长沙高校网站制作公司网站开发项目管理文档模板
文章目录
- (1)创建如下工程文件夹:其中头文件放在include文件夹中,源文件放在src文件夹中
- (2)在vscode上打开工程文件夹,在对应的文件夹内建立相应的文件
- 1)目录结构
- 2)各文件内容
- (3)编写CMakeLists.txt文件
- 方法一:使用前一个博客的方法自动生成CMakeLists.txt文件后修改(这种方法会自动生成build文件夹)
- 1)使用CMake:Quick Start等命令并配置好kit(具体步骤参考上一篇博客)
- 2)修改CMakeLists.txt文件内容为如下
- 方法二:直接在工程目录下创建CMakeLists.txt文件(注意需要配置好kit)
- 1)创建CMakeLists.txt文件
- 2)配置build文件夹等
- 法一:这个时候vscode下面的状态栏没有显示kit工具的,所以此时应该(Ctrl+Shift+P)选择cmake:configure运行之后便显示了build
- 法二:在终端上使用命令创建相应的目录
- (4)编译工程
- (5)验证文件,此时生成的可执行文件可有如下信息
(1)创建如下工程文件夹:其中头文件放在include文件夹中,源文件放在src文件夹中
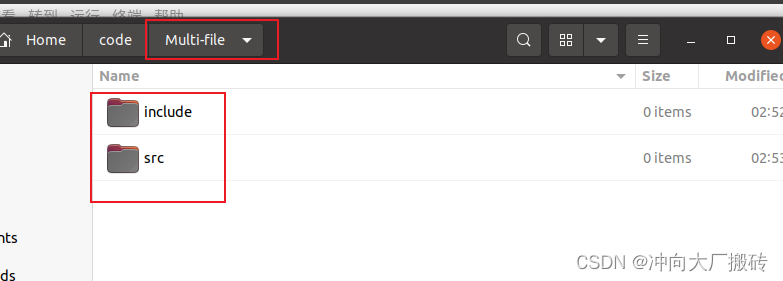
(2)在vscode上打开工程文件夹,在对应的文件夹内建立相应的文件
1)目录结构

2)各文件内容
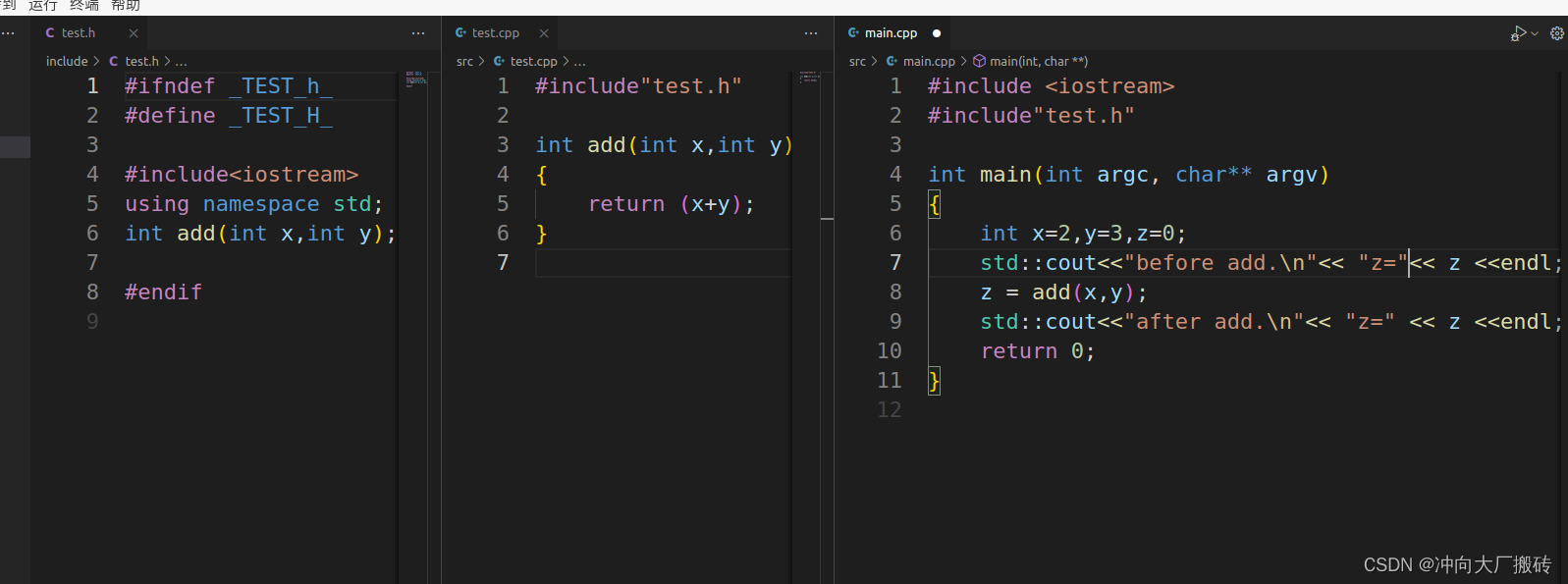
(3)编写CMakeLists.txt文件
这时候有两种方法可以实现
方法一:使用前一个博客的方法自动生成CMakeLists.txt文件后修改(这种方法会自动生成build文件夹)
1)使用CMake:Quick Start等命令并配置好kit(具体步骤参考上一篇博客)
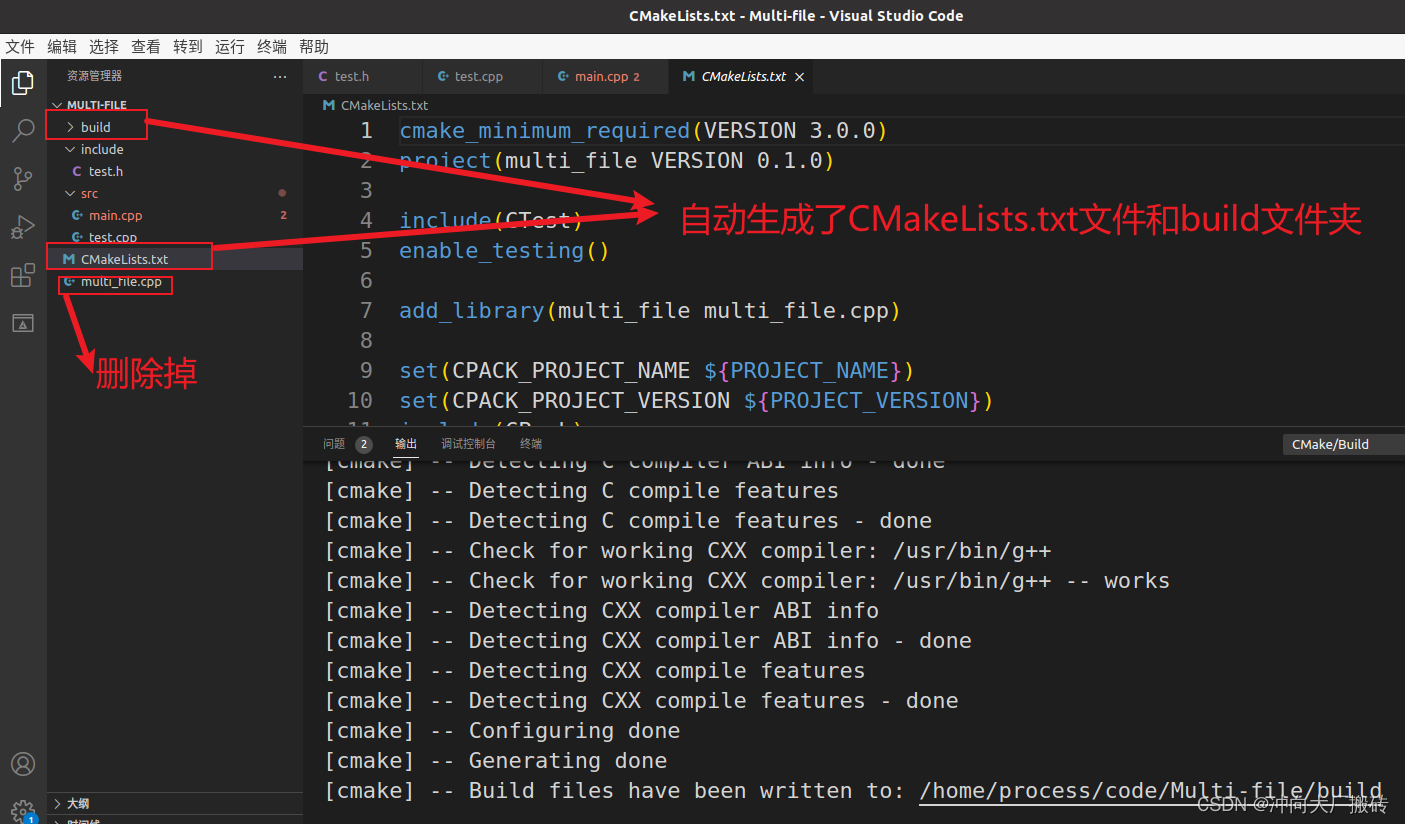
2)修改CMakeLists.txt文件内容为如下
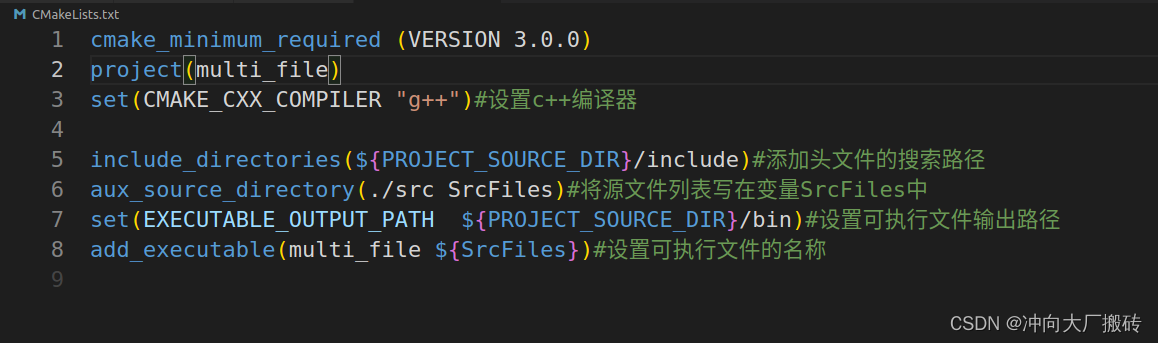
方法二:直接在工程目录下创建CMakeLists.txt文件(注意需要配置好kit)
1)创建CMakeLists.txt文件
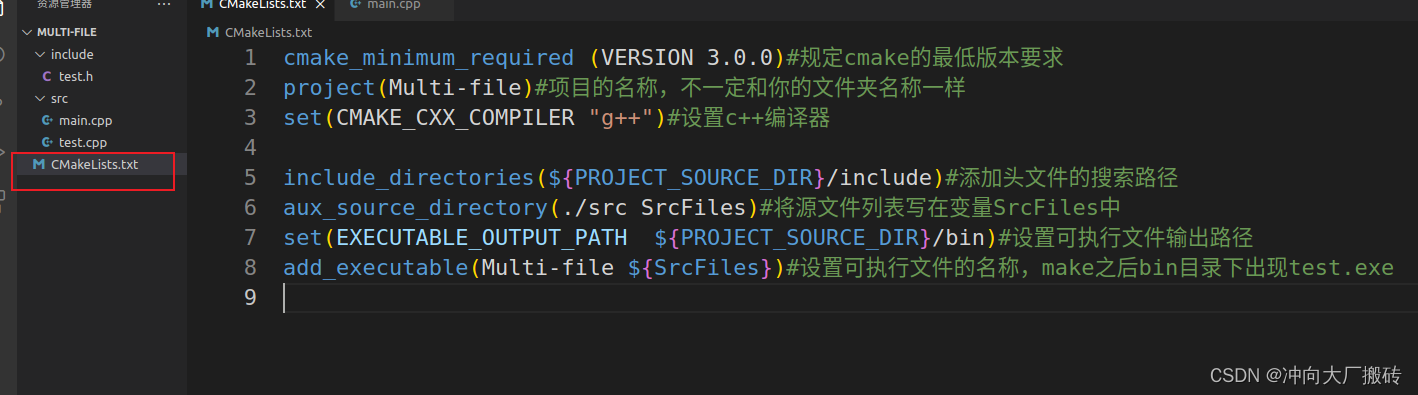
2)配置build文件夹等
这时候也有两种方法选择
法一:这个时候vscode下面的状态栏没有显示kit工具的,所以此时应该(Ctrl+Shift+P)选择cmake:configure运行之后便显示了build
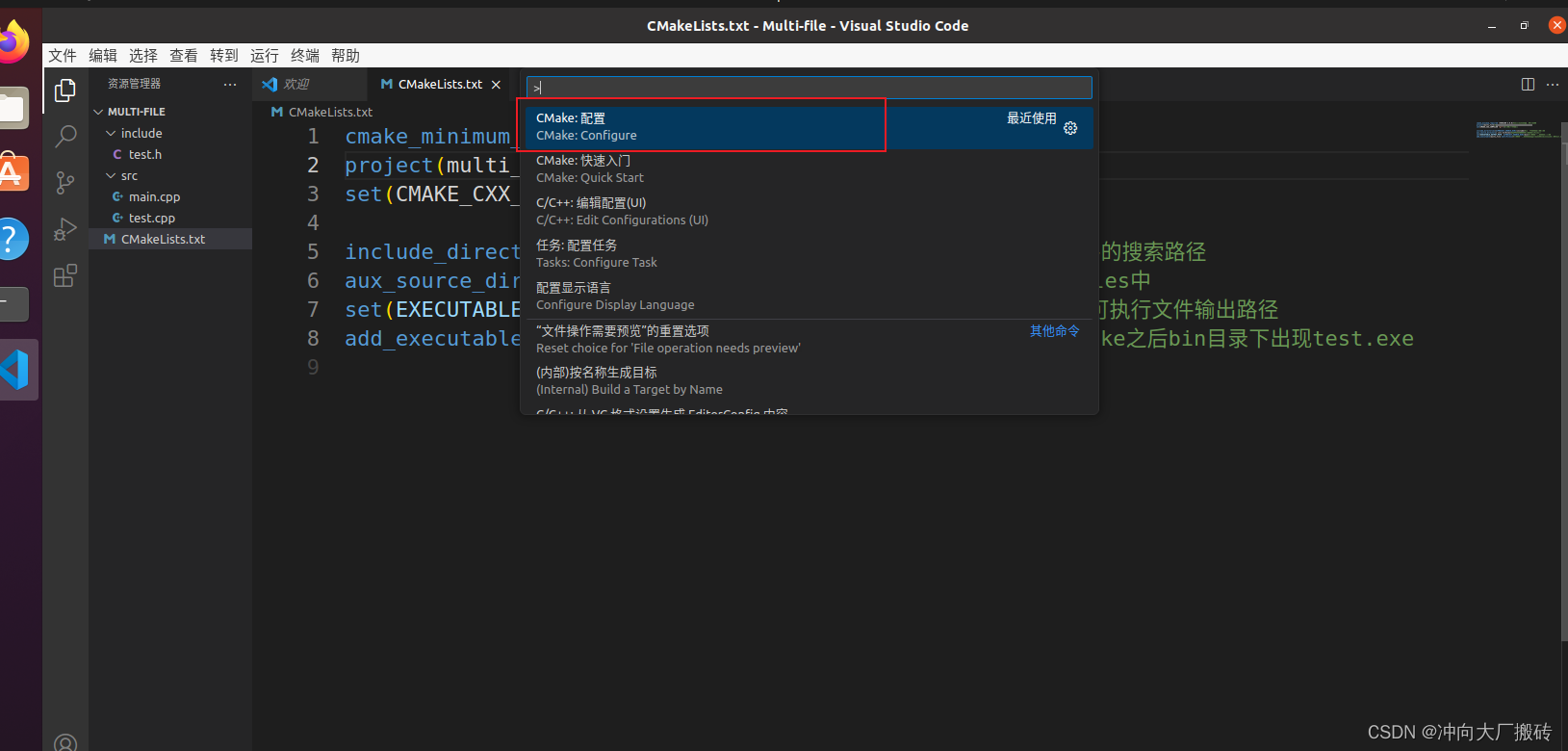
法二:在终端上使用命令创建相应的目录
a)打开终端(Ctrl+Shift+`),依次执行如下命令

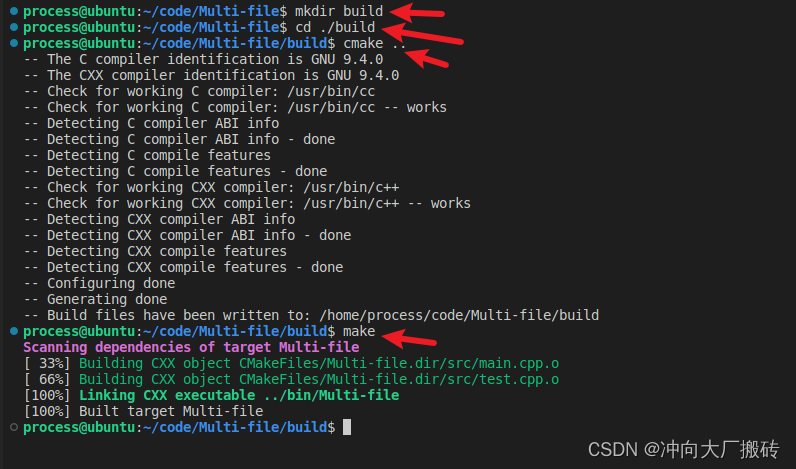
b)执行完之后就编译成功了(但是这个时候vscode下面的状态栏没有显示kit工具的,所以此时应该(Ctrl+Shift+P)选择cmake:configure运行之后便显示了build)
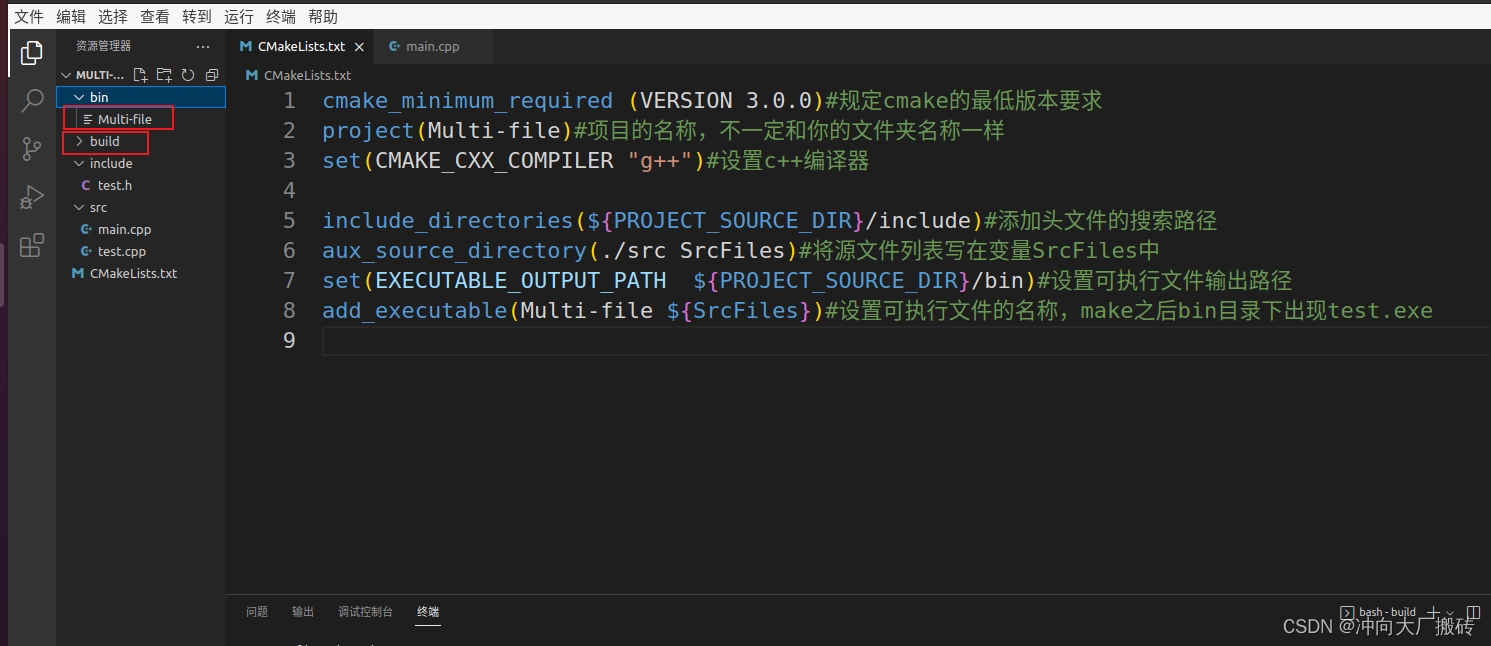
(4)编译工程
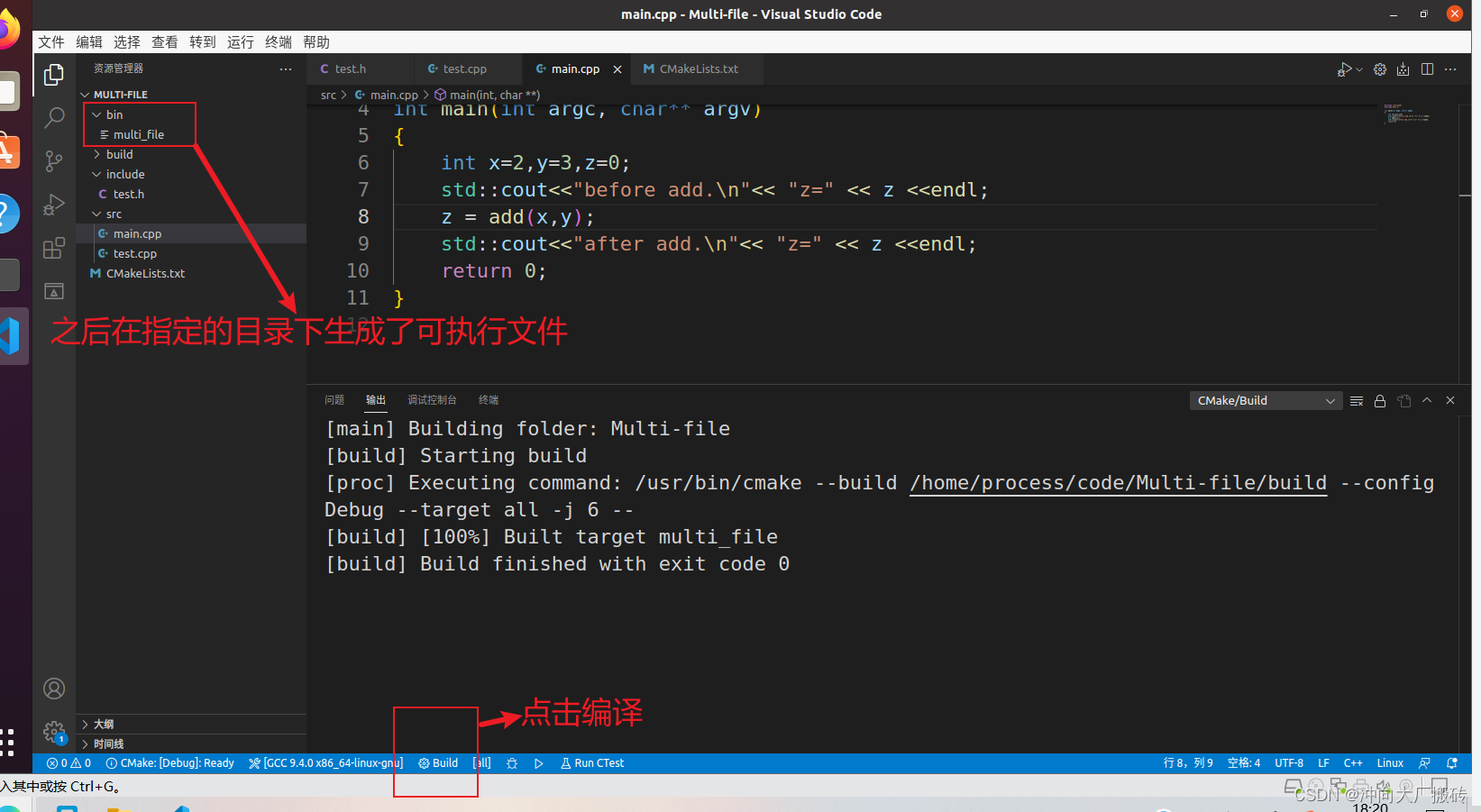
(5)验证文件,此时生成的可执行文件可有如下信息
