做网站官网好处如何上传网站程序
🏆作者简介:|康有为| ,大四在读,目前在小米安卓实习,毕业入职
🏆本文收录于 安卓学习大全持续更新中,欢迎关注
🏆安卓学习资料推荐:
视频:b站搜动脑学院 视频链接 (他们的视频后面一部分没再更新,看看前面也挺好的)
书籍:《第一行代码》(第3版) by 郭霖 (z-lib.org)
思维导图: https://www.processon.com/view/link/62427cb2e0b34d0730e20e00(来自动脑学院)
目录
一、图形定制
图形Drawable
形状图形Shape
以下是一些关键属性:
案例示范
九宫格图片(.9.png)
状态列表图形
状态类型的取值说明
案例示范
selector中嵌套Shape
二、选择按钮
复选框CheckBox
开关按钮Switch
单选按钮Radio Button
三、文本输入和监听
编辑框EditText
焦点变更监听器
文本变化监听器
四、对话框
提醒对话框AlertDialog
日期对话框DatePickerDiaglog
时间对话框TimePickerDialog
一、图形定制
图形Drawable
在 Android 中,drawable 是一个资源文件夹,用于存放与图形相关的资源。这些资源可以是图像、形状、颜色等,用于构建应用的用户界面。drawable 目录下的资源可以通过资源 ID 在代码中或 XML 文件中引用。
Drawable类型表达了各种各样的图形,包括图片、色块、画板、背景等
包含图片在内的图形文件放在res目录的各个drawable目录下,其中drawable目录一般保存描述性的XML文件,而图片文件一般放在具体分辨率的drawable目录下。
各视图的background属性、ImageView 和ImageButton的src属性、TextView和Button四个方向的drawable***系列属性都可以引用图形文件。
13中Drawable的使用方法
详解Android 13种 Drawable的使用方法
谈谈Android的中的Drawable
形状图形Shape
在安卓中,通过XML定义的Shape Drawable,可以创建各种形状的图形,如矩形、圆角矩形、椭圆等。这些图形可以用作View的背景或作为其他Drawable的一部分。
这些是Shape Drawable中常见的一些属性,通过组合和调整这些属性,可以创建各种形状的Drawable。这些Drawable可以用作View的背景,也可以在其他地方使用,例如作为ImageView的源图像。
以下是一些关键属性:
1.形状(Shape):
<shape>元素定义了图形的类型。可以是"rectangle"(矩形)、"oval"(椭圆)、"line"(线)、"ring"(环)等。具体形状类型决定了其他属性的适用性。
<shape xmlns:android="http://schemas.android.com/apk/res/android"android:shape="rectangle"><!-- 其他属性 -->
</shape>
2.大小和尺寸(Size):
android:width和android:height属性定义了矩形或椭圆的宽度和高度,单位可以是像素(px)或者是尺寸单位(dp)。
<shape xmlns:android="http://schemas.android.com/apk/res/android"android:shape="rectangle"><sizeandroid:width="100dp"android:height="50dp"/>
</shape>
3.边框(Stroke):
android:width定义边框的宽度,android:color定义边框的颜色。
<shape xmlns:android="http://schemas.android.com/apk/res/android"android:shape="rectangle"><strokeandroid:width="2dp"android:color="#FF0000"/>
</shape>
4.圆角(Corners):
对于矩形,通过<corners>元素可以定义圆角。android:radius属性定义了圆角的半径。
<shape xmlns:android="http://schemas.android.com/apk/res/android"android:shape="rectangle"><corners android:radius="8dp"/>
</shape>
5.椭圆的宽高比(Gradient Ratio for Oval):
对于椭圆,可以通过<size>元素的android:aspectRatio属性定义宽高比。
<shape xmlns:android="http://schemas.android.com/apk/res/android"android:shape="oval"><sizeandroid:width="100dp"android:height="50dp"android:aspectRatio="1"/>
</shape>
6.填充(Solid)
可以填充内部的颜色
<shape xmlns:android="http://schemas.android.com/apk/res/android"android:shape="rectangle"><solid android:color="#FF0000"/>
</shape>
7.还有 间隔(padding)、渐变(gradient)、缩放(Scale)、旋转(Rotate)、形状重复(Gradient Radius)、形状颜色深度(Color Depth)等其他属性,这里不一一列举,用的时候可以自行搜索。
案例示范
需求:做一个页面,两个按钮能切换背景的图形。
|
|
|
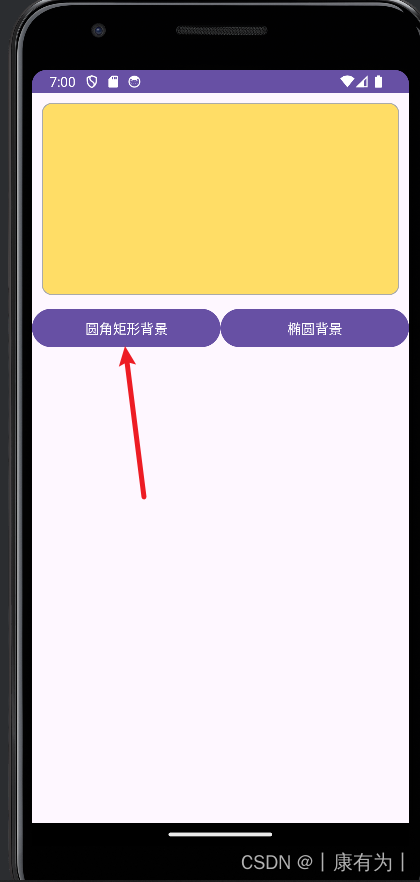
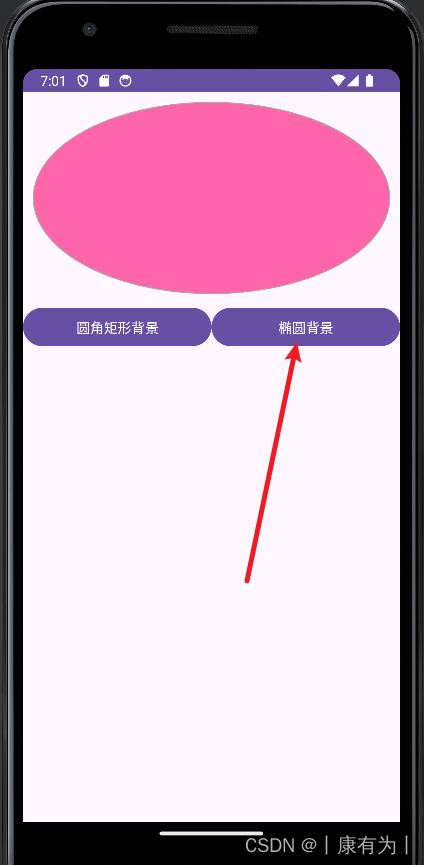
1.创建一个Activity,并写好布局文件
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"android:layout_width="match_parent"android:layout_height="match_parent"android:orientation="vertical"><Viewandroid:id="@+id/v_content"android:layout_width="match_parent"android:layout_height="200dp"android:layout_margin="10dp" /><LinearLayoutandroid:layout_width="match_parent"android:layout_height="wrap_content"android:orientation="horizontal"><Buttonandroid:id="@+id/btn_rect"android:layout_width="0dp"android:layout_height="wrap_content"android:layout_weight="1"android:text="圆角矩形背景" /><Buttonandroid:id="@+id/btn_oval"android:layout_width="0dp"android:layout_height="wrap_content"android:layout_weight="1"android:text="椭圆背景" /></LinearLayout></LinearLayout>
2.在res/drawable里面创建 一个圆角矩形的形状
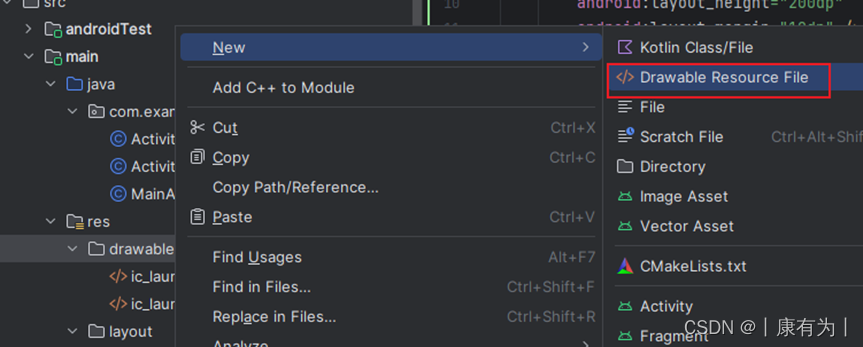
设定名字,并把根节点设置为shape
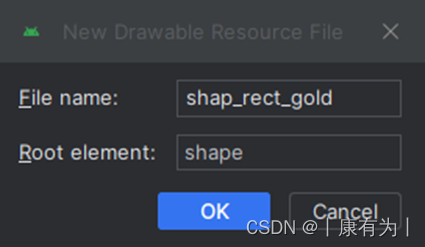
并设定好形状的信息,也能在旁边预览
<?xml version="1.0" encoding="utf-8"?>
<shape xmlns:android="http://schemas.android.com/apk/res/android"><!-- 指定了形状内部的填充颜色 --><solid android:color="#ffdd66" /><!-- 指定了形状轮廓的粗细与颜色 --><strokeandroid:width="1dp"android:color="#aaaaaa" /><!-- 指定了形状四个圆角的半径 --><corners android:radius="10dp" /></shape>
3.同样的方法,创建一个椭圆
名字可以设为:shape_oval_rose
<?xml version="1.0" encoding="utf-8"?>
<shape xmlns:android="http://schemas.android.com/apk/res/android"android:shape="oval"><!-- 指定了形状内部的填充颜色 --><solid android:color="#ff66aa" /><!-- 指定了形状轮廓的粗细与颜色 --><strokeandroid:width="1dp"android:color="#aaaaaa" /></shape>
4.现在我们想把这两个形状当成View的背景来用,并且点击按钮切换背景图片,就写Activity的java代码
public class ActivityA extends AppCompatActivity implements View.OnClickListener {private View v_content;@Overrideprotected void onCreate(Bundle savedInstanceState) {super.onCreate(savedInstanceState);setContentView(R.layout.activity_a);//用v_content绑定view背景v_content = findViewById(R.id.v_content);findViewById(R.id.btn_rect).setOnClickListener(this);findViewById(R.id.btn_oval).setOnClickListener(this);// v_content的背景默认设置为圆角矩形v_content.setBackgroundResource(R.drawable.shape_rect_gold);}//处理点击事件:哪个按钮点击了,就切换成对应得到形状@Overridepublic void onClick(View v) {int id = v.getId();if (id == R.id.btn_rect){v_content.setBackgroundResource(R.drawable.shape_rect_gold);return;}if (id == R.id.btn_oval){v_content.setBackgroundResource(R.drawable.shape_oval_rose);return;}}
}
九宫格图片(.9.png)
在安卓开发中,九宫格图片通常用于实现可伸缩的图形,以适应不同尺寸的屏幕或控件。这在处理图形元素,尤其是背景图或图标时非常有用。下面让我解释一下如何实现安卓中的九宫格图片:
NinePatch 图片:
- 九宫格图片是通过 NinePatch(.9.png) 图片格式来实现的。NinePatch 图片是一种特殊的 PNG 图片,它包含了额外的信息,指定了图片中哪些区域是可拉伸的,哪些区域是固定的。
工具:
- Android 提供了工具,如 draw9patch 工具,用于创建 NinePatch 图片。这个工具允许你在图像的边缘绘制黑色线条,以指示哪些区域是可伸缩的。
.9.png 图片结构:
- 一个 NinePatch 图片通常有一个可拉伸的中间区域,以及一些指示内容区域的黑线。这样,即使图片被拉伸,黑线的位置和大小也不会变化,保持了固定的区域。黑线的位置和大小可以通过 NinePatch 图片的文件名来指定。
使用 NinePatch 图片:
- 在布局文件中,你可以使用 <ImageView> 元素来显示 NinePatch 图片。将 NinePatch 图片放在 res/drawable 目录中,并使用 @drawable/your_ninepatch_image 引用它。
-
<ImageViewandroid:layout_width="wrap_content"android:layout_height="wrap_content"android:src="@drawable/your_ninepatch_image"/>统将根据屏幕尺寸和布局要求,自动拉伸和缩放 NinePatch 图片。
相关内容可以看
博客: Android 中关于九宫格图片的那些事
视频:2022 最新 Android 基础教程,从开发入门到项目实战,看它就够了,更新中 p49
状态列表图形
Button按钮的背景在正常情况下是凸起的,在按下时是凹陷的,从按下到弹起的过程,用户便能知道点击了这个按钮。
在安卓开发中,状态列表(State List)是一种定义不同状态下显示的图形资源的方式。状态列表图形通常用于按钮、选择器等 UI 元素,以根据不同的用户操作状态显示不同的图形。
一个状态列表可以包含以下不同的状态:
普通状态(state_enabled="true"):
默认状态,当用户没有与 UI 元素进行交互时显示的图形。
按下状态(state_pressed="true"):
当用户按下按钮时显示的图形。
选中状态(state_selected="true"):
当 UI 元素被选中时显示的图形,例如用于底部导航栏的图标。
焦点状态(state_focused="true"):
当 UI 元素获得焦点时显示的图形。
不可用状态(state_enabled="false"):
当 UI 元素不可用时显示的图形。
在定义状态列表时,你可以使用 <selector> 元素,其中包含了上述不同状态下的图形资源。以下是一个简单的例子:
<selector xmlns:android="http://schemas.android.com/apk/res/android"><!-- 按下状态:就用图片@drawable/button_pressed --><item android:state_pressed="true" android:drawable="@drawable/button_pressed"/><!-- 选中状态 --><item android:state_selected="true" android:drawable="@drawable/button_selected"/><!-- 不可用状态 --><item android:state_enabled="false" android:drawable="@drawable/button_disabled"/><!-- 默认状态,必须放在最后 --><item android:drawable="@drawable/button_normal"/>
</selector>然后在按钮中绑定这个背景xml即可
<Buttonandroid:layout_width="wrap_content"android:layout_height="wrap_content"android:background="@drawable/button_state_list"/>
状态类型的取值说明
状态列表图形不仅用于按钮控件,还可用于其他拥有多种状态的控件。
案例示范
1.准备两个按钮图片,一个是没点击状态的按钮,一个是按下状态的按钮,将下面两个按钮png图片放到
2.在res/drawable里面创建xml文件,也是选择New Drawable Resource File,根要选择selector,名字可以起button_state_list
<?xml version="1.0" encoding="utf-8"?>
<selector xmlns:android="http://schemas.android.com/apk/res/android"><!-- 按下状态:就用图片@drawable/button_pressed --><item android:state_pressed="true" android:drawable="@drawable/pressed"/><!-- 默认状态,必须放在最后 --><item android:drawable="@drawable/normal"/>
</selector>
3.创建一个Activity,在布局里面写上按钮,然后在按钮中绑定这个背景xml即可
<Buttonandroid:layout_width="wrap_content"android:layout_height="wrap_content"android:background="@drawable/button_state_list"/>
selector中嵌套Shape
<!-- res/drawable/edit_text_background.xml --><selector xmlns:android="http://schemas.android.com/apk/res/android"><!-- 默认状态 --><item android:state_focused="false"><shape android:shape="rectangle"><solid android:color="#CCCCCC" /> <!-- 灰色 --><corners android:radius="8dp" /> <!-- 圆角半径 --></shape></item><!-- 聚焦状态 --><item android:state_focused="true"><shape android:shape="oval"><solid android:color="#2196F3" /> <!-- 蓝色 --><!-- 高圆角值,使其成为椭圆形 --><corners android:radius="50dp" /></shape></item></selector>
相关文章:
Selector中嵌套Shape
二、选择按钮
复选框CheckBox
在 Android 中,复选框是一种常见的用户界面元素,允许用户选择或取消选择一个或多个选项。以下是使用复选框的基本概念和示例:
基本结构:
在 Android 中,使用 <CheckBox> 元素来创建复选框。以下是一个简单的示例:
<CheckBoxandroid:id="@+id/checkBox"android:layout_width="wrap_content"android:layout_height="wrap_content"android:text="选项"/>上述代码创建了一个标准的复选框,其中 android:text 属性定义了显示在复选框旁边的文本。
复选框监听事件:
你可以为复选框设置监听器,以便在用户更改选择状态时执行某些操作。例如:
JavaCheckBox checkBox = findViewById(R.id.checkBox);checkBox.setOnCheckedChangeListener(new CompoundButton.OnCheckedChangeListener() {@Overridepublic void onCheckedChanged(CompoundButton buttonView, boolean isChecked) {if (isChecked) {// 复选框被选中时的操作} else {// 复选框取消选中时的操作}}
});获取和设置状态:
你可以通过 isChecked() 方法来获取复选框的当前状态,并使用 setChecked() 方法来设置复选框的状态。例如:
CheckBox checkBox = findViewById(R.id.checkBox);// 获取状态
boolean isChecked = checkBox.isChecked();// 设置状态
checkBox.setChecked(true); // 选中
checkBox.setChecked(false); // 取消选中多选:
如果你希望用户能够选择多个选项,可以使用 android:checkable 属性或者在代码中设置 setCheckable(true)。
<CheckBoxandroid:id="@+id/checkbox1"android:layout_width="wrap_content"android:layout_height="wrap_content"android:text="选项1"android:checkable="true"/>或者在代码中:
CheckBox checkBox = findViewById(R.id.checkbox1);
checkBox.setCheckable(true);使用复选框的场景:
- 多选设置: 允许用户在一组选项中进行多选。
- 接受条款和条件: 例如,在注册或登录界面中,用户需要勾选复选框以接受服务条款。
- 筛选: 在某些应用中,用户可以使用复选框来筛选或过滤数据。
复选框是 Android 用户界面设计中的常见元素,可以通过简单的 XML 属性或者在代码中进行设置,以适应不同的需求。
开关按钮Switch
Switch是安卓界面中常见的用户界面元素之一,用于在两种状态(开和关)之间切换。以下是一些关于安卓开发中Switch控件的基本信息:
XML布局中的使用: 在XML布局文件中,你可以使用<Switch>标签定义Switch控件。例如:
<Switchandroid:id="@+id/switchButton"android:layout_width="wrap_content"android:layout_height="wrap_content"android:text="Switch"android:checked="true" />在Java代码中的操作: 在Java代码中,你可以通过找到Switch控件的引用,然后设置监听器或直接操作状态来响应用户的操作。例如:
Switch switchButton = findViewById(R.id.switchButton);switchButton.setOnCheckedChangeListener(new CompoundButton.OnCheckedChangeListener() {@Overridepublic void onCheckedChanged(CompoundButton buttonView, boolean isChecked) {// 处理Switch状态变化if (isChecked) {// Switch打开} else {// Switch关闭}}
});
- 自定义样式和属性: Switch控件支持自定义样式和属性,你可以通过设置不同的属性来调整Switch的外观和行为,如颜色、大小、文字等。
- 状态切换动画: Switch控件在状态切换时可以显示平滑的过渡动画,提升用户体验。
- 使用场景: Switch控件通常用于需要在两种状态之间切换的设置项,比如开启或关闭某个功能、选中或取消选中某个选项等。
在安卓开发中,Switch控件是一种简单而强大的用户界面元素,方便开发者实现各种切换功能的交互效果。
单选按钮Radio Button
在安卓开发中,单选按钮(Radio Button)是一种常见的用户界面元素,用于允许用户从一组互斥的选项中选择一个。以下是有关安卓中单选按钮的基本信息:
XML布局中的使用: 在XML布局文件中,你可以使用<RadioButton>标签定义单选按钮。通常,单选按钮会与RadioGroup组合使用,确保在同一组中只有一个按钮被选中。RadioGroup 中也能规定RadioButton 的布局是竖直还是水平。 例如:
<RadioGroupandroid:id="@+id/radioGroup"android:layout_width="wrap_content"android:layout_height="wrap_content"android:orientation="horizontal"><RadioButtonandroid:id="@+id/radioButton1"android:layout_width="wrap_content"android:layout_height="wrap_content"android:text="男性" /><RadioButtonandroid:id="@+id/radioButton2"android:layout_width="wrap_content"android:layout_height="wrap_content"android:text="女性" /><!-- 可以添加更多的RadioButton --></RadioGroup>
在Java代码中的操作: 通过在Java代码中找到RadioGroup的引用,你可以监听单选按钮的选择事件,并根据需要执行相应的操作。例如:
RadioGroup radioGroup = findViewById(R.id.radioGroup);radioGroup.setOnCheckedChangeListener(new RadioGroup.OnCheckedChangeListener() {@Overridepublic void onCheckedChanged(RadioGroup group, int checkedId) {// 获取选中的RadioButton的IDRadioButton selectedRadioButton = findViewById(checkedId);// 处理选中的RadioButtonString selectedText = selectedRadioButton.getText().toString();// 可以根据选中的单选按钮执行相应的逻辑if ("男性".equals(selectedText)) {//...} else if ("女性".equals(selectedText)) {//...}// 也可以使用 switch 语句进行处理/*switch (selectedText) {case "Option 1":// 执行与"Option 1"相关的逻辑break;case "Option 2":// 执行与"Option 2"相关的逻辑break;}*/// 也可以根据选中的单选按钮的ID执行相应的逻辑/*if (checkedId == R.id.radioButton1) {} else if (checkedId == R.id.radioButton2) {} else {}*/}
});
- 属性设置: 单选按钮支持一系列的属性设置,包括文本、颜色、样式等。你可以在XML布局文件或通过Java代码设置这些属性,以满足设计和功能的需求。
- 组合使用: 单选按钮通常会和其他视图组合使用,比如在表单中,用户需要从多个选项中选择一个。在这种情况下,将多个单选按钮放在同一组(同一个RadioGroup)中可以确保它们是互斥的。
- 样式和主题: 单选按钮的外观可以通过样式和主题进行自定义,以适应应用程序的整体风格。
- java代码中常用的方法
-
下面是RadioGroup在Java代码中的3个常用方法。
- check:选中指定资源编号的单选按钮。
- getCheckedRadioButtonld:获取已选中单选按钮的资源编号。
- setOnCheckedChangeListener:设置单选按钮勾选变化的监听器。
-
三、文本输入和监听
编辑框EditText
EditText 是 Android 开发中常用的用户界面元素之一,它用于允许用户在应用程序中输入文本。以下是一些关于 EditText 的基本信息:
1.XML 布局中的使用: 在 XML 布局文件中,你可以使用 <EditText> 标签定义 EditText。以下是一个简单的示例:
<EditTextandroid:id="@+id/editText"android:layout_width="match_parent"android:layout_height="wrap_content"android:hint="请输入文本"android:inputType="text" />- android:id:指定 EditText 的唯一标识符。
- android:layout_width 和 android:layout_height:指定宽度和高度。
- android:hint:设置在用户未输入文本时显示的提示信息。
- android:inputType:指定输入类型,例如 text, number, email 等。
2.在 Java 代码中的操作: 通过在 Java 代码中找到 EditText 的引用,你可以对其进行各种操作,如获取用户输入、设置文本、监听文本变化等。以下是一个简单的例子:
EditText editText = findViewById(R.id.editText);// 获取用户输入的文本
String userInput = editText.getText().toString();// 设置文本
editText.setText("新的文本");// 监听文本变化
editText.addTextChangedListener(new TextWatcher() {@Overridepublic void beforeTextChanged(CharSequence charSequence, int start, int before, int count) {// 在文本变化之前的操作}@Overridepublic void onTextChanged(CharSequence charSequence, int start, int before, int count) {// 在文本变化时的操作}@Overridepublic void afterTextChanged(Editable editable) {// 在文本变化之后的操作}
});
3.属性和方法: EditText 具有丰富的属性和方法,允许你自定义其外观和行为。例如,你可以使用 android:maxLength 属性限制用户输入的字符数,或者使用 setInputType() 方法指定输入类型。
4.输入类型(InputType): 通过设置 android:inputType 或 setInputType(),你可以指定输入类型,例如文本、数字、密码等。这有助于限制用户输入的内容。
<EditTextandroid:id="@+id/passwordEditText"android:layout_width="match_parent"android:layout_height="wrap_content"android:hint="请输入密码"android:inputType="textPassword" />
5.样式和主题: EditText 可以通过应用样式和主题来自定义其外观。你可以使用 XML 的样式属性或在代码中动态设置样式。
总体而言,EditText 是 Android 开发中用于接受用户输入文本的重要控件。通过合理设置属性和监听器,你可以实现各种用户输入场景的处理
焦点变更监听器
调用编辑框对象的setOnFocusChangeListener方法,即可在光标切换时触发焦点变更事件。
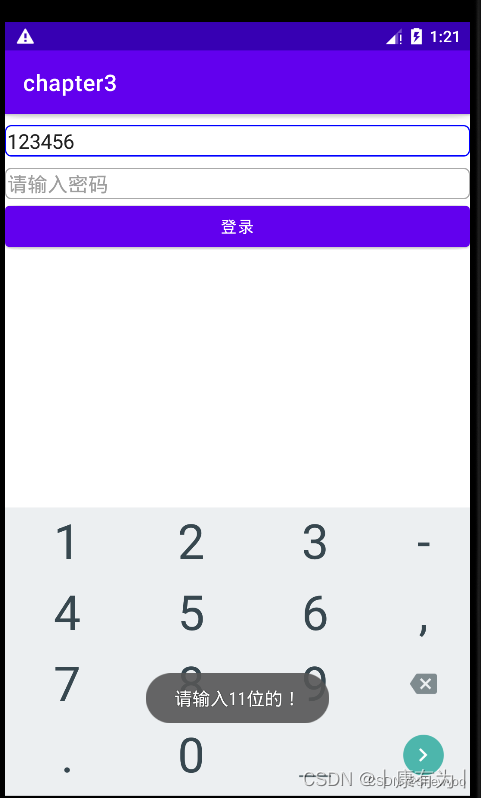
使用场景如:手机号码未输满11位,就点击密码框,此时校验不通过,一边弹出提示文字,一边把焦点拉回手机框。
例:当手机号码不足11位时点击密码框会出现提示。
注意:不可采取这样的方式:为密码框绑定点击事件,当点击密码框时检测是否通过。
原因:编辑框点击两次后才会触发点击事件,第一次点击只触发焦点变更事件,第二次点击才触发点击事件。
Xml
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"android:layout_width="match_parent"android:layout_height="match_parent"android:orientation="vertical"><EditTextandroid:id="@+id/et_phone"android:layout_width="match_parent"android:layout_height="wrap_content"android:background="@drawable/edit_text"android:layout_marginTop="10dp"android:hint="请输入11位手机号码"android:inputType="number"android:maxLength="11"/><EditTextandroid:id="@+id/et_password"android:layout_width="match_parent"android:layout_height="wrap_content"android:background="@drawable/edit_text"android:layout_marginTop="10dp"android:hint="请输入密码"android:inputType="numberPassword"android:maxLength="11"/><Buttonandroid:id="@+id/btn_login"android:layout_width="match_parent"android:layout_height="wrap_content"android:text="登录"/></LinearLayout>
Java
public class EditFocusActivity extends AppCompatActivity implements View.OnFocusChangeListener {private EditText et_phone;@Overrideprotected void onCreate(Bundle savedInstanceState) {super.onCreate(savedInstanceState);setContentView(R.layout.activity_edit_focus);et_phone = findViewById(R.id.et_phone);EditText et_password = findViewById(R.id.et_password);et_password.setOnFocusChangeListener(this);}@Overridepublic void onFocusChange(View view, boolean hasFocus) {if(hasFocus){String phone = et_phone.getText().toString();//如果手机号码不足11位或为空if(TextUtils.isEmpty(phone)||phone.length()<11){//手机号码编辑框请求焦点,把光标移回手机号码编辑框et_phone.requestFocus();Toast.makeText(this,"请输入11位的!",Toast.LENGTH_SHORT).show();}}}
}
文本变化监听器
需求:输入11位号码后,自动把键盘收起来
这个就需要监听文本的变化
方法:在文本变化时,监听它长度有没有11位
在 Java 代码中的操作: 通过在 Java 代码中找到 EditText 的引用,你可以对其进行各种操作,如获取用户输入、设置文本、监听文本变化等。以下是一个简单的例子:
public class ActivityA extends AppCompatActivity {private EditText editText;@Overrideprotected void onCreate(Bundle savedInstanceState) {super.onCreate(savedInstanceState);setContentView(R.layout.activity_a);editText = findViewById(R.id.editText);editText.addTextChangedListener(new TextWatcher() {@Overridepublic void beforeTextChanged(CharSequence charSequence, int i, int i1, int i2) {// 在文本变化前的操作}@Overridepublic void onTextChanged(CharSequence charSequence, int i, int i1, int i2) {// 在文本变化时的操作String input = charSequence.toString().trim();if (input.length() == 11) {// 输入11位时,隐藏键盘hideKeyboard();}}@Overridepublic void afterTextChanged(Editable editable) {// 在文本变化后的操作}});}// 隐藏键盘的方法private void hideKeyboard() {InputMethodManager imm = (InputMethodManager) getSystemService(Context.INPUT_METHOD_SERVICE);imm.hideSoftInputFromWindow(editText.getWindowToken(), 0);}
}
四、对话框
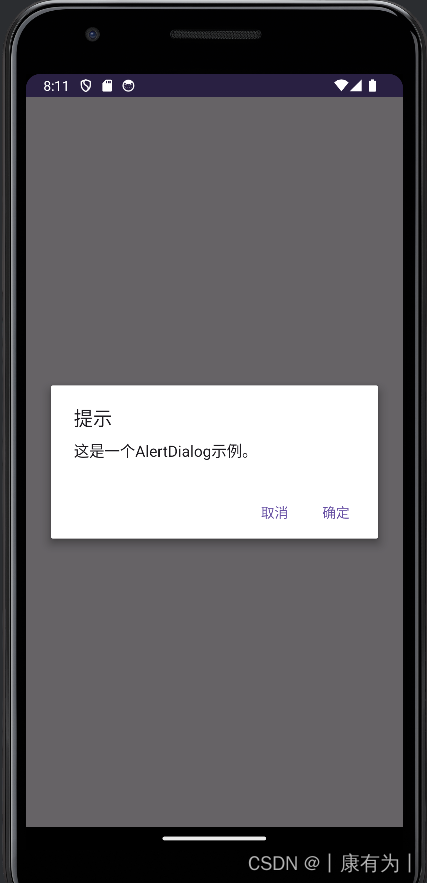
提醒对话框AlertDialog
AlertDialog 是 Android 中常用的对话框(Dialog)之一,用于显示一些消息、接受用户输入或确认用户的操作。
以下是一个简单的示例,演示如何创建一个简单的 AlertDialog:
<?xml version="1.0" encoding="utf-8"?>
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"xmlns:tools="http://schemas.android.com/tools"android:layout_width="match_parent"android:layout_height="match_parent"tools:context=".MainActivity"><Buttonandroid:id="@+id/showAlertButton"android:layout_width="wrap_content"android:layout_height="wrap_content"android:text="显示对话框"android:layout_centerInParent="true" /></RelativeLayout>
import android.app.AlertDialog;
import android.content.DialogInterface;
import android.os.Bundle;
import android.view.View;
import android.widget.Button;import androidx.appcompat.app.AppCompatActivity;public class MainActivity extends AppCompatActivity {@Overrideprotected void onCreate(Bundle savedInstanceState) {super.onCreate(savedInstanceState);setContentView(R.layout.activity_main);Button showAlertButton = findViewById(R.id.showAlertButton);showAlertButton.setOnClickListener(new View.OnClickListener() {@Overridepublic void onClick(View view) {showAlertDialog();}});}private void showAlertDialog() {AlertDialog.Builder builder = new AlertDialog.Builder(this);// 设置对话框标题builder.setTitle("提示");// 设置对话框消息builder.setMessage("这是一个AlertDialog示例。");// 设置对话框按钮builder.setPositiveButton("确定", new DialogInterface.OnClickListener() {@Overridepublic void onClick(DialogInterface dialogInterface, int i) {// 用户点击确定按钮后的操作}});// 设置对话框取消按钮builder.setNegativeButton("取消", new DialogInterface.OnClickListener() {@Overridepublic void onClick(DialogInterface dialogInterface, int i) {// 用户点击取消按钮后的操作}});// 创建并显示对话框AlertDialog alertDialog = builder.create();alertDialog.show();}
}|
|
|
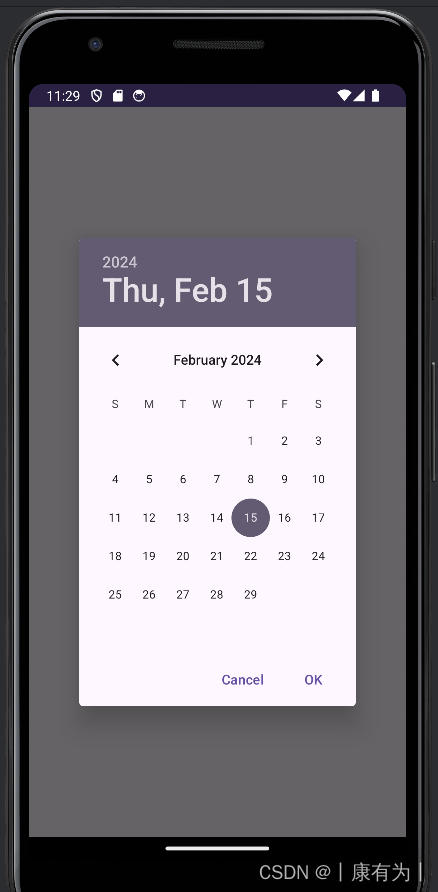
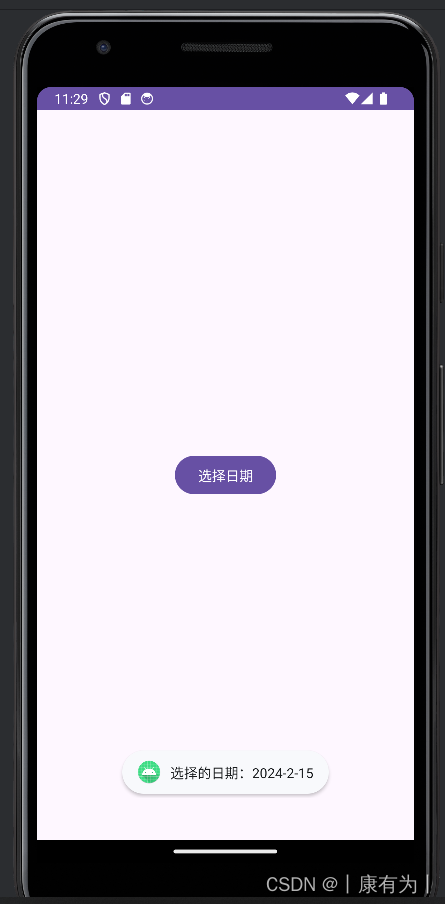
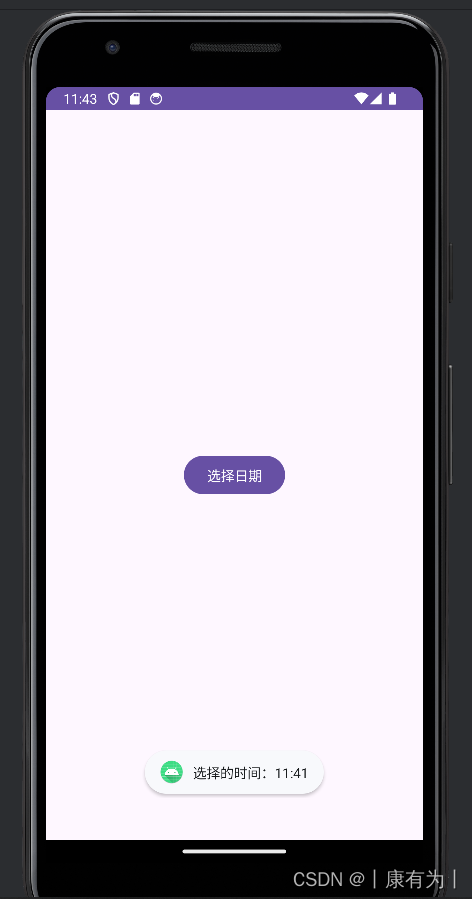
日期对话框DatePickerDiaglog
DatePickerDialog 是 Android 中用于选择日期的对话框。以下是一个简单的示例,演示如何在 Android 中使用 DatePickerDialog:
<?xml version="1.0" encoding="utf-8"?>
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"xmlns:tools="http://schemas.android.com/tools"android:layout_width="match_parent"android:layout_height="match_parent"tools:context=".MainActivity"><Buttonandroid:id="@+id/showDatePickerButton"android:layout_width="wrap_content"android:layout_height="wrap_content"android:text="选择日期"android:layout_centerInParent="true" /></RelativeLayout>
import android.app.DatePickerDialog;
import android.os.Bundle;
import android.view.View;
import android.widget.Button;
import android.widget.DatePicker;
import android.widget.Toast;import androidx.appcompat.app.AppCompatActivity;import java.util.Calendar;public class MainActivity extends AppCompatActivity {@Overrideprotected void onCreate(Bundle savedInstanceState) {super.onCreate(savedInstanceState);setContentView(R.layout.activity_main);Button showDatePickerButton = findViewById(R.id.showDatePickerButton);showDatePickerButton.setOnClickListener(new View.OnClickListener() {@Overridepublic void onClick(View view) {showDatePicker();}});}private void showDatePicker() {// 获取当前日期final Calendar calendar = Calendar.getInstance();int year = calendar.get(Calendar.YEAR);int month = calendar.get(Calendar.MONTH);int day = calendar.get(Calendar.DAY_OF_MONTH);// 创建 DatePickerDialog 对象DatePickerDialog datePickerDialog = new DatePickerDialog(this,new DatePickerDialog.OnDateSetListener() {@Overridepublic void onDateSet(DatePicker view, int selectedYear, int selectedMonth, int selectedDay) {// 用户选择日期后的操作String selectedDate = selectedYear + "-" + (selectedMonth + 1) + "-" + selectedDay;Toast.makeText(MainActivity.this, "选择的日期:" + selectedDate, Toast.LENGTH_SHORT).show();}},year,month,day);// 显示 DatePickerDialogdatePickerDialog.show();}
}在这个示例中,activity_main.xml 包含一个按钮,点击该按钮会触发 showDatePicker 方法,显示一个包含当前日期的 DatePickerDialog。用户选择日期后,通过 OnDateSetListener 监听器获取用户选择的日期并显示在 Toast 中。
注意:月份那里要加1,它这里是0-11,我们用的月份是1-12月,所以:selectedMonth + 1
你可以根据需要调整日期选择的初始值、监听器的逻辑等。这只是一个简单的示例,供你了解如何使用 DatePickerDialog。
|
|
|
在 Android 12 及更高版本,DatePicker 也引入了 datePickerMode 属性,用于切换日期选择的模式。这个属性可以设置为 "calendar" 表示日历模式,或 "spinner" 表示下拉框模式。
以下是一个使用 XML 设置 DatePicker 样式的示例:
<?xml version="1.0" encoding="utf-8"?>
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"xmlns:tools="http://schemas.android.com/tools"android:layout_width="match_parent"android:layout_height="match_parent"tools:context=".MainActivity"><DatePickerandroid:id="@+id/datePicker"android:layout_width="wrap_content"android:layout_height="wrap_content"android:layout_centerInParent="true"android:datePickerMode="calendar" /><Buttonandroid:id="@+id/showDateButton"android:layout_width="wrap_content"android:layout_height="wrap_content"android:text="显示日期"android:layout_below="@id/datePicker"android:layout_centerHorizontal="true"android:layout_marginTop="16dp" /></RelativeLayout>
import android.os.Build;
import android.os.Bundle;
import android.view.View;
import android.widget.Button;
import android.widget.DatePicker;
import android.widget.Toast;import androidx.annotation.RequiresApi;
import androidx.appcompat.app.AppCompatActivity;public class MainActivity extends AppCompatActivity {@Overrideprotected void onCreate(Bundle savedInstanceState) {super.onCreate(savedInstanceState);setContentView(R.layout.activity_main);Button showDateButton = findViewById(R.id.showDateButton);showDateButton.setOnClickListener(new View.OnClickListener() {@Overridepublic void onClick(View view) {showSelectedDate();}});}@RequiresApi(api = Build.VERSION_CODES.O)private void showSelectedDate() {DatePicker datePicker = findViewById(R.id.datePicker);int year, month, dayOfMonth;if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.O) {year = datePicker.getYear();month = datePicker.getMonth();dayOfMonth = datePicker.getDayOfMonth();} else {// 在 Android 12 以下版本,没有直接提供获取日期的方法,可以通过反射获取// 这里仅为演示,实际使用时请注意处理兼容性问题try {java.lang.reflect.Field field = datePicker.getClass().getDeclaredField("mYearSpinner");field.setAccessible(true);year = (int) field.get(datePicker);field = datePicker.getClass().getDeclaredField("mMonthSpinner");field.setAccessible(true);month = (int) field.get(datePicker);field = datePicker.getClass().getDeclaredField("mDaySpinner");field.setAccessible(true);dayOfMonth = (int) field.get(datePicker);} catch (Exception e) {e.printStackTrace();return;}}String selectedDate = year + "-" + (month + 1) + "-" + dayOfMonth;Toast.makeText(this, "选择的日期:" + selectedDate, Toast.LENGTH_SHORT).show();}
}时间对话框TimePickerDialog
如果你想要实现时间选择对话框,你可以使用 TimePickerDialog。以下是一个简单的示例代码,演示如何在 Android 中使用 TimePickerDialog:
<?xml version="1.0" encoding="utf-8"?>
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"xmlns:tools="http://schemas.android.com/tools"android:layout_width="match_parent"android:layout_height="match_parent"tools:context=".MainActivity"><Buttonandroid:id="@+id/showTimePickerButton"android:layout_width="wrap_content"android:layout_height="wrap_content"android:text="选择时间"android:layout_centerInParent="true" /></RelativeLayout>
import android.app.TimePickerDialog;
import android.os.Bundle;
import android.view.View;
import android.widget.Button;
import android.widget.TimePicker;
import android.widget.Toast;import androidx.appcompat.app.AppCompatActivity;import java.util.Calendar;public class MainActivity extends AppCompatActivity {@Overrideprotected void onCreate(Bundle savedInstanceState) {super.onCreate(savedInstanceState);setContentView(R.layout.activity_main);Button showTimePickerButton = findViewById(R.id.showTimePickerButton);showTimePickerButton.setOnClickListener(new View.OnClickListener() {@Overridepublic void onClick(View view) {showTimePicker();}});}private void showTimePicker() {// 获取当前时间final Calendar calendar = Calendar.getInstance();int hour = calendar.get(Calendar.HOUR_OF_DAY);int minute = calendar.get(Calendar.MINUTE);// 创建 TimePickerDialog 对象TimePickerDialog timePickerDialog = new TimePickerDialog(this,new TimePickerDialog.OnTimeSetListener() {@Overridepublic void onTimeSet(TimePicker timePicker, int selectedHour, int selectedMinute) {// 用户选择时间后的操作String selectedTime = selectedHour + ":" + selectedMinute;Toast.makeText(MainActivity.this, "选择的时间:" + selectedTime, Toast.LENGTH_SHORT).show();}},hour,minute,true // 是否显示 24 小时制);// 显示 TimePickerDialogtimePickerDialog.show();}
}在这个示例中,activity_main.xml 包含一个按钮,点击该按钮会触发 showTimePicker 方法,显示一个包含当前时间的 TimePickerDialog。用户选择时间后,通过 OnTimeSetListener 监听器获取用户选择的时间并显示在 Toast 中。
|
|
|
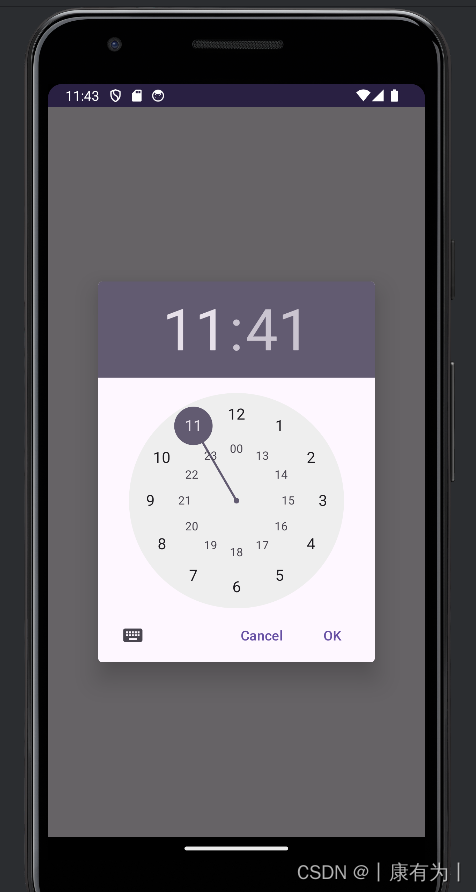
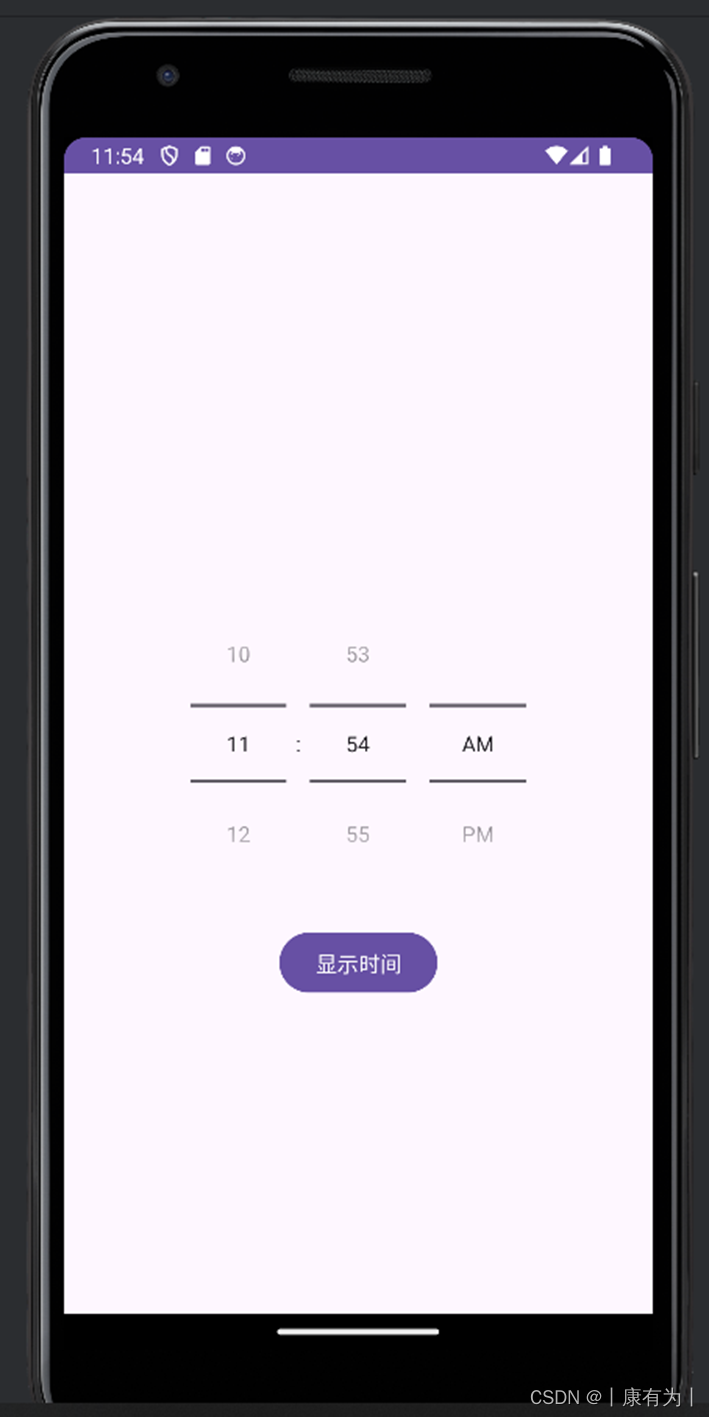
在 Android 12 及更高版本中,引入了 TimePicker 的 timePickerMode 属性,可以用于切换时钟模式。
在 XML 文件中直接设置 TimePicker 的样式需要使用 android:timePickerMode 属性。这个属性是在 Android 12 及更高版本引入的,用于设置 TimePicker 的模式。可以设置为 "clock" 表示时钟模式,或 "spinner" 表示下拉框模式。
以下是一个使用 XML 设置 TimePicker 样式的示例:
<?xml version="1.0" encoding="utf-8"?>
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"xmlns:tools="http://schemas.android.com/tools"android:layout_width="match_parent"android:layout_height="match_parent"tools:context=".MainActivity"><TimePickerandroid:id="@+id/timePicker"android:layout_width="wrap_content"android:layout_height="wrap_content"android:layout_centerInParent="true"android:timePickerMode="clock" /><Buttonandroid:id="@+id/showTimeButton"android:layout_width="wrap_content"android:layout_height="wrap_content"android:text="显示时间"android:layout_below="@id/timePicker"android:layout_centerHorizontal="true"android:layout_marginTop="16dp" /></RelativeLayout>
import android.os.Build;
import android.os.Bundle;
import android.view.View;
import android.widget.Button;
import android.widget.TimePicker;
import android.widget.Toast;import androidx.annotation.RequiresApi;
import androidx.appcompat.app.AppCompatActivity;public class MainActivity extends AppCompatActivity {@Overrideprotected void onCreate(Bundle savedInstanceState) {super.onCreate(savedInstanceState);setContentView(R.layout.activity_main);Button showTimeButton = findViewById(R.id.showTimeButton);showTimeButton.setOnClickListener(new View.OnClickListener() {@Overridepublic void onClick(View view) {showSelectedTime();}});}@RequiresApi(api = Build.VERSION_CODES.M)private void showSelectedTime() {TimePicker timePicker = findViewById(R.id.timePicker);int hour, minute;if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.M) {hour = timePicker.getHour();minute = timePicker.getMinute();} else {hour = timePicker.getCurrentHour();minute = timePicker.getCurrentMinute();}String selectedTime = hour + ":" + minute;Toast.makeText(this, "选择的时间:" + selectedTime, Toast.LENGTH_SHORT).show();}
}spanner模式的