vps如何搭建网站网站前台后台模板下载
前言
本人是算法小白,甚至也没有做过Leetcode。所以,我相信【同为菜鸡的我更能理解作为菜鸡的你们的痛点】。
题干
OD,B 卷 100 分题目【OD 统一考试(B 卷)】
1. 题目描述
某长方形停车场每个车位上方都有一个监控器,只有当当前车位或者前后左右四个方向任意一个车位范围停有车时,监控器才需要打开。给定某一时刻停车场的停车分布,请统计最少需要打开多少个监控器。
2. 输入描述
第一行输入m和n,表示停车场的长和宽。满足条件1 < m, n <= 20。
接下来的m行,每行包含n个整数(0或1),表示该行停车位的情况。其中0表示空位,1表示已停车。
3. 输出描述
输出最少需要打开的监控器数量
4. 示例
示例一:
输入:
3 3
0 0 0
0 1 0
0 0 0
输出:
5
示例二:
输入:
3 3
1 0 0
0 1 0
0 0 0
输出:
6
解答
遇到的问题
说实在,我刚看到题干的时候是有点懵的,有点读不清楚题目的意思。接着我看了【示例】的输入输出之后,更加懵逼了。就算看了答案,我还是不知所云。后面拿着题干去百度,再反复思考,才理清了其中缘由,哎,其实是我自己想复杂了(有点挫败)。
我自己反思了一下,为什么我会读不清楚题目意思:
- 我当时读原题的时候,脑子不自觉就浮现出了停车场模型
- 我看原题的时候,那个博主也给了一张停车场鸟瞰图,加深了我的”刻板印象“。看着这张图,我一下子理解不了【每个车位上方都有一个监控器】的意思了(我哭死)
- 第一次接触机考,所以我不懂得结合输入、输出描述去理解题干

解题思路
大家抛开对停车场的固有印象,也不要去看上面那张鸟瞰图,就用最原始的【面向过程】的想法去看题目。通过读题干,我们可以得到以下条件:
- 停车场是长方形的,并且长、宽的限制为
1 < m, n <= 20(那不就是一个二维数组嘛) - 每个车位上方都有一个监控器(所以,整个停车场总共有
m * n个监控器) - 监控需要打开的条件:【当前停车位有车】或者【前后左右至少有一辆车】时
代码示例
public class StatisticalMonitors {/*** m、n的范围。 1< m,n <= 20*/static final int MAX_COUNT = 20 + 1 + 1;/*** 【前、后、左、右】的坐标变化量* 用来索引当前节点【前、后、左、右】的目标位置*/static final int AROUND[][] = {{1, 0}, {-1, 0}, {0, -1}, {0, 1}};public static void main(String[] args) {int row = 0, column = 0;int[][] parkingLot = new int[MAX_COUNT][MAX_COUNT];// 读入数据Scanner scanner = new Scanner(System.in);row = scanner.nextInt();column = scanner.nextInt();for (int r = 1; r <= row; r++) {for (int c = 1; c <= column; c++) {parkingLot[r][c] = scanner.nextInt();}}// 统计数量int monitorCount = 0;for (int r = 1; r <= row; r++) {for (int c = 1; c <= column; c++) {// 当前节点有车,直接返回int status = parkingLot[r][c];if (status == 1) {monitorCount++;continue;}// 没车,看看四周boolean b = checkAround(parkingLot, r, c);if (b) {monitorCount++;}}}System.out.println("停车场至少需要的监控数目:" + monitorCount);}/*** 检查当前四周(前、后、左、右)有没有车停靠** @return true-有车;false-没有车*/private static boolean checkAround(int[][] parkingLot, int curRow, int curColumn) {for (int[] ints : AROUND) {int newRow = curRow + ints[0];int newColumn = curColumn + ints[1];int status = parkingLot[newRow][newColumn];if (status == 1) {return true;}}return false;}
}
代码解读:
整体代码都很简单,我相信看我上面的代码估计也知道啥意思了。有一些需要特别声明的点:
- 我新增了一个二维数组
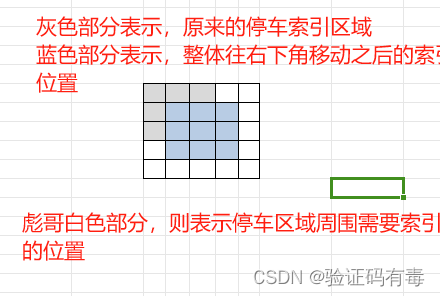
AROUND用来快速锚定当前位置的【前后左右】位置的坐标,并且为此改变了长宽条件变量MAX_COUNT的值(20 -> 20 + 1 + 1,下面我会解释为什么我要这么写) - 我在读取数据的
for循环区间是[1, m]而不是[0, m),这是为了方便索引(相当于把坐标整体往右下角移动了)。毕竟停车场边缘是坐标周围的坐标不好索引,需要做额外判断。这也是为什么,我要在MAX_COUNT = 20 + 1 + 1的原因。其中,20表示条件中说的长、宽范围;后面的1 + 1表示的语义如下:- 第一个
1:整体往右下角移动 - 第二个
1:则是为了避免过多的安全判断。使当前节点周围节点可以索引。如果没有这个的话,那么在判断停车场边缘节点(即:数组边缘)的时候,为了防止数组越界,需要做额外的安全判断
- 第一个