网络公司网站推广wordpress怎么换空间

你知道什么是 Selenium 吗?你知道为什么要使用它吗?答案就在本文中,很高兴能够与你共飧。
自动化测试正席卷全球,Selenium 认证是业界最抢手的技能之一。
什么是 Selenium?
Selenium 是一种开源工具,用于在 Web 浏览器上执行自动化测试(使用任何 Web 浏览器进行 Web 应用程序测试)。
等等,先别激动,让我再次重申一下,Selenium 仅可以测试Web应用程序。我们既不能使用 Selenium 测试任何桌面(软件)应用程序,也不能测试任何移动应用程序。
这很糟糕,对吧?我能感觉到你的痛苦。但请放心,有许多工具可以测试桌面软件和移动应用程序,例如:IBM 的 RFT,HP 的 QPT,Appium 等。但是,本文的重点是测试动态 Web 应用程序,以及为什么 Selenium 在这方面是最好的。
Selenium 的优势是什么?
由于 Selenium 是开源的,因此不涉及许可费用,这是与其他测试工具相比的主要优势。Selenium 日益流行的其他原因是:

- 测试脚本可以用以下任何一种编程语言编写:Java、Python、C#、PHP、Ruby、Perl 和 .Net
- 可以在以下任何操作系统中进行测试:Windows、Mac 或 Linux
- 可以使用任何浏览器进行测试:Mozilla Firefox、Internet Explorer、Google Chrome、Safari 或 Opera
- 可以与 TestNG 和 JUnit 等工具集成,以管理测试用例和生成报告
- 可以与 Maven、Jenkins 和 Docker 集成以实现持续测试
但总有缺点吧?
- 我们只能使用 Selenium 来测试 Web 应用程序。我们无法测试桌面应用程序或任何其他软件
- 没有针对 Selenium 的保证支持。我们需要利用现有的客户社区
- 无法对图像进行测试。我们需要将 Selenium 与 Sikuli 集成以进行基于图像的测试
- 没有本机报告工具。但是我们可以通过将其与 TestNG 或 JUnit 之类的框架集成来解决该问题
首先,让我们了解 Selenium 是如何发展到今天的。所以,让我们按以下顺序来讲解:
-
- 软件测试的诉求
- 手工测试的挑战
- 自动化测试如何胜过手动测试?
- Selenium 与其他测试工具的对比?
- Selenium 套件工具
现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:110685036
软件测试的需要
一切都归结为软件测试。当今的技术世界完全由机器控制,它们的行为被驱动它的软件年控制。这些机器会完全按照我们希望的那样运行吗?每一次、任何场合都符合预期吗?这些问题的答案在于软件测试。
归根结底,软件应用程序的成功率将控制你的业务增长。即使对于 Web 应用程序,也可以说同样的话,因为当今大多数企业都完全依赖 Internet。
以任何一家电子商务公司为例。无论是 Amazon 还是 E-Bay 或 Flipkart,他们都依赖其网站上的客户流量以及基于 Web 的移动应用程序上的业务流量。
想象一下,如果发生灾难性事件,例如将许多产品的价格限制在 10 美元以内,这都是由于代码“不那么容易理解”部分中的一个小错误所致。那该怎么办,我们下次如何预防呢?
部署之前测试代码,对吗? 所以,这就是软件测试的需要。但是,Selenium 是什么?它是软件测试工具吗?好吧,Selenium 是一种自动化测试工具!
进一步之前,请让我澄清一下,软件测试有两种类型:手动测试和自动化测试。Selenium 作为一种自动化测试工具被创建,旨在克服手动测试的弊端/局限性。因此,接下来,让我们了解手动测试的挑战。
手动测试的挑战
手动测试是指 QA 测试人员手动测试(Web)应用程序。需要在每个环境中使用不同的数据集手动执行测试,并且应记录每个事务的成功/失败率。

看看上图中这个糟糕的小伙子,他要手动验证记录的交易。他正面临的挑战会导致疲劳、无聊、工作延迟、错误和失误(由于手动操作)。这导致了 Selenium(自动化测试工具)的发明。
自动化测试胜过手动测试
每次自动化测试都胜过手动测试。为什么?因为它速度更快,需要的人力资源投资较少,所以不容易出错,可以频繁执行测试,支持无人值守执行,支持回归测试以及功能测试。
让我们举一个与前面提到的类似的例子。假设有一个登录页面,我们需要验证所有的登录尝试是否成功,那么很容易编写一段代码来验证所有的事务/登录尝试是否成功(自动测试用例执行)。
此外,可以以在不同环境和 Web 浏览器中对它们进行测试的方式配置这些测试。我们还能做些什么?您可以通过安排一天中的特定时间来自动生成结果文件。然后,您还可以根据这些结果自动生成报告。
关键是自动化测试使测试人员的工作变得更加简单。如下图所示,显示了一个更宽松的环境,同样的测试人员正在工作。

现在,让我特别谈谈 Selenium。
现在让我们看看 Selenium 在市场上的地位。
Selenium 对比 QTP 和 RFT
我在下表中将其性能与其他两个流行工具进行了比较:QTP和RFT。
| 特性 | HP QTP | IBM RFT | Selenium |
| 授权 | 需要 | 需要 | 开源 |
| 费用 | 高 | 高 | 开源软件 |
| 客户支持 | HP 专有支持 | IBM 专有支持 | 开源社区 |
| 脚本执行期间的硬件消耗 | 高 | 高 | 低 |
| 编码经验 | 不需要 | 需要 | 需要足够的编码技巧和经验 |
| 环境支持 | 仅支持 Windows | 仅支持 Windows | Windows,Linux,Solaris OS X(如果存在浏览器和 JVM或 JavaScript 支持) |
| 语言支持 | VB Script | Java 和 C# | Java、C#、Ruby、Python、Perl、PHP 和 JavaScript |
从上表可以很清楚地看出 Selenium 是最受青睐的工具。但是 Selenium 中有很多不同的风格,您应该知道哪种 Selenium 工具最适合你的需要。
Selenium 工具套件
- Selenium RC (现在已废弃)
- Selenium IDE
- Selenium Grid
- Selenium WebDriver
Selenium 有哪些组件?
下面我详细解释了 Selenium 的各个组成:
Selenium RC (远程控制)
在谈论 Selenium RC 的细节之前,我想回过头来谈谈 Selenium 项目中的第一个工具。Selenium Core 是第一个工具。但是,由于采用了同源策略,Selenium Core 在跨域测试方面遇到了障碍。同源策略禁止 JavaScript 代码访问与启动 JavaScript 的位置不同的域上托管的 Web 元素。
为了克服同源策略问题,测试人员需要安装 Selenium Core(JavaScript程序)和包含要测试的 Web 应用程序的 Web 服务器的本地副本,以便它们属于同一域。这导致了 Selenium RC 的诞生,这是当时 ThoughtWork 的工程师 Paul Hammant 认可的。
RC 通过使用 HTTP 代理服务器来“欺骗”浏览器,使其相信 Selenium Core 和被测试的 Web 应用程序来自同一域,从而解决了该问题。因此,使 RC 成为双组件工具。
- Selenium RC 服务器
- Selenium RC 客户端 – 包含编程语言代码的库
RC Server 使用简单的 HTTP GET / POST 请求进行通信。查看下图以了解 RC 架构。

Selenium 项目的旗舰工具是 Selenium RC,这是他们的第一个工具,可以用来以不同的编程语言编写测试用例。但是 RC 的缺点是与 RC 服务器的每次通信都很耗时,因此RC非常慢。太慢了,有时一次测试要花上几个小时。
从 Selenium v3 开始,RC 已弃用,并转移到遗留软件包中。您依然可以下载并使用 RC,但是很遗憾,已经无法得到支持。但另一方面,为什么要使用一个过时的工具,尤其是当有一个更有效的工具 Selenium WebDriver 时。在谈论WebDriver之前,让我讨论一下IDE 和 Grid,它们是构成 Selenium v1 的其他工具。
Selenium IDE(集成开发环境)
2006年,日本的 Shinya Kastani 将他的 Selenium IDE 原型捐赠给了 Apache 的 Selenium 项目。这是一个用于快速创建测试用例的 Firefox 插件。IDE 实施了记录和回放模型,其中通过记录用户与 Web 浏览器的交互来创建测试用例。这些测试然后可以播放任意次。
Selenium IDE 的优势在于,通过插件记录的测试可以以不同的编程语言导出,例如:Java、Ruby、Python 等。请查看以下 Firefox IDE 插件的屏幕截图。
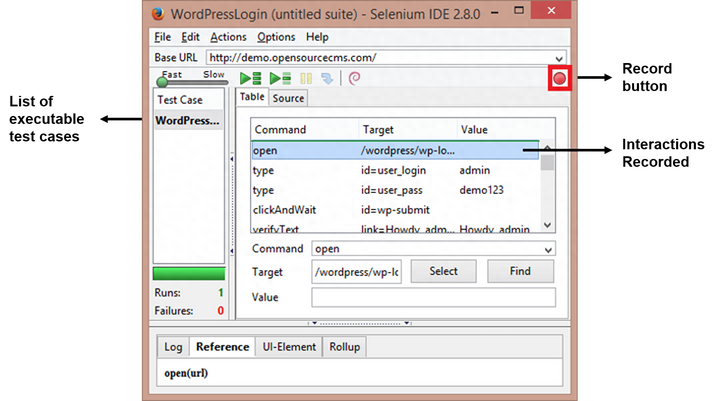
但是,IDE的相关缺点是:
- 插件仅适用于 Mozilla Firefox;不适用于其他浏览器
- 无法测试动态 Web 应用程序。只能记录简单的测试
- 测试用例不能使用编程逻辑编写脚本
- 不支持数据驱动测试
这些是 Selenium IDE 的一些方面。现在让我谈谈 Selenium Grid。
什么是 Selenium Grid
Selenium Grid 由 Patrick Lightbody 开发,最初称为 HostedQA(最初是 Selenium v1 的一部分),它与 RC 结合使用以在远程计算机上运行测试。实际上,使用 Grid 可以在多台计算机上同时执行多个测试脚本。
借助 Hub-Node 架构实现并行执行。一台机器将承担集线器的角色,其他机器将充当节点。集线器控制在各种操作系统内的各种浏览器上运行的测试脚本。在不同节点上执行的测试脚本可以用不同的编程语言编写。
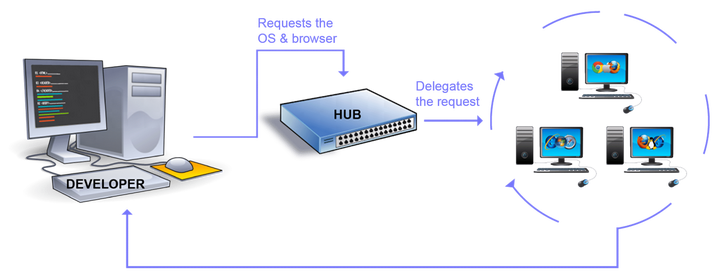
Grid 仍在使用,并且可以与 WebDriver 和 RC 一起使用。但是,使用所有必需的浏览器和操作系统维护网格是一个挑战。为此,有多个在线平台可提供在线 Selenium Grid,您可以访问它们以运行 Selenium 自动化脚本。例如,您可以使用 LambdaTest。它具有2000 多种浏览器环境,您可以在这些环境中运行测试,并真正实现跨浏览器测试的自动化。
什么是 Selenium WebDriver
Selenium WebDriver 由 Simon Stewart 于 2006 年创立,它是第一个可以从操作系统级别控制浏览器的跨平台测试框架。与 IDE 相比,Selenium WebDriver 提供了一个编程接口来创建和执行测试用例。编写测试用例,以便识别网页上的 Web 元素,然后对这些元素执行操作。
WebDriver 是 RC 的升级,因为它速度更快。它更快,因为它可以直接调用浏览器。另一方面,RC 需要 RC 服务器与 Web 浏览器进行交互。每个浏览器都有自己的驱动程序,应用程序可以在该驱动程序上运行。不同的 WebDrivers 是:
- Firefox Driver (Gecko Driver)
- Chrome Driver
- Internet Explorer Driver
- Opera Driver
- Safari Driver and
- HTM Unit Driver
Selenium WebDriver 的好处
- 支持 7 种编程语言:JAVA、C#、PHP、Ruby、Perl、Python 和 .Net
- 支持在不同浏览器进行测试,如:Firefox、Chrome、IE、Safari
- 支持在不同操作系统上执行测试,如:Windows、Mac、Linux、Android、iOS
- 克服了 Selenium v1 的局限性,例如文件上传、下载、弹出窗口和对话栏
Selenium WebDriver 的缺点
- 无法生成详细的测试报告
- 无法测试图像
不管紧致什么挑战,这些缺点都可以通过与其他框架集成来克服。对于测试图像,可以使用 Sikuli,对于生成详细的测试报告,可以使用 TestNG。
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走!
软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。