qq空间主页制作网站河北省建设项目环境官网网站
使用redux Toolkits中的createSlice编写extraReducers经常看到使用action.payload来更新state状态值:
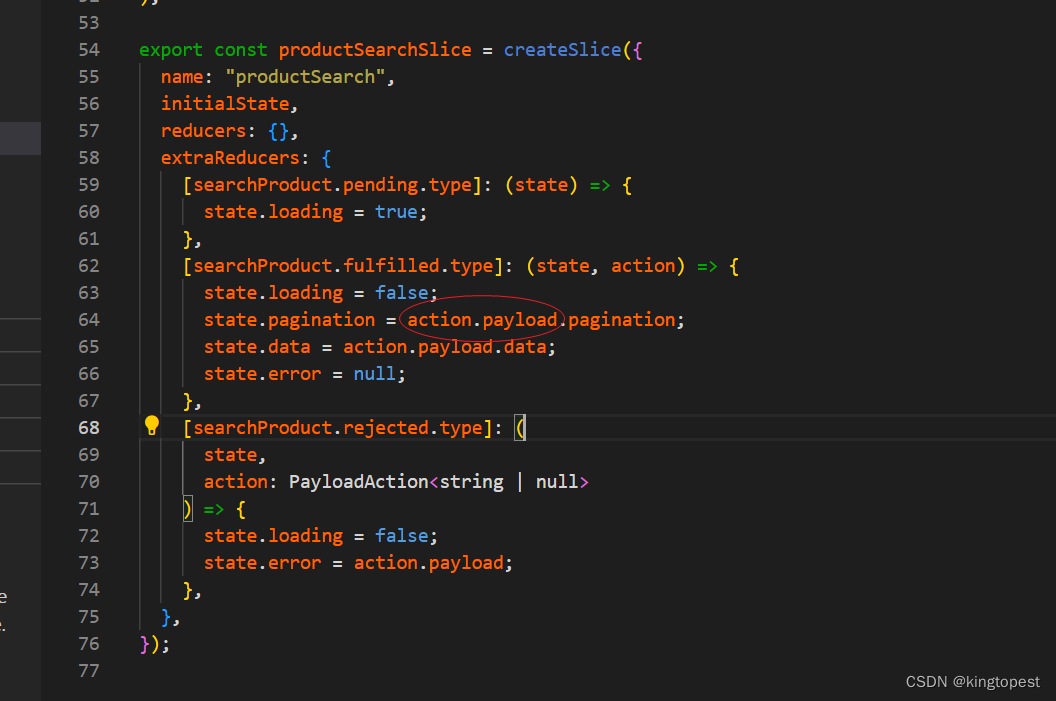
那么action.payload指的到底是什么?
让我们看看action的定义部分:
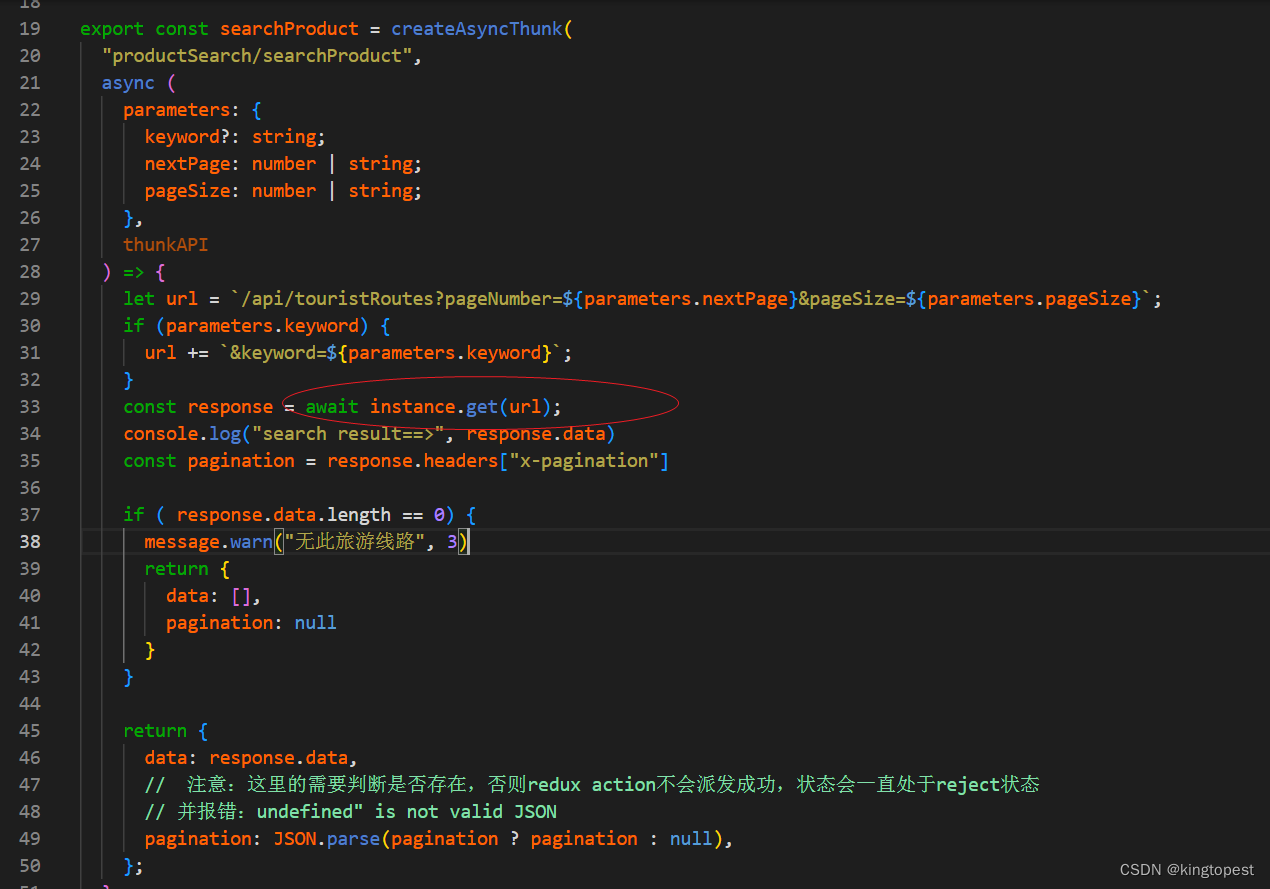
注意: action.payload不是上面ajax请求的返回内容!
action.payload是这个action重新包装后的return返回结果。
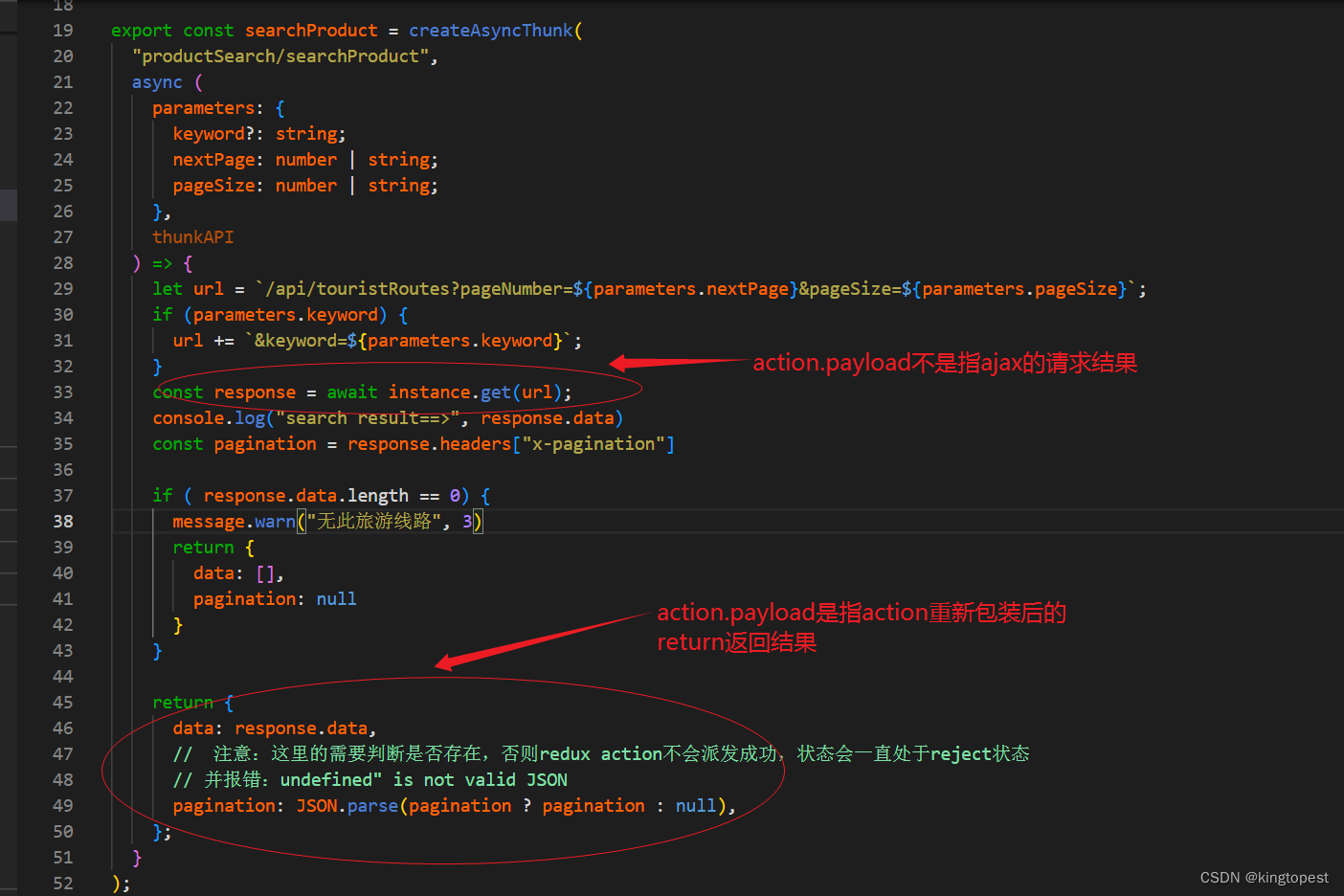
总结:action.payload 是 createAsyncThunk 函数重新包装异步操作后的返回值,而不是直接来自于 AJAX 请求的响应值。