桂林企业网站建设图片外链在线生成
本文重点
贝叶斯算法是机器学习算法中非常经典的算法,也是非常古老的一个算法,但是它至今仍然发挥着重大的作用,本节课程及其以后的专栏将会对贝叶斯算法来做一个简单的介绍。
贝叶斯公式
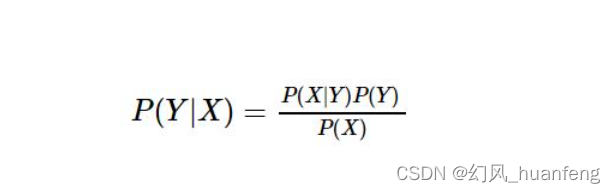
贝叶斯公式是由联合概率推导而来
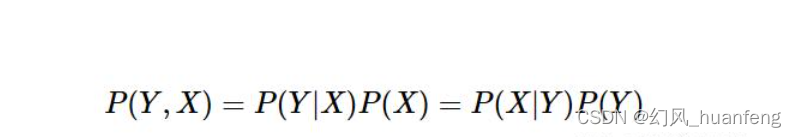
其中p(Y|X)称为后验概率,P(Y)称为先验概率,而P(Y,X)成为联合概率。一般『先验概率』、『后验概率』是相对出现的,比如P(Y)与P(Y|X)是关于Y的先验概率与后验概率,P(X)与P(X|Y)是关于X的先验概率与后验概率。
贝叶斯和机器学习
我们知道在机器学习中,Y表示样本标签,X表示样本的特征,那么我们如何将贝叶斯算法应用导机器学习中呢?

我们将X换为具有某类特征,然后Y换位属于某类,然后我们就可以将具有某特征的条件下属于某类的概率p通过