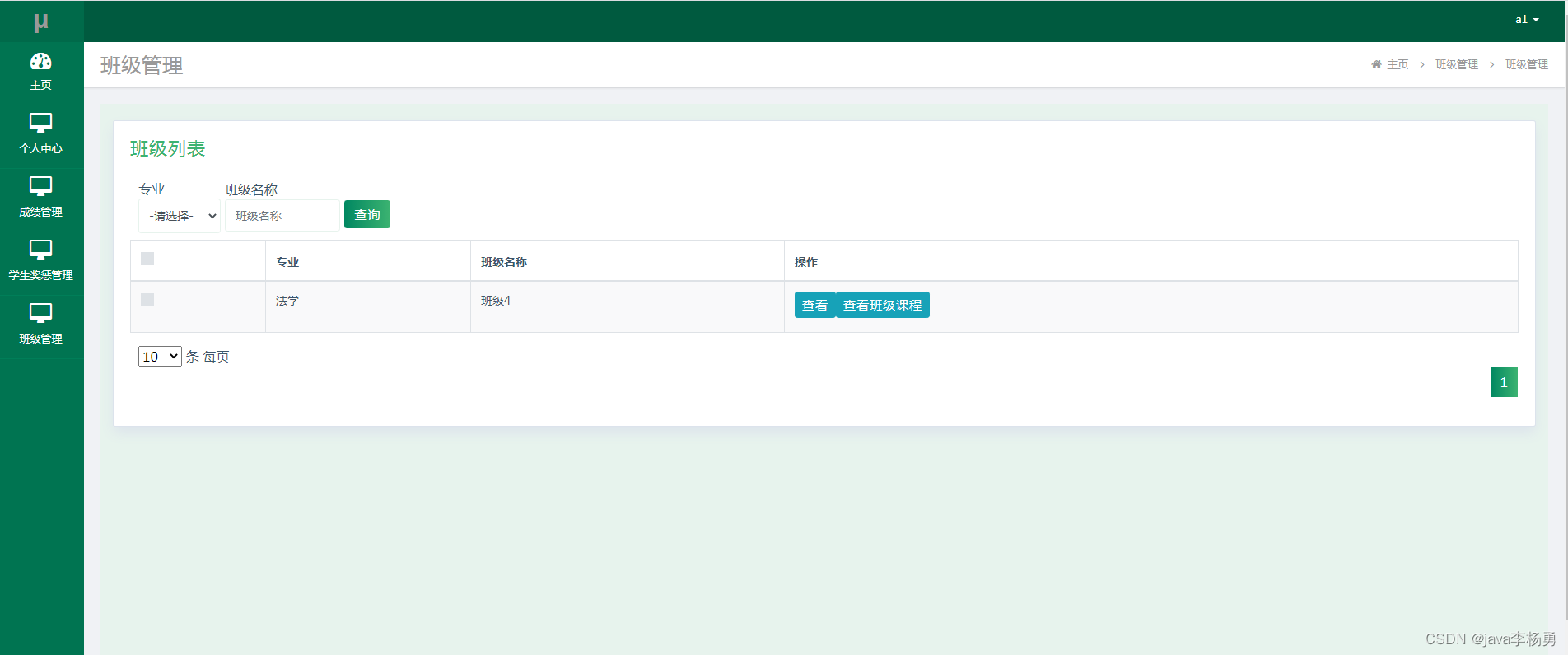
图5.7 班级管理页面
5.3.2查询成绩
学生查询成绩,其运行效果见下图。学生在本人后台就能查询成绩。根据课程名称,或者是分数段信息就能查询成绩。
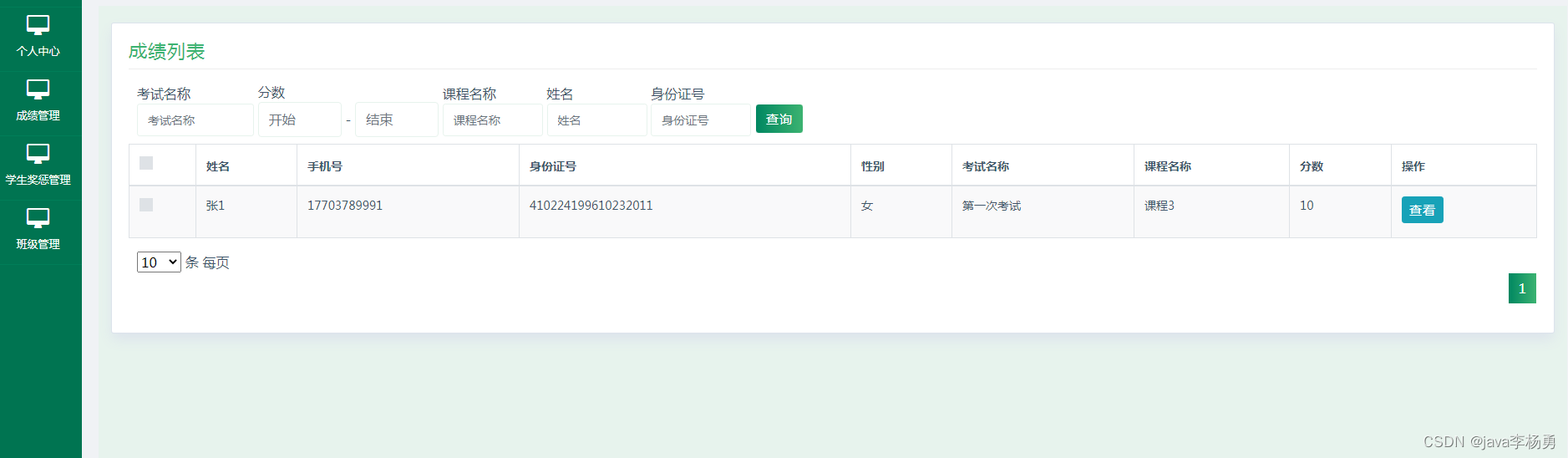
图5.8 查询成绩页面
5.3.3修改密码
学生修改密码。其运行效果见下图。学生在本页面设置新密码,密码设置成功之后,需要重新登录。
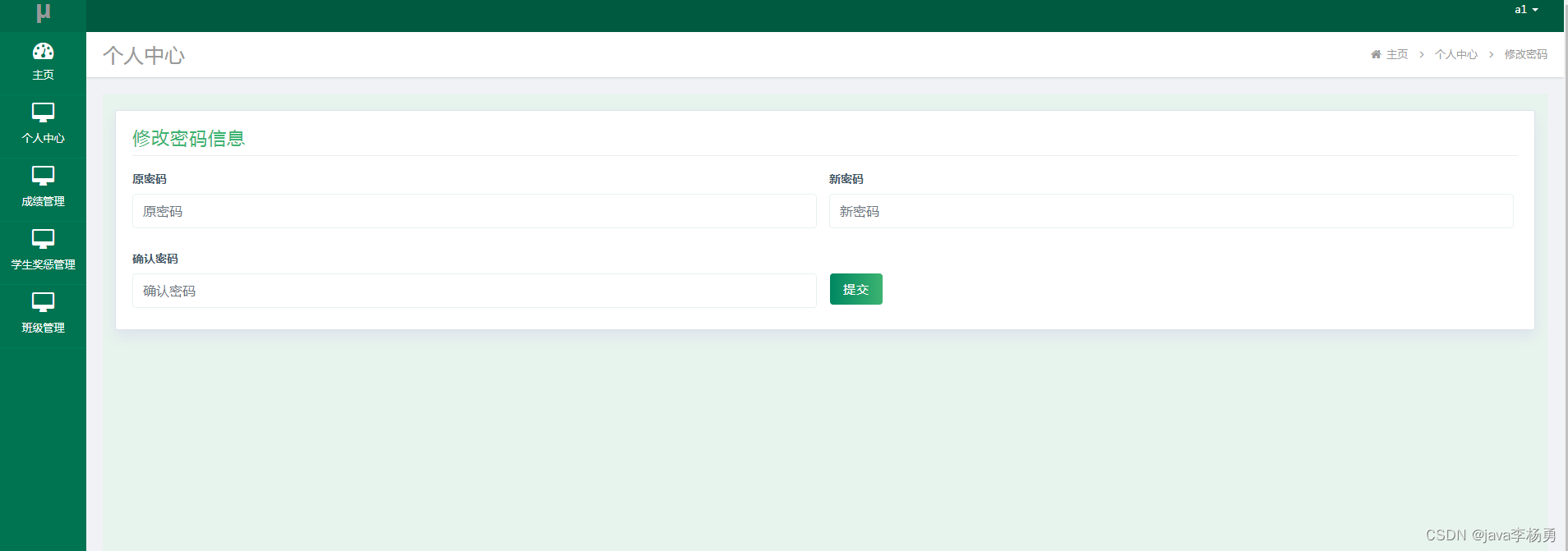
图5.9 修改密码页面
代码实现:
/*** 登录相关*/
@RequestMapping("users")
@RestController
public class UserController{@Autowiredprivate UserService userService;@Autowiredprivate TokenService tokenService;/*** 登录*/@IgnoreAuth@PostMapping(value = "/login")public R login(String username, String password, String role, HttpServletRequest request) {UserEntity user = userService.selectOne(new EntityWrapper<UserEntity>().eq("username", username));if(user != null){if(!user.getRole().equals(role)){return R.error("权限不正常");}if(user==null || !user.getPassword().equals(password)) {return R.error("账号或密码不正确");}String token = tokenService.generateToken(user.getId(),username, "users", user.getRole());return R.ok().put("token", token);}else{return R.error("账号或密码或权限不对");}}/*** 注册*/@IgnoreAuth@PostMapping(value = "/register")public R register(@RequestBody UserEntity user){
// ValidatorUtils.validateEntity(user);if(userService.selectOne(new EntityWrapper<UserEntity>().eq("username", user.getUsername())) !=null) {return R.error("用户已存在");}userService.insert(user);return R.ok();}/*** 退出*/@GetMapping(value = "logout")public R logout(HttpServletRequest request) {request.getSession().invalidate();return R.ok("退出成功");}/*** 密码重置*/@IgnoreAuth@RequestMapping(value = "/resetPass")public R resetPass(String username, HttpServletRequest request){UserEntity user = userService.selectOne(new EntityWrapper<UserEntity>().eq("username", username));if(user==null) {return R.error("账号不存在");}user.setPassword("123456");userService.update(user,null);return R.ok("密码已重置为:123456");}/*** 列表*/@RequestMapping("/page")public R page(@RequestParam Map<String, Object> params,UserEntity user){EntityWrapper<UserEntity> ew = new EntityWrapper<UserEntity>();PageUtils page = userService.queryPage(params, MPUtil.sort(MPUtil.between(MPUtil.allLike(ew, user), params), params));return R.ok().put("data", page);}/*** 信息*/@RequestMapping("/info/{id}")public R info(@PathVariable("id") String id){UserEntity user = userService.selectById(id);return R.ok().put("data", user);}/*** 获取用户的session用户信息*/@RequestMapping("/session")public R getCurrUser(HttpServletRequest request){Integer id = (Integer)request.getSession().getAttribute("userId");UserEntity user = userService.selectById(id);return R.ok().put("data", user);}/*** 保存*/@PostMapping("/save")public R save(@RequestBody UserEntity user){
// ValidatorUtils.validateEntity(user);if(userService.selectOne(new EntityWrapper<UserEntity>().eq("username", user.getUsername())) !=null) {return R.error("用户已存在");}userService.insert(user);return R.ok();}/*** 修改*/@RequestMapping("/update")public R update(@RequestBody UserEntity user){
// ValidatorUtils.validateEntity(user);userService.updateById(user);//全部更新return R.ok();}/*** 删除*/@RequestMapping("/delete")public R delete(@RequestBody Integer[] ids){userService.deleteBatchIds(Arrays.asList(ids));return R.ok();}
}
论文参考:
第1章 绪论1
1.1选题动因1
1.2目的和意义1
1.3论文结构安排2
第2章 开发环境与技术3
2.1 MYSQL数据库3
2.2 Tomcat 介绍3
2.3 JSP技术4
第3章 系统分析5
3.1可行性分析5
3.1.1操作可行性分析5
3.1.2经济可行性分析5
3.1.3技术可行性分析5
3.2系统流程分析6
3.3系统性能分析7
3.4系统功能分析8
第4章 系统设计11
4.1界面设计原则11
4.2功能结构设计11
4.3数据库设计14
4.3.1数据库概念设计15
4.3.2 数据库物理设计17
第5章 系统实现21
5.1管理员功能实现21
5.1.1班级和课程关系管理21
5.1.2老师管理21
5.1.3奖惩类型管理22
5.2 老师功能实现22
5.2.1成绩管理22
5.2.2学生奖惩管理23
5.2.3课程管理23
5.3 学生功能实现24
5.3.1班级管理24
5.3.2查询成绩24
5.3.3修改密码25
第6章 系统测试26
6.1 系统测试方法26
6.2 功能测试26
6.2.1 登录功能测试27
6.2.2 查询课程功能测试27
6.3 测试结果分析27
结 论28
参考文献30
致 谢31
获取源码:
大家 点赞、收藏、关注、评 论啦 、 查看 👇🏻 获取联系方式 👇🏻
精彩专栏 推荐订阅 :在 下方专栏 👇🏻
Java项目精品实战案例《100套》
Java微信小程序项目实战《100套》