网站界面设计尺寸规范深圳鹏洲建设工程有限公司网站
开发插件的都知道插件的content scripts和top window只共享Dom不共享window和其他数据,如果想拿挂载在window的数据还有点难度,下面会通过事件的方式传递cs和top window之间的数据写一个例子
代码
manifest.json
这里只搞了2个js,content.js是content scripts,main.js是在top window里运行的
{"version": "0.0.1","author": "apades","name": "ext-hack","description": "","manifest_version": 3,"content_scripts": [{"matches": ["<all_urls>"],"js": ["content.js"],"run_at": "document_end","all_frames": true},{"matches": ["<all_urls>"],"js": ["main.js"],"run_at": "document_end","world": "MAIN"}]
}
content.js
async function sendExtMessage(type, data) {window.dispatchEvent(new CustomEvent('ext-req', { detail: { type, data } }))return new Promise((res) => {function handleResponse(e) {const detail = e.detailif (detail.type == type) {window.removeEventListener('ext-res', handleResponse)return res(detail.data)}}window.addEventListener('ext-res', handleResponse)})
}// 暴露到content script的window里测试
window.sendExtMessage = sendExtMessage
main.js
window.addEventListener('ext-req', async (e) => {const { type, data } = e.detailswitch (type) {case 'run-code': {let fn = new Function(`return (${data.function})(...arguments)`)let rs = await fn(...(data.args ?? []))sendExtResponse(type, rs)break}}
})function sendExtResponse(type, data) {window.dispatchEvent(new CustomEvent('ext-res', {detail: { type, data },}))
}
运行测试
首先我先在top window里随便写个window.a的值
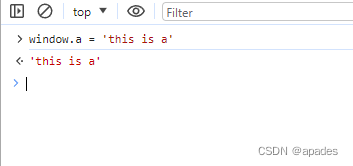
然后切换到ext-hack的window里,再测试sendExtMessage
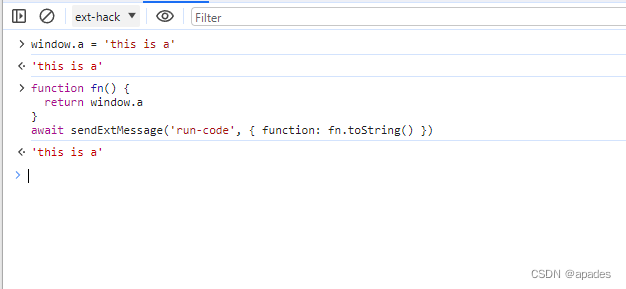
然后发现可以拿到top window的数据了;以上方法还能传入content script window里的对象参数到top window里使用,也可以传入异步方法
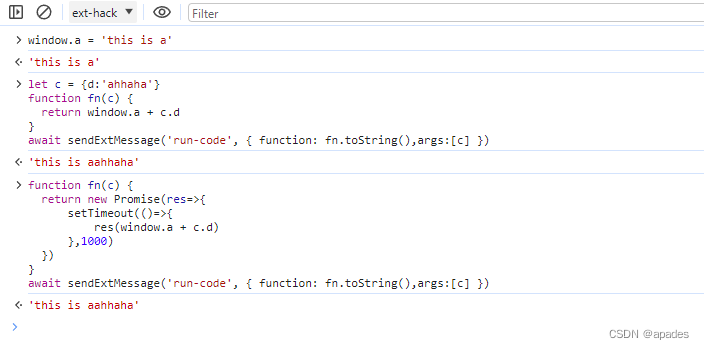
最后要说的
通过事件里互相传的数据会经过插件内部的序列化,地址、Object.defineProperty都是不共享的。而且这个方法相较于script标签插入,可以绕开doc response的Content-Security-Policy