为什么要建设商城网站好网站推荐几个你知道的
Vue 中最大的一个特征就是数据的双向绑定,而这种双向绑定的形式,一方面表现在元数据与衍生数据之间的响应,另一方面表现在元数据与视图之间的响应,而这些响应的实现方式,依赖的是数据链,因此,要了解数据绑定的原理,先要理解下面两方面内容。
一、 Vue中数据链
所谓数据链,它是一种数据关联的形式,在这种形式中,有一到多个的起始数据点,称之为元数据,而由这些元数据因某种关系衍生出的数据,称之为衍生数据,元数据与衍生数据通过数据节点交织在一起,形成数据结构网,而这种结构网,我们称之为数据链。

在Vue 中,当数据链中的元数据变化时,与其关联的衍生数据,通过数据链,完成同步更新,实现数据双向绑定的效果;在Vue 实例化对象中,computed选项值,可以为开发人员生成衍生对象,当元数据变化时,生成的衍生对象将会同步更新。
实例: 使用衍生数据显示“张三,你好!”
1. 功能描述
新建一个名称为SayHello.vue的组件,在返回的数据对象中,添加一项名称为“name”的属性,初始值为“张三”,同时,在computed配置选项中,添加一个名为sayHelloName的函数,在函数中返回“张三,你好!”,并在页面中执行该函数。
2. 实现代码
在项目的components 文件夹中,新建一个名称为“ch3”的子文件夹,在这个子文件夹中,添加一个名为“SayHello”的.vue文件,在文件中加入如清单所示代码。
代码清单 SayHello.vue代码
<template><div><div>{{ name }}</div><div>{{ sayHelloName }}</div></div>
</template>
<script>
export default {data() {return {name: "张三",};},computed: {sayHelloName() {return this.name + ",你好!";}},
};
</script>
<style scoped>
div {margin: 10px;text-align: left;
}
</style>SayHello.vue文件是一个独立的组件,需要将它导入到根组件App.vue中,并声明该组件,最后,在模板中以标签形式应用该组件,因此,App.vue文件修改后的代码,如下列代码清单所示。
<template><SayHello />
</template><script>
import SayHello from "./components/ch3/SayHello.vue";export default {name: "App",components: {SayHello}
};
</script><style>
...省略样式代码
</style>3.页面效果
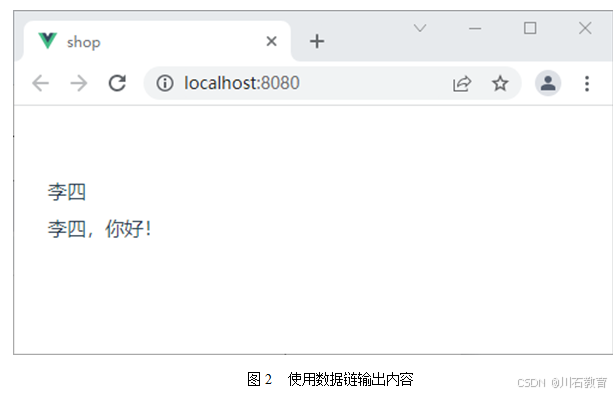
保存代码后,页面在Chrome浏览器下执行的页面效果如图下图所示。
4. 源码分析
在Vue 实例化配置对象中,computed选项中可以生成衍生数据,生成过程由函数来完成,该函数不接收参数,在函数体中,由于this指向实例化的Vue 对象,因此,它可以访问所有实例化对象中挂载的属性值,如this.name,表示元数据值。
此外,computed选项中的函数,虽然可以访问实例化对象中挂载的全部属性值,但它在函数中,必须使用return 语句,返回计算或衍生后的数据,通过这种形式,才可以在模板中使用双大括号方式执行函数,接收并显示返回的数据。
因此,示例中的sayHelloName函数中,先获取元数据name值,并添加“,你好!”形成一个衍生数据,同时,作用函数的返回值;当在模板中,调用该函数时,则直接将接收到的衍生数据显示在页面中,由于是衍生数据,当元数所变化时,将会通过数据链形式,同步衍生数据,因此,衍生数据也会同步更新。即修改name值为“李四”时,页面将直接显示“李四,你好!”的字样。