网站代理网址有限公司属于什么企业类型
目录
文件的读取
open()打开函数
read类型
read()方法
readlines()方法
readline()方法
for循环读取文件行
close() 关闭文件对象
with open 语法
文件的写入
文件的追加
文件的读取
| 操作 | 功能 |
| 文件对象 = open(file, mode, encoding) | 打开文件获得文件对象 |
| 文件对象.read(num) | 读取指定长度字节 不指定num读取文件全部 |
| 文件对象.readline() | 读取一行 |
| 文件对象.readlines() | 读取全部行,得到列表 |
| for line in 文件对象 | for循环文件行,一次循环得到一行数据 |
| 文件对象.close() | 关闭文件对象 |
| with open() as f | 通过with open语法打开文件,可以自动关闭 |
open()打开函数
open(name, mode, encoding)
- name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
- mode:设置打开文件的模式(访问模式):只读(r)、写入(w)、追加(a)等。
- encoding:编码格式(推荐使用UTF-8)
方法如下:
f = open("A:/1223.txt", "r", encoding="UTF-8")
print(type(f))<class '_io.TextIOWrapper'>
补充:
| 模式 | 描述 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被删除。 如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有内容之后。 如果该文件不存在,创建新文件进行写入。 |
read类型
read类型函数读取文件时会有默认的指针下标指向开始位置,指针随着读取数据的单位移动;当对同一个文件调用多次read类型函数,读取开始位置为上一个函数读取结束的位置。
也就是说,read类型函数会默认对文件读取进度记录,如果第一次读了10个字节的内容,那么第二次调用则从第11个字节的位置开始读取;
测试
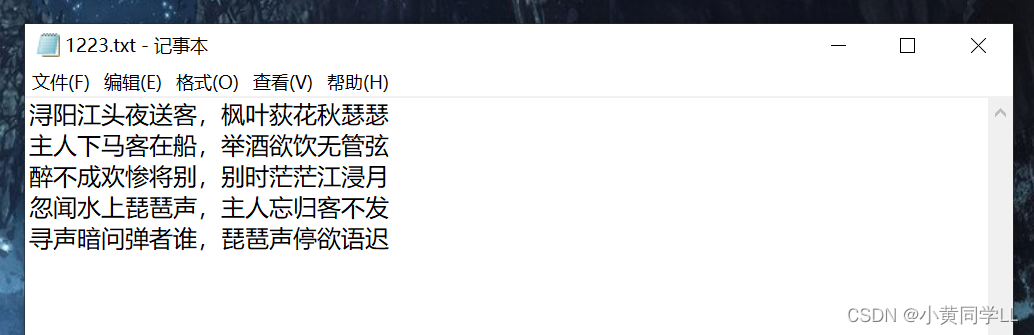
将如上图内容的文件存入A盘
read()方法
文件对象.read(num)
num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据
f = open("A:/1223.txt", "r", encoding="UTF-8")
# 读取文件 - read()
print(f"第一次读取16个字节的结果:{f.read(16)}")
print(f"第二次读取16个字节的结果:{f.read(16)}")
print(f"第三次读取16个字节的结果:{f.read(16)}")
print(f"read方法读取全部内容的结果是:\n{f.read()}")
print("-----------------------------------------------")第一次读取16个字节的结果:浔阳江头夜送客,枫叶荻花秋瑟瑟
第二次读取16个字节的结果:主人下马客在船,举酒欲饮无管弦
第三次读取16个字节的结果:醉不成欢惨将别,别时茫茫江浸月
read方法读取全部内容的结果是:
忽闻水上琵琶声,主人忘归客不发
寻声暗问弹者谁,琵琶声停欲语迟
-----------------------------------------------
readlines()方法
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
# 读取文件 - readLines()
lines = f.readlines() # 读取文件的全部行,封装到列表中
print(f"lines对象的类型:{type(lines)}")
print(f"lines对象的内容是:{lines}")lines对象的类型:<class 'list'>
lines对象的内容是:['浔阳江头夜送客,枫叶荻花秋瑟瑟\n', '主人下马客在船,举酒欲饮无管弦\n', '醉不成欢惨将别,别时茫茫江浸月\n', '忽闻水上琵琶声,主人忘归客不发\n', '寻声暗问弹者谁,琵琶声停欲语迟\n']
readline()方法
一次读取一行内容
# 读取文件 - readline()
line1 = f.readline()
line2 = f.readline()
line3 = f.readline()
print(f"第一行数据是:{line1}")
print(f"第二行数据是:{line2}")
print(f"第三行数据是:{line3}")第一行数据是:浔阳江头夜送客,枫叶荻花秋瑟瑟
第二行数据是:主人下马客在船,举酒欲饮无管弦
第三行数据是:醉不成欢惨将别,别时茫茫江浸月
for循环读取文件行
遇到转行符则执行语句
语句转换为字符串类型<class 'str'>
# for循环读取文件行
for line in f:print(f"每一行数据是:{line}")每一行数据是:浔阳江头夜送客,枫叶荻花秋瑟瑟
每一行数据是:主人下马客在船,举酒欲饮无管弦
每一行数据是:醉不成欢惨将别,别时茫茫江浸月
每一行数据是:忽闻水上琵琶声,主人忘归客不发
每一行数据是:寻声暗问弹者谁,琵琶声停欲语迟
close() 关闭文件对象
最后通过close,关闭文件对象,也就是关闭对文件的占用
如果不调用close,同时程序没有停止运行,那么这个文件将一直被Python程序占用。
f = open("python.txt", "r")f.close()
with open 语法
通过在with open的语句块中对文件进行操作
可以在操作完成后自动关闭close文件,避免遗忘掉close方法
with open("python.txt", "r") as f:f.readlines()
文件的写入
注意:
- 直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
- 当调用flush的时候,内容会真正写入文件
- 这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
文件如果不存在,使用”w”模式,会创建新文件
f = open("A:/666.txt", "w", encoding="UTF-8")
# # write写入
f.write("Hello World!!!") # 内容写入到内存中
# # flush刷新
f.flush() # 将内存中积攒的内容,写入到硬盘的文件中
# # close关闭
f.close() # close方法,内置了flush的功能的文件如果存在,使用”w”模式,会将原有内容清空
# # 打开一个存在的文件
f = open("A:/666.txt", "w", encoding="UTF-8")
# write写入、flush刷新
f.write("雷猴")
# close关闭
f.close()文件的追加
注意:
a模式,文件不存在会创建文件
# 打开文件,不存在的文件
f = open("A:/777.txt", "a", encoding="UTF-8")
# write写入
f.write("嘿嘿嘿")
# flush刷新
f.flush()
# close关闭
f.close()A盘出现777.txt文件

a模式,文件存在会在最后,追加写入文件
# 打开一个存在的文件
f = open("A:/777.txt", "a", encoding="UTF-8")
# write写入、flush刷新
f.write("\n嘻嘻嘻")
# close关闭
f.close()
